Reasoning3D - Grounding and Reasoning in 3D: Fine-Grained Zero-Shot Open-Vocabulary 3D Reasoning Part Segmentation via Large Vision-Language Models
Tianrun Chen, Chun'an Yu, Jing Li, Jianqi Zhang, Lanyun Zhu, Deyi Ji, Yong Zhang, Ying Zang, Zejian Li, Lingyun Sun
KOKONI, Moxin Technology (Huzhou) Co., LTD , Zhejiang University, Singapore University of Technology and Design, Huzhou University, University of Science and Technology of China.
-
git clone this repository :D
-
Create Environment
conda activate 3Dreaso
- Install necessary packages
pip install kaolin==0.15.0 -f https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-1.13.1_cu117.html
pip install flash-attn --no-build-isolation
pip install -r requirements.txt
pip install -e .
-
Add your customized data in input/ folder
-
Download thie weights in pre_model/ https://huggingface.co/xinlai/LISA-13B-llama2-v0-explanatory
-
run main.py. You will see a user interface like this. Have fun!
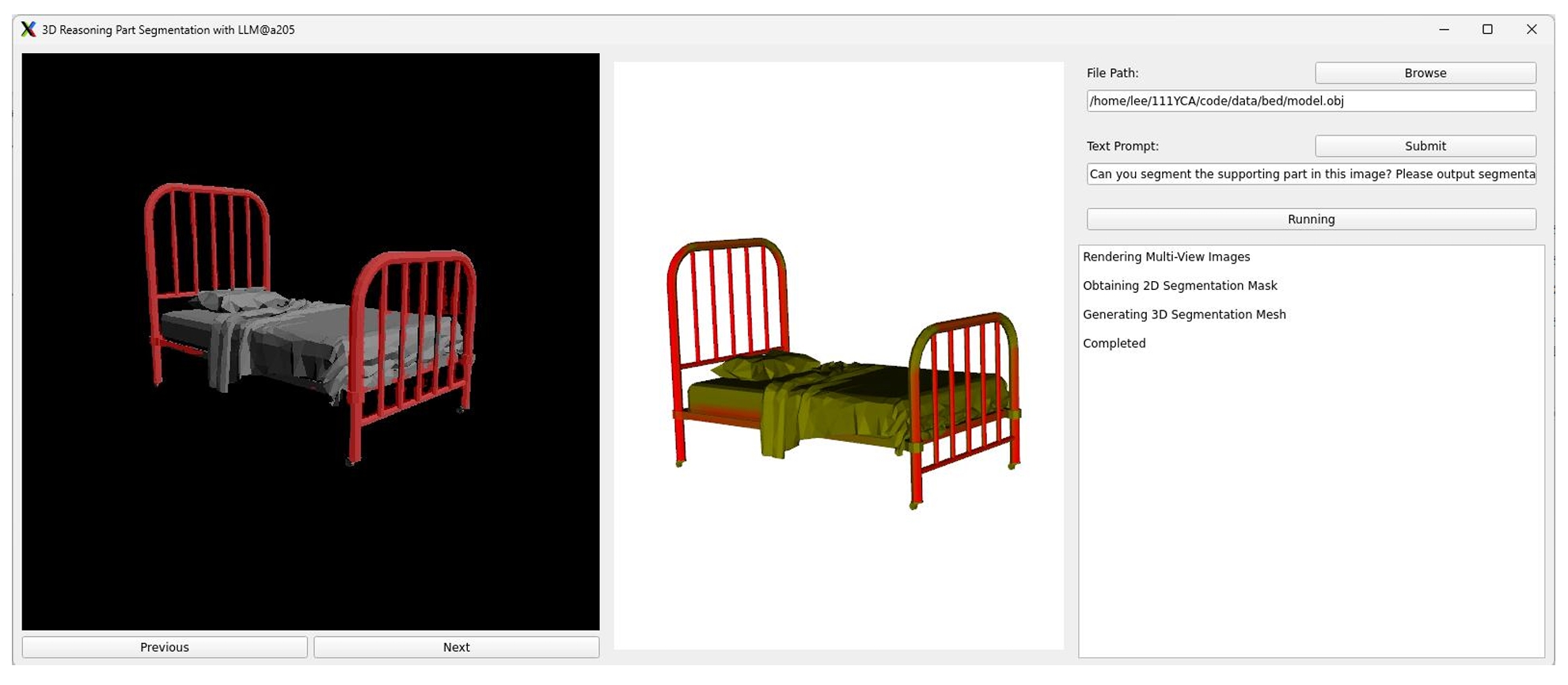
Note: The model use LISA: Reasoning Segmentation via Large Language Model as the backbone model. The model performance is heavily affected by the prompt choice. Refer to the LISA for more details about choosing the proper prompt. You can also use other base models for better performance.
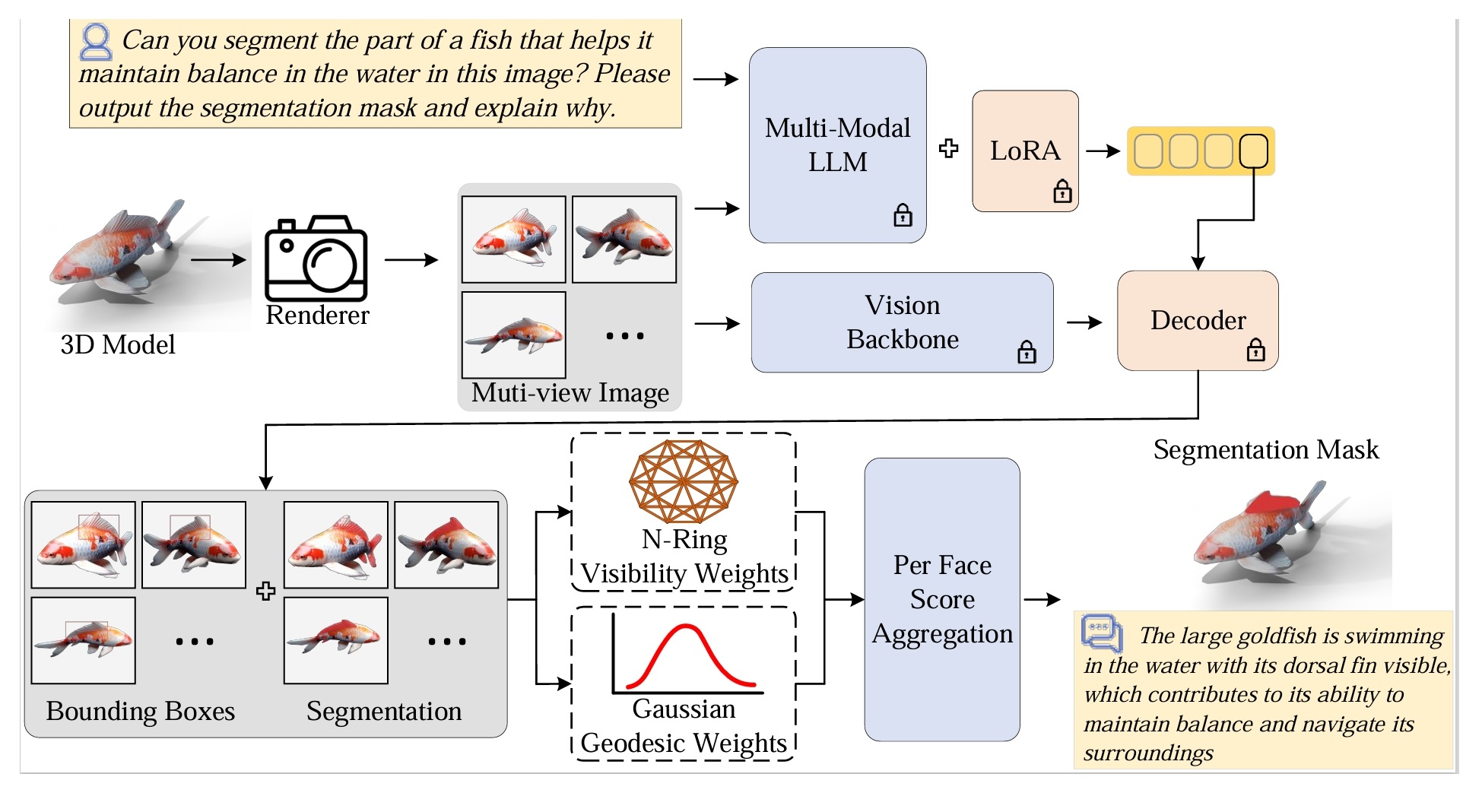
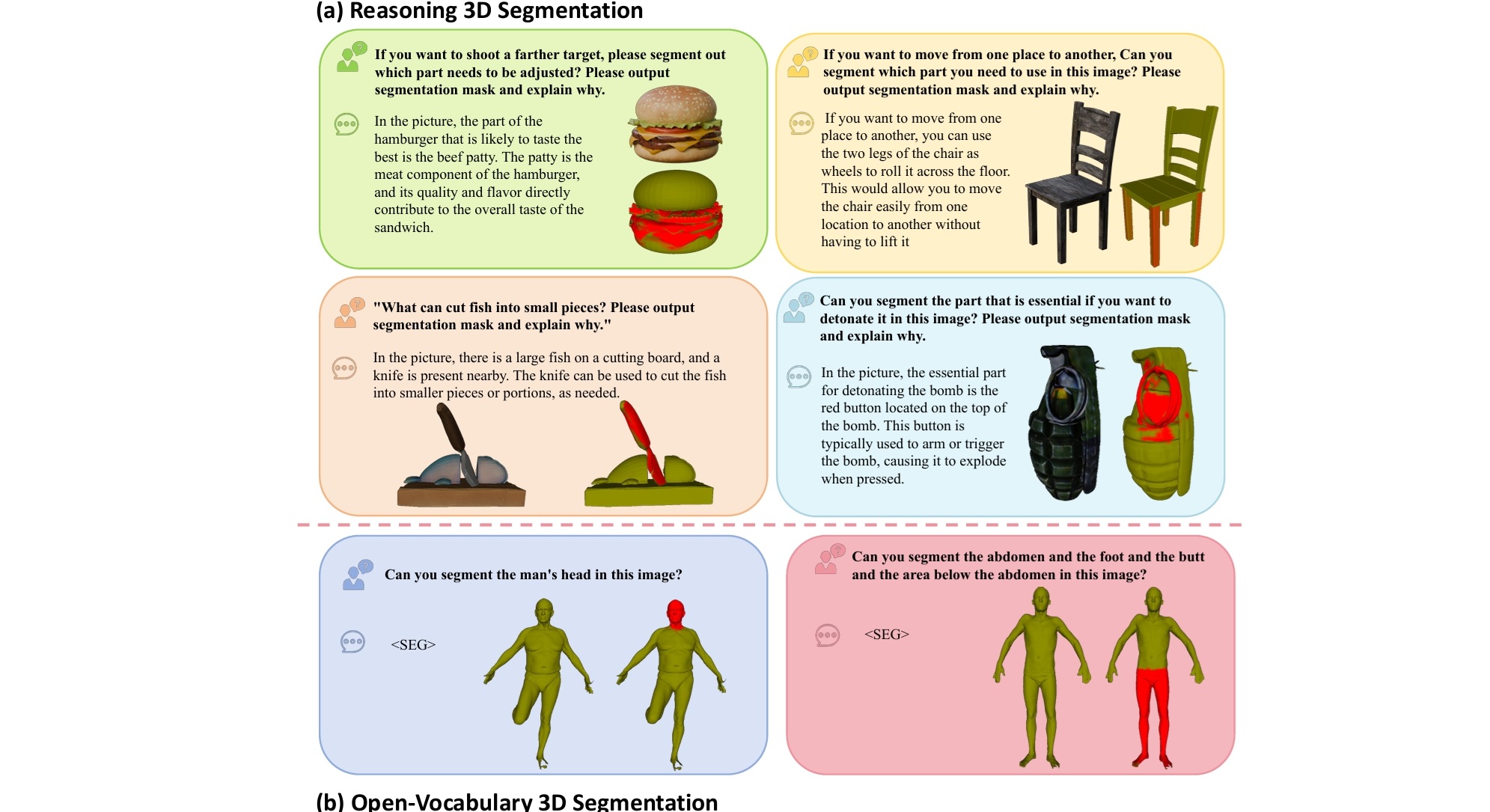
For our reasoning 3D segmentation data, you can play with your own interested models. We collect models from Sketchfab. https://sketchfab.com/
For FAUST dataset we use as the benchmark (for open-vocabulary segmentation), click this line to download the FAUST dataset, and put it in input/ https://drive.google.com/drive/folders/1T5reNd6GqRfQRyhw8lmhQwCVWLcCOZVN/
(Explict Prompting)
For one FAUST data on the coarse segmentation:(tr_scan_000 example):
1. mesh render image
bash FAUST/gen_rander_img.sh
Note: You can change pose.txt to what you want or change -frontview_center
2. image get mask
bash FAUST/gen_mask.sh
3. image and mask gen seg mesh
bash FAUST/gen_Seg_mesh.sh
Note: You need to change the category information in the .sh file manually
For other data segmentation:
1. mesh render image
bash scripts/gen_rander_img.sh
2. image get mask
bash scripts/gen_mask.sh
3. image and mask gen seg mesh
bash scripts/gen_Seg_mesh.sh
Given an output dir containing the coarse predictions for the len(mesh_name.txt) scans. run coarse as following:
python scripts/evaluate_faust.py -output_dir outputs/coarse_output_diror for the fine_grained:
python scripts/evaluate_faust.py --fine_grained -output_dir outputs/fine_grained_output_dirPlease cite this work if you find it inspiring or helpful!
@article{chen2024reason3D,
title={Reasoning3D - Grounding and Reasoning in 3D: Fine-Grained Zero-Shot Open-Vocabulary 3D Reasoning Part Segmentation via Large Vision-Language Models },
author={Chen, Tianrun and Yu, Chuan and Li, Jing and Jianqi, Zhang and Ji, Deyi and Ye, Jieping and Liu, Jun},
journal={arXiv preprint arXiv:2405.19326},
year={2024}
}
You are also welcomed to check our CVPR2024 paper using LLM to perform 2D few-shot image segmentation.
@article{zhu2023llafs,
title={Llafs: When large-language models meet few-shot segmentation},
author={Zhu, Lanyun and Chen, Tianrun and Ji, Deyi and Ye, Jieping and Liu, Jun},
journal={arXiv preprint arXiv:2311.16926},
year={2023}
}
and our Segment Anything Adapter (SAM-Adapter)
@misc{chen2023sam,
title={SAM Fails to Segment Anything? -- SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, and More},
author={Tianrun Chen and Lanyun Zhu and Chaotao Ding and Runlong Cao and Shangzhan Zhang and Yan Wang and Zejian Li and Lingyun Sun and Papa Mao and Ying Zang},
year={2023},
eprint={2304.09148},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
The part of the code is derived from SATR: Zero-Shot Semantic Segmentation of 3D Shapes by Ahmed Abdelreheem, Ivan Skorokhodov, Maks Ovsjanikov, and Peter Wonka
from KAUST and LIX, Ecole Polytechnique. Thanks to the authors for their awesome work!