![]()
Project Page | Paper | Model
Cognitive Kernel is an open-sourced agent system designed to achieve the goal of building general-purpose autopilot systems. It has access to real-time and private information to finish real-world tasks.In this repo, we release both the system and the backbone model to encourage further research on LLM-driven autopilot systems. Following the guide, everyone should be able to deploy a private 'autopilot' system on their own machines.
- Download the model weights from the following resources.
| Model Name | Model Size | Model Link |
|---|---|---|
| llama3_policy_model_8b | 8B | link |
| llama3_policy_model_70b | 70B | link |
| helper_model_1b | 1B | link |
- Install the necessary environment to run the model services. We used TGI to serve both our policy model and helper model. You can set up the TGI official docker following the guidelines here. We also provide the docker image that we used in our experiments here, which has an older version of TGI installed. Alternatively, we also support vllm inference for our policy model, and you can follow the official vllm installation guidelines here. For vllm, we have tested our service on 0.5.4 and 0.4.2, we found that there might be unstable issues for vllm>=0.5.5.
-
2.1 Start the main policy model
- If you are using TGI
If you choose to use our docker image, you will need to activate the conda environment before starting the TGI command.
text-generation-launcher --model-id path/to/downloaded/policy/model --port YOUR_PORT --max-total-tokens 8192 --max-input-length 8000 --max-batch-prefill-tokens 8000 --num-shard 8 --rope-scaling linear --master-port YOUR_MASTER_PORTconda activate tgi - If you are using vllm
python -m vllm.entrypoints.openai.api_server --model path/to/downloaded/policy/model --worker-use-ray --tensor-parallel-size 8 --port YOUR_PORT --host 0.0.0.0 --trust-remote-code --max-model-len 8192 --served-model-name ck
- If you are using TGI
-
2.2 Start the Helper LLM
-
Step 1: Launch the TGI service:
CUDA_VISIBLE_DEVICES=YOUR_GPU_ID text-generation-launcher --model-id PATH_TO_YOUR_HELPER_LLM_CHECKPOINT --port YOUR_PORT --num-shard 1 --disable-custom-kernels -
Step 2: Configure service URLs.
Update the
service_url_config.jsonfile. Replace the values for the following keys with the IP address and port of your Helper LLM instance:concept_perspective_generationproposition_generationconcept_identificationfilter_docdialog_summarization
-
-
2.3 Start the text embedding model
-
Step 1: Install the required dependencies:
Install
cherrypyandsentence_transformers. -
Step 2: Launch the embedding service:
python text_embed_service.py --model gte_large --gpu YOUR_GPU_ID --port YOUR_PORT --batch_size 128 -
Step 3: Configure service URLs:
Update the
service_url_config.jsonfile. Replace the value ofsentence_encodingwith the IP address and port of your text embedding service instance.
-
-
Edit the configuaration files:
docker-compose.yml:
- add the "IP:Port" of the policy model (8b/70b) servers to SERVICE_IP;
-
Download and install the Docker desktop/engine
-
Go to the repo folder and then
docker-compose build
or
docker compose build
- Start the whole system with
docker-compose up
or
docker compose up
Then, you should be able to play with the system from your local machine at (http://0.0.0.0:8080). PS: for the first time you start the system, you might observe an error on some machines. This is because the database docker takes some time to initiate. Just kill it and restart, the error should be gone.
Demo 1: Search for citations of an uploaded paper on Google Scholar.
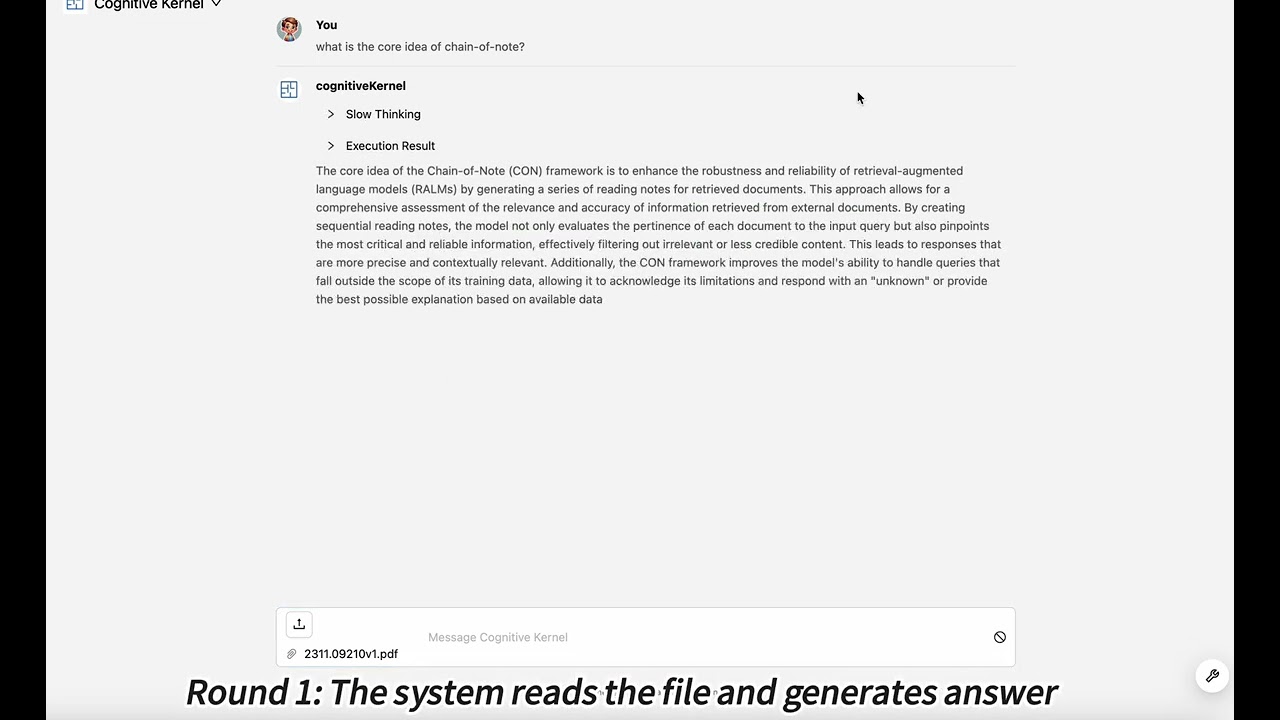
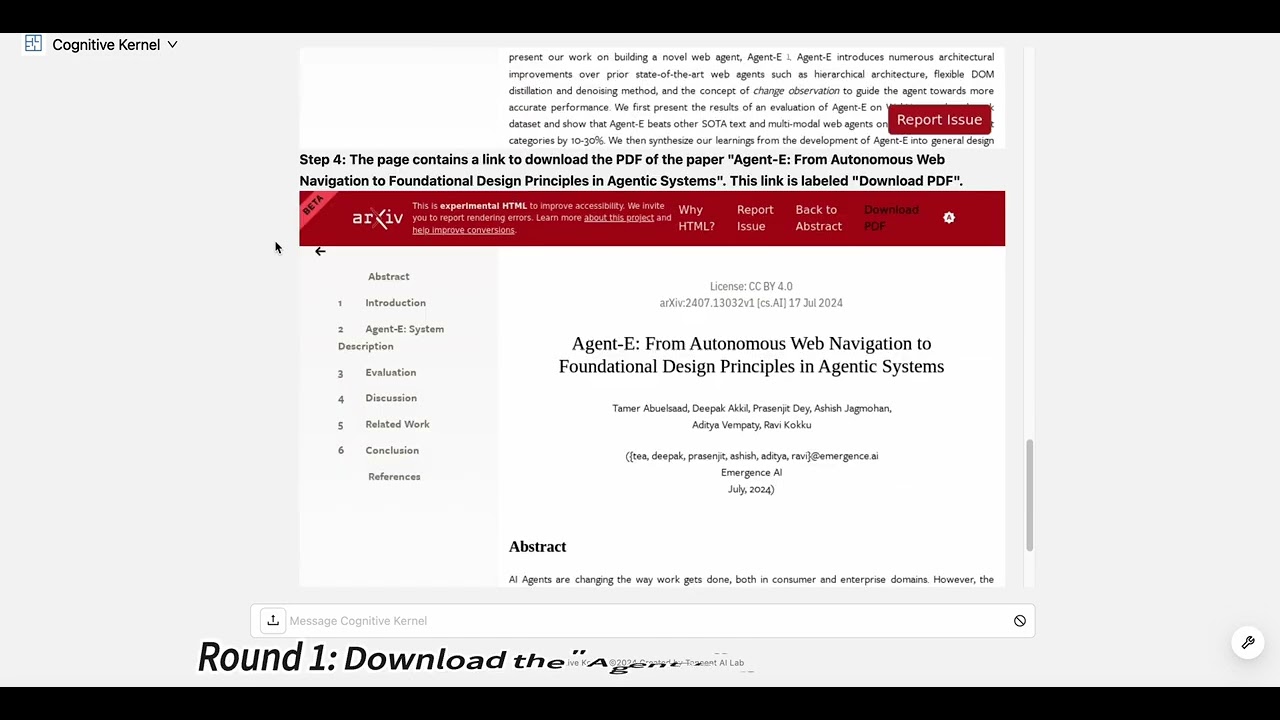
Demo 2: Download a scientific paper and ask related questions.
We welcome and appreciate any contributions and collaborations from the community.
Cognitive Kernel is not a Tencent product and should only be used for research purpose. Users should use Cognitive kernel carefully and be responsible for any potential consequences.
If you find Cognitive Kernel is helpful, please consider cite the following technical report.
@article{zhang2024cognitive,
title={Cognitive Kernel: An Open-source Agent System towards Generalist Autopilots},
author={Zhang, Hongming and Pan, Xiaoman and Wang, Hongwei and Ma, Kaixin and Yu, Wenhao and Yu, Dong},
year={2024},
}
For technical questions or suggestions, please use Github issues or Discussions.
For other issues, please contact us via cognitivekernel AT gmail.com.