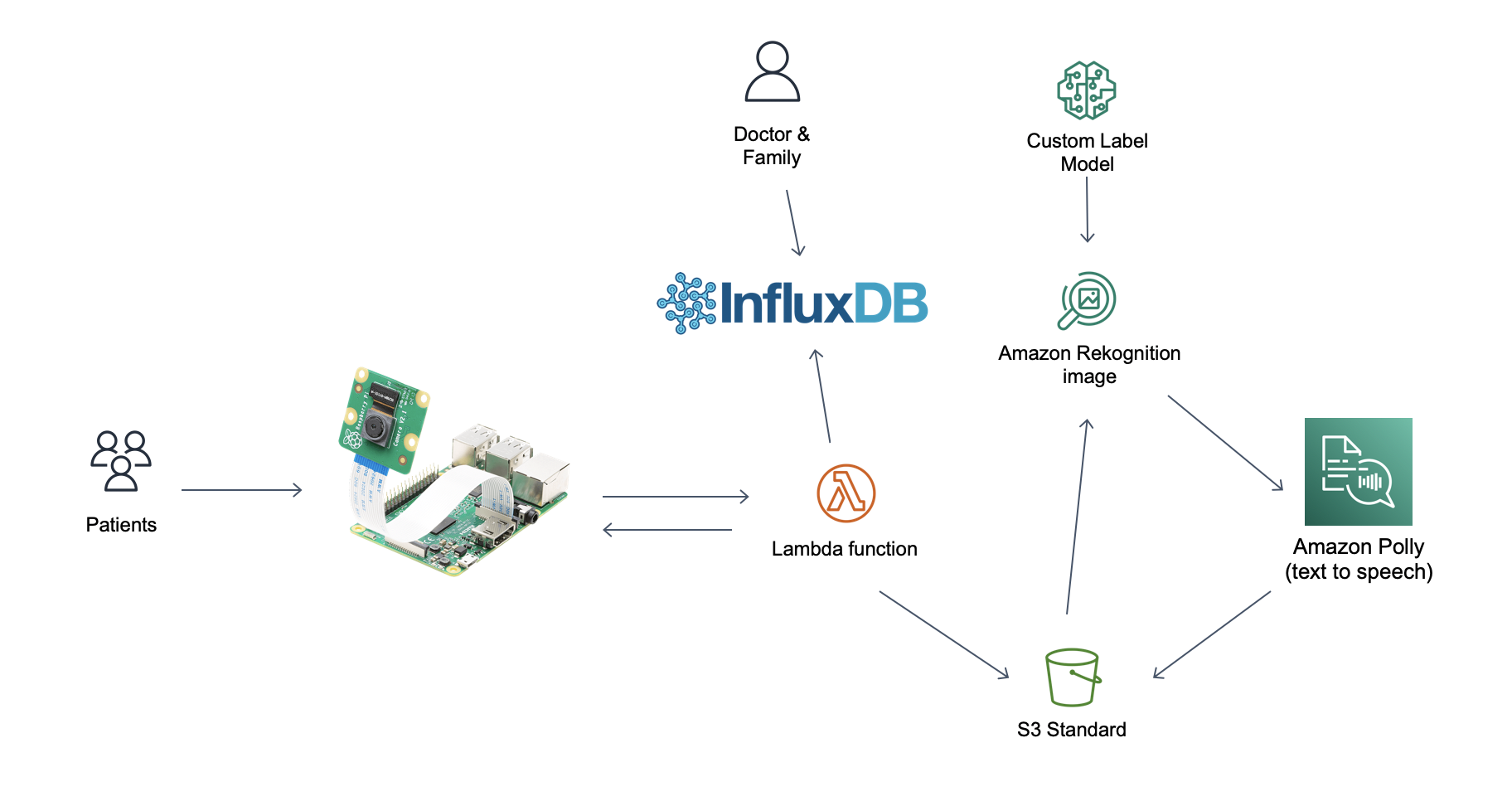
This repo is a project submission for HackDFW 2022. The backend architecture is comprised of a single AWS Lambda function written in Python that calls Amazon Rekognition service to label an image, then calls Amazon Polly to convert the detected labels to speach (saved as an MP3 file on S3), logs the event to InfluxDB Cloud (for easy visualizations) and returns the resulting MP3 file to the caller.

AWS Lambda
- Set Timeout to 6+ seconds
- Python v3.8
- Add IAM permission policies
- AmazonS3FullAccess
- AmazonPollyFullAccess
- AmazonRekognitionFullAccess
- Environment variables
- INFLUXDB_BUCKET - InfluxDB database bucket name
- INFLUXDB_ORG - InfluxDB organization
- INFLUXDB_TOKEN - InfluxDB auth token Rekognition model
- INFLUXDB_URL - InfluxDB endpoint
- MODEL_ARN - ARN of the custom
- S3_BUCKET - location to save files
- S3_REGION - S3 bucket and custom model must be in the same AWS region
- Custom layer for the InfluxDB client library
mkdir pythonpip install influxdb-client -t pythonzip -r influx.zip python
Rekogition model must be started before invocing the the lambda function:
aws rekognition start-project-version \ --project-version-arn "arn:aws:rekognition:us-east-2:312318060469:project/logos_1/version/logos_1.2022-09-24T16.48.44/1664056124159" \ --min-inference-units 1 \ --region us-east-2
To stop the custom model:
aws rekognition stop-project-version \ --project-version-arn "arn:aws:rekognition:us-east-2:312318060469:project/logos_1/version/logos_1.2022-09-24T16.48.44/1664056124159" \ --region us-east-2
Run pi_client.py on the Pasberry PI device with camera attached.