Data Preprocessing Steps and Inspiration
Future Possibilities of the Project
This project focuses on developing and evaluating various product recommender systems. It aims to enhance user experience by suggesting relevant products and boost customer satisfaction and sales through personalized recommendations.
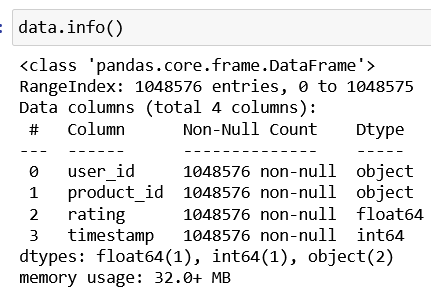
The dataset used in this project contains Amazon Electronics product ratings and reviews. The data is sourced from a CSV file: ratings_Electronics.csv.
- user_id: Unique identifier for each user.
- product_id: Unique identifier for each product.
- rating: Rating given by the user to the product.
- timestamp: Time of the rating.
- Total No of Users: 786,330
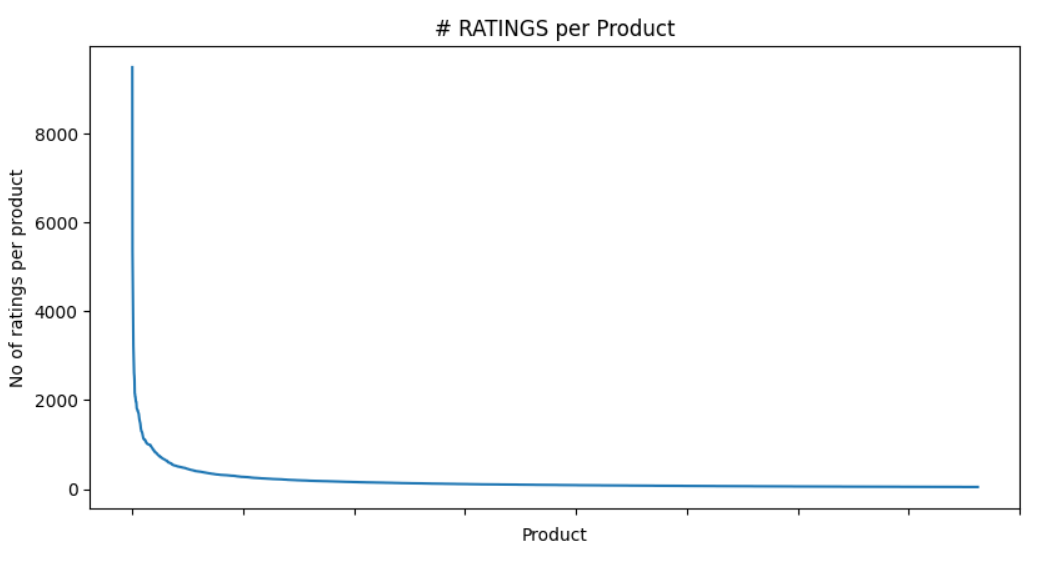
- No of users having given at least 50 ratings: 38
- Total No of products: 61,894
- No of products having given at least 50 ratings: 3,813
-
Python: Data Cleaning and Analysis
-
Jupyter Notebook: For interactive data analysis and visualization
Libraries
Below are the links for details and commands (if required) to install the necessary Python packages:
Below are the links for details and commands (if required) to install the necessary Python packages:
- pandas: Go to Pandas Installation or use command:
pip install pandas - numpy: Go to NumPy Installation or use command:
pip install numpy - matplotlib: Go to Matplotlib Installation or use command:
pip install matplotlib - seaborn: Go to Seaborn Installation or use command:
pip install seaborn - scikit-learn: Go to Scikit-Learn Installation or use command:
pip install scikit-learn - surprise: Go to Surprise Installation or use command: pip install scikit-surprise`
- Data loading and initial exploration
- Data cleaning and manipulation
- Checking for missing values and duplicates
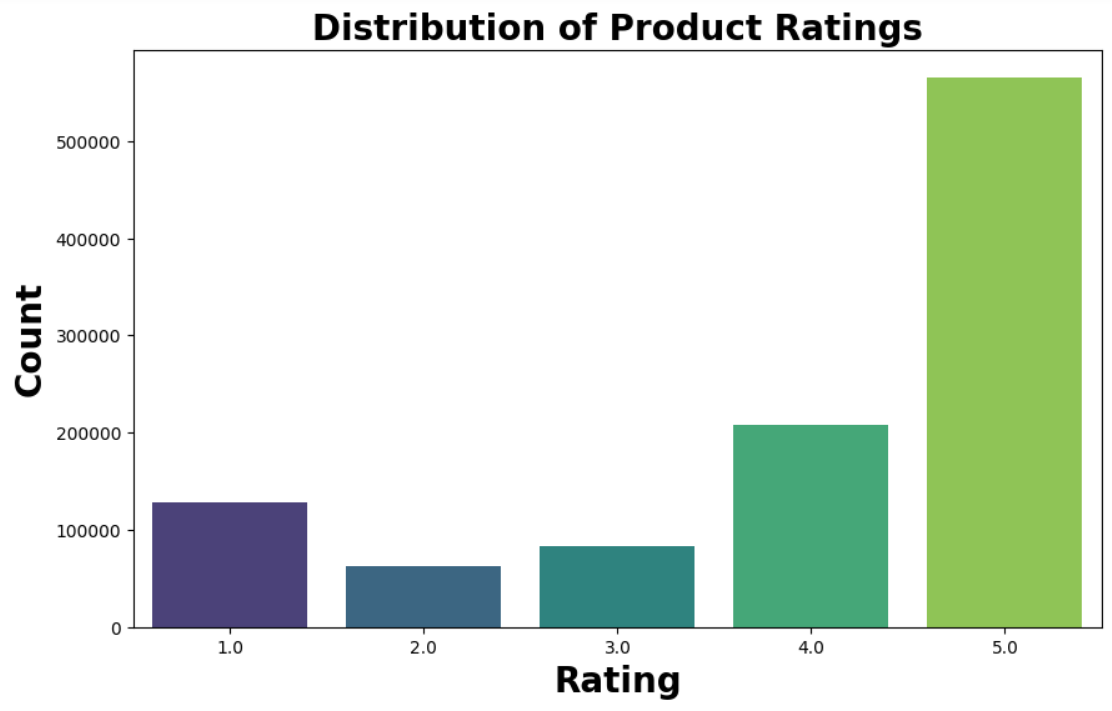
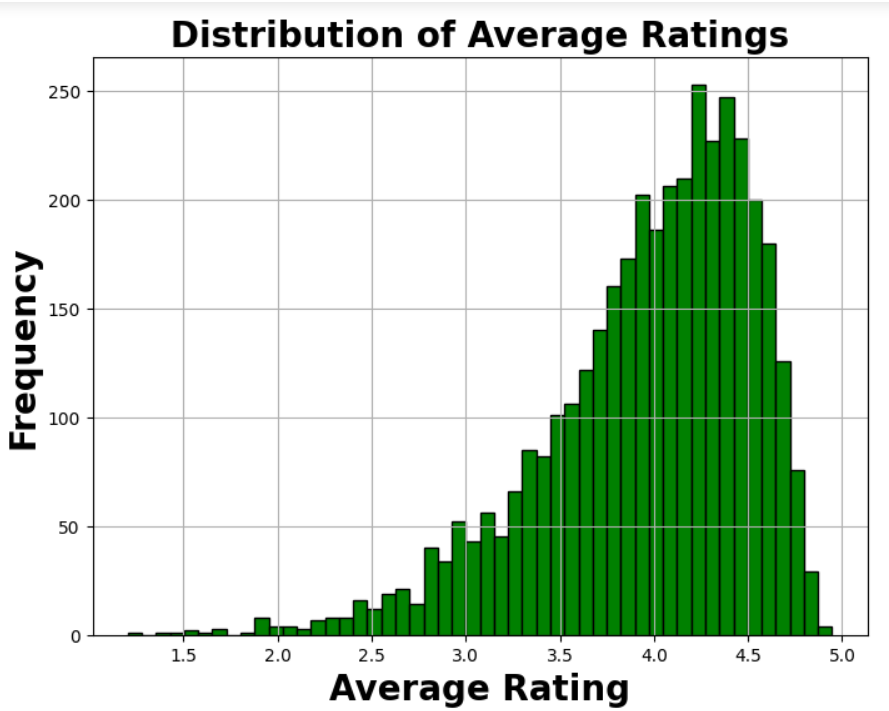
- Analyzing the distribution of product ratings
- Handling Missing Values: Checked for missing values and duplicates in the dataset.
- Subset Selection: Selected a subset of the dataset for analysis to optimize performance.
-
Popularity-Based Recommender: Recommends products based on their popularity (number of ratings).
-
Collaborative Filtering:
a. User-Based Filtering:
- KNNBasic: A basic K-nearest neighbors algorithm for collaborative filtering based on user similarities.
- KNNWithMeans: An enhanced K-nearest neighbors algorithm that takes into account the mean ratings of users for better predictions.
b. Item-Based Filtering:
- KNNBasic: A basic K-nearest neighbors algorithm for collaborative filtering based on item similarities.
- KNNWithMeans: An enhanced K-nearest neighbors algorithm that takes into account the mean ratings of items for better predictions.
c. Matrix Factorization (SVD): Uses Singular Value Decomposition to predict user ratings for products based on past user ratings.
- Ratings provided by users are reliable.
- User preferences are consistent over time.
- Products with higher ratings are preferred by users.
RMSE (Root Mean Square Error) was used to evaluate the performance of different models.
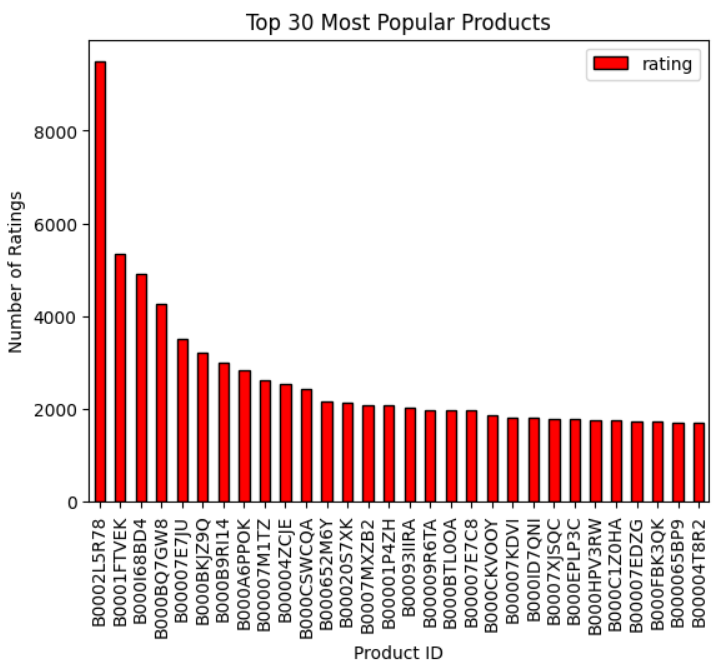
Top 30 products as per popularity recommender
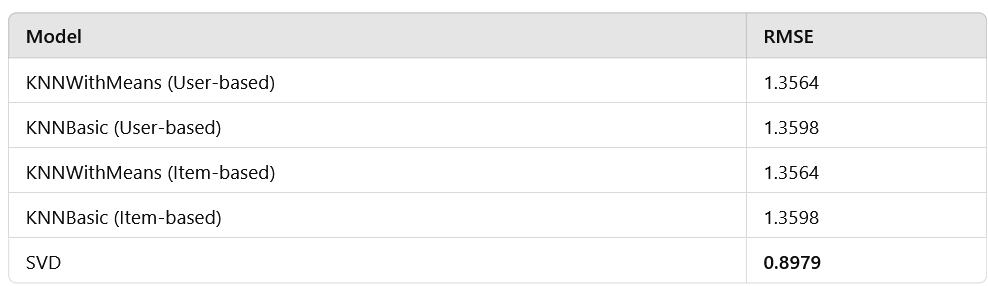
SVD was the best model with the least RMSE of 0.898
Top 5 products for a given user(an example) with SVD
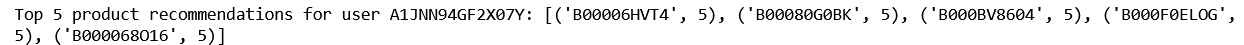
Top 5 products similar to a given product(an example) with SVD
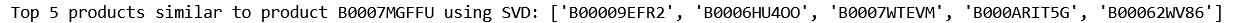
- Further data collection and feature engineering could improve recommendation accuracy.
- Regularly updating the model with new product data can help maintain recommendation relevance.
- Implementing user feedback mechanisms to continuously improve recommendations.
- The dataset may contain biases that could affect the recommendations.
- The recommendation performance is limited by the quality and quantity of the available data.
- Exploring additional recommendation algorithms and ensemble methods.
- Implementing deep learning models for better performance.
- Developing real-time recommendation systems based on user interactions.