This repository contains code and data to reproduce the findings featured in our stories, "Google Has a Secret Blocklist that Hides YouTube Hate Videos from Advertisers—But It’s Full of Holes," and "Google Blocks Advertisers from Targeting Black Lives Matter YouTube Videos" from our series Google the Giant.
Our methodology is described in "How We Discovered Google’s Hate Blocklist for Ad Placements on YouTube," and "How We Discovered Google’s Social Justice Blocklist for YouTube Ad Placements."
Data that we collected and analyzed are in the data folder.
Jupyter notebooks used for data collection, preprocessing and analysis are in the notebooks folder.
Warning: this repository contains many offensive terms and expletives.
Make sure you have Python 3.6+ installed, we used Miniconda to create a Python 3.8 virtual environment.
Then install the Python packages:
pip install -r requirements.txt
These notebooks are intended to be run sequentially, but they are not dependent on one another.
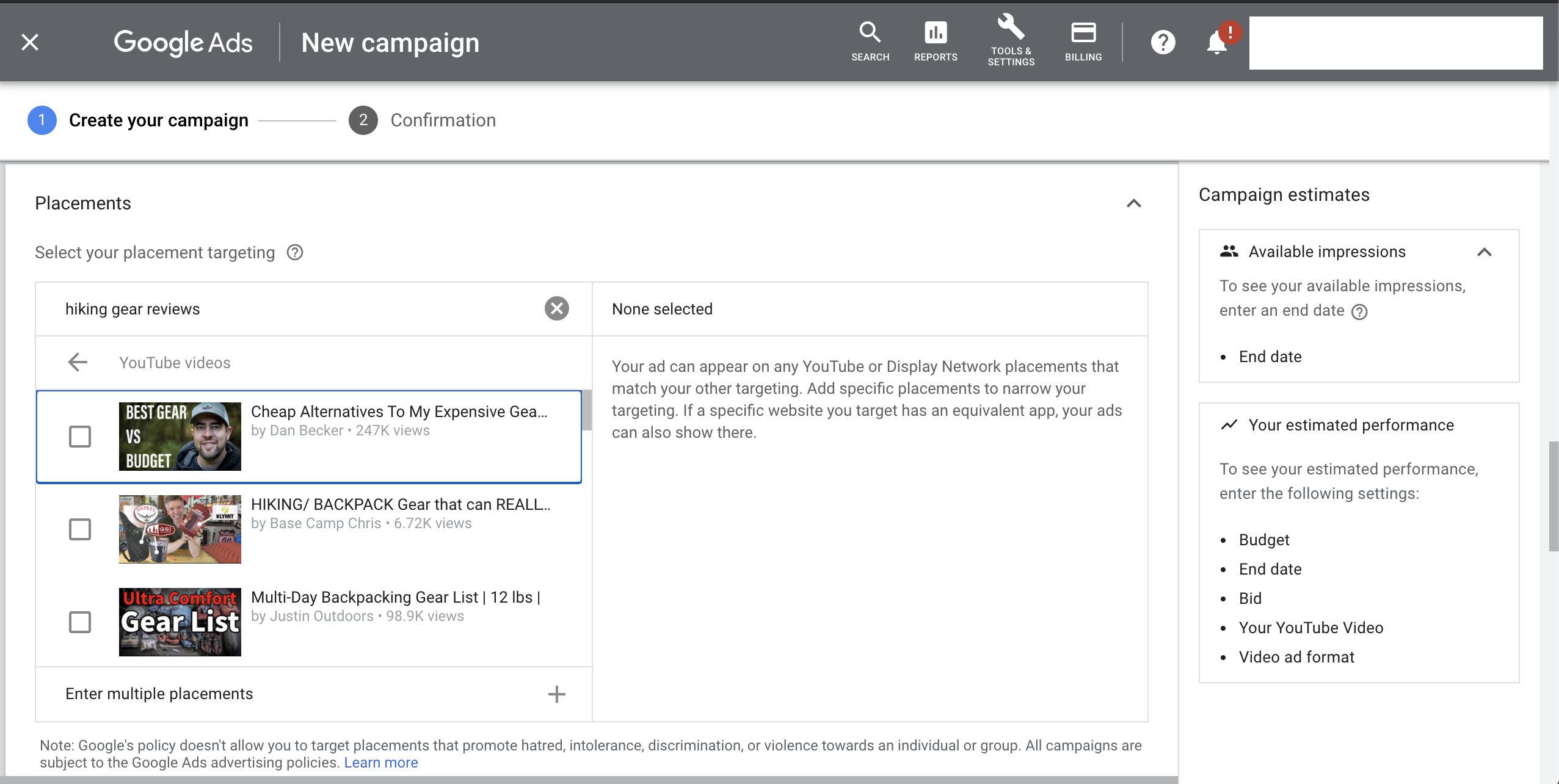
How we interacted with the "PlacementSuggestionService" API from "ads.google.com". We sent each term from terms.py through the API. Use this notebook for reference: it is not functional due to the expired or redacted parameters present.
Parsing the API responses and fetching the suggested videos and channels for each term we sent to the API.
The bulk of stats and tables for our hate methodology.
Looks at videos and channels suggested by the API for hate terms. We cross reference these suggestions with channels identified as "extremist" or "alternative" by researchers from Dartmouth College, Northeastern University, and University of Exeter and provided to the Markup by the ADL, as well as a channels researchers at EPFL and UFMG identified as "alt-right" or "alt-lite".
The bulk of stats and tables for our social justice methodology.
After we shared our findings with Google, we re-run the analysis on data collected on March 31, 2021. Check what changed from the original data we collected on November 20, 2020.
Contains functions to parse and decipher the API responses.
This contains lists of terms used in the series. This includes hate terms sourced from the SPLC, RationalWiki.org, and Muslim Advocates. social_justice terms sourced from Color of Change, MediaJustice, Mijente, and Muslim Advocates. adhoc terms were submitted for comparison against terms in the other lists. noise contains randomly generated strings.
Refer to the "Data" section below for the API status of each of these terms.
This directory is where inputs, intermediaries and outputs are saved.
data
├─── reference
│ ├── placements_api_example_responses
│ │ ├── blocked.json
│ │ ├── empty.json
│ │ ├── full.json
│ │ └── partially_blocked.json
│ └── what_is_blocked.xlsx
├── input
│ ├── channel_lists
│ ├── hate_terms_background_info.csv
│ ├── placements_api
│ │ ├── adhoc
│ │ ├── blocked
│ │ ├── blocked_basewords
│ │ ├── hate
│ │ ├── noise
│ │ ├── policy
│ │ └── social_justice
│ ├── placements_api_deep3
│ │ ├── we wuz kangz.json
│ │ ├── white ethnostate.json
│ │ └── whitegenocide.json
│ └── video_metadata
│ ├── deep_catalog_wwk_wg_we.csv
│ └── topline_hate_videos.csv
└── output
├── channel_overlap.csv
├── tables
├── placements_api_keyword_status
│ ├── adhoc.csv
│ ├── basewords.csv
│ ├── hate.csv
│ ├── policy.csv
│ └── social_justice.csv
└── placements_api_suggestions
├── channels_for_hate_terms.csv
├── channels_for_social_justice_terms.csv
├── videos_for_hate_terms.csv
└── videos_for_social_justice_terms.csv
| filename or directory | description |
|---|---|
data/reference/placement_api_example_responses/ |
Examples of blocked, partially_blocked, full and empty responses from the "PlacementSuggestionService" API. See the methodology for details, and determine_status in notebooks/utils.py for implementation. |
data/reference/what_is_blocked.xlsx |
A spreadsheet with the kind of API responses for all the terms in our investigation. |
data/output/tables/ |
CSVs of tables that are in the methodology. |
data/input/placements_api/ |
This contains responses for keywords from notebooks/terms.py that we submitted to the "PlacementSuggestionService" API. Each subdirectory is organized by the keyword list used. blocked are terms that we resubmitted after removing spaces, and blocked_basewords are terms that were blocked and resubmitted word-by-word. |
data/output/placements_api_keyword_status/ |
Contains the API status of keywords from notebooks/terms.py after being sent through the "PlacementSuggestionService" API. |
data/output/placements_api_suggestions/ |
The suggested YouTube videos and channels for each search term. |
data/input/placements_api_deep3/ |
API responses for the hate terms "we wuz kangz", "white ethnostate" and "white genocide" beyond the topline 20 video suggestions. |
data/input/video_metadata/ |
Video metadata for suggested videos from the YouTube Data API (v3). Collected with the unofficial Python client (YouTube Data API) |
data/input/channel_lists/ |
Contains channel names and IDs that researchers at EPFL and UFMG identified as "alt-right" and "alt-lite" in their 2020 ACM FAT* paper "Auditing radicalization pathways on YouTube". We used a supplementary "extremist" and "alternative" channel list created by researchers for the ADL report "Exposure to Alternative & Extremist Content on YouTube", however that list is only available by request. |
data/output/channel_overlap.csv |
The count of unique "extremist", "alternative", "alt-right" and "alt-lite" videos and channels from the topline suggestions for hate terms we sent through the "PlacementSuggestionService" API. We included the channels that were suggested in the channels column. |
data/input/hate_terms_background_info.csv |
Links for more information about each of the terms in the hate list. |
data/z_data_rerun/ |
API responses from re-running the experiment on March 31, 2021. Identical organization as data/input/placements_api/ and data/output/placements_api_keyword_status/. |