制御系とかロボティクスでの今の流行りは深層強化学習でしょうということで、深層強化学習を試してみました。いわゆる「やってみた」程度の内容なのですけど、それだけでは少し寂しいので「強化学習とはなんぞや?」からやります。無駄に長くてごめんなさい。
あと、今回のコードでは畳み込みを使用してないので、今どきの高速なCPUなら、GPUとそんなに大きくは変わらない速度で動くと思います。GPUを使う場合でも、メモリの消費量が小さいのでそれほど凄いGPUじゃなくても動くと思います。ぜひ、実際に動かしてみてください。
動かす際の注意点なのですけど、OSがWindowsの場合はPython3.8を使った方が楽だと思います。2021年4月現在だと、OpenAI GymがPillow7.2までしか対応していなくて、Python3.9向けのバイナリが用意されているのはPillow8以降で、Pillow7.2をセットアップするにはzlibが必要なんだけどWindowsだとzlibをインストールが面倒なためです。WindowsとPython 3.8.9なら、pip install -r requirements.txtするだけで環境を作れます。
強化学習は機械学習の手法の一つで、大雑把には、試行錯誤を通じて取るべき行動を学ぶ手法だと考えてください。で、行動する主体のことを、強化学習ではエージェント(agent)と呼びます。このエージェントがどのような行動をすべきかを学ぶ手がかりとして、行動の結果が良かったのか悪かったのかを数値で表現した報酬(reward)を与えます。あと、どんなときにどんな行動をしたらどんな報酬をもらえたのかという形で学べるように、環境を観測した結果(observation。環境の内部状態ではなくて、エージェントが環境を観察して得られる情報です。「テレパシーを使えないので上司が何を考えているのかは分からないけど、怒っていることだけは分かった」みたいな感じ)も与えます(モデル・フリー学習の場合。これ以外にも、環境モデルそのものを学習するモデル・ベース学習ってのもあります。AlphaZeroとかがモデル・ベース学習)。
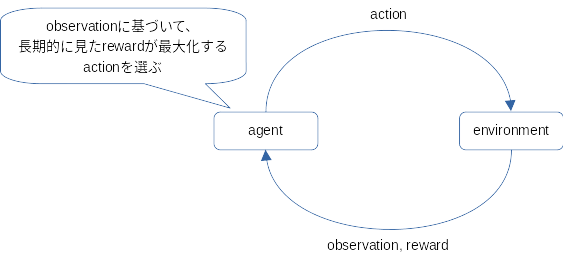
ここで問題となるのは、高い報酬を得たときの行動だけではなくて、それより前の行動も報酬に影響していることです。たとえば迷路でゴールまで辿り着けたのは、ゴールの1マス手前でゴールの方に進んだからだけではなくて、もっと前の局面で正しい方向に進んだからでもありますよね。だから、今回の行動で得た報酬は、その報酬に貢献した以前の行動にも反映させなければならなくて難しい……けど、どうすればよいのはすでに偉い人が考えてくれました。
簡単な題材を使用して、実際のコードで考えてみましょう。題材は、OpenAI GymのFrozenLake-v0を使用します。
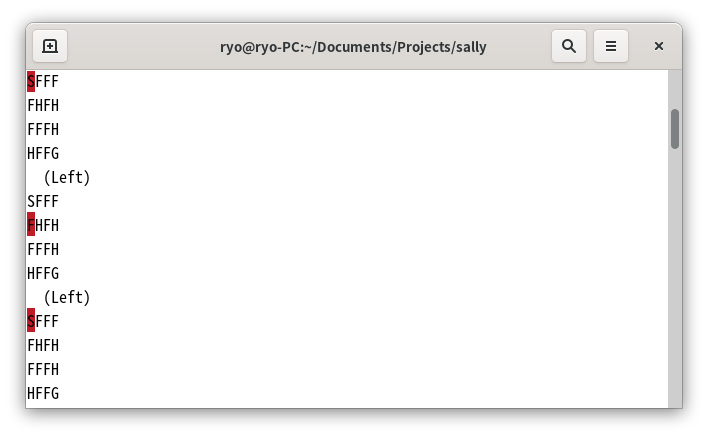
FrozenLake-v0は、上下左右に移動できる(斜めには移動できない)キャラクターを、スタートからゴールまで移動させられたら成功というゲームです。舞台は凍った池で、フィールドは「F」と書かれた凍っているので上を歩ける部分と、「H」と書かれた穴が開いているので落っこちてゲーム・オーバーになってしまう部分、「S」と書かれたスタートと「G」と書かれたゴールで構成されています。で、氷の上なので思い通りには進めません。左に移動しようとした場合は、左か上か下のどれかにそれぞれ1/3の確率で進みます。同様に、上に移動なら上か右か左、右に移動なら右か上か下、下に移動なら下か右か左に、1/3の確率で進みます(ドキュメントにこのルールは見つからなかったけど、コードはこうなっていました)。
あと、FrozenLake-v0では、なにもオプションを指定しないと、マップが以下に固定されます。
SFFF 0 1 2 3
FHFH 4 5 6 7
FFFH 8 9 10 11
HFFG 12 13 14 15
上のマップの右に書いたのは、場所ごとのIDです。エージェントの現在位置は14ですよ、という感じで観測結果として使用されます。周囲がどうなっているのかは観測結果に含まれませんけど、マップが固定なのでまぁなんとかなるでしょう。で、このFrozenLakeをQ学習という強化学習で解くプログラムは、こんな感じになります。
import gym
import numpy as np
# ハイパー・パラメーターを設定します。
learning_rate = 0.1 # 学習率。0〜1。0に近いと学習は遅いけど精度が高く、1に近いと学習は速いけど精度が低くなります。
discount = 0.9 # 割引率。0〜1。0に近いと直近の結果を重視、1に近いと将来の結果を重視するようになります。
# 環境を作成します。
env = gym.make('FrozenLake-v0')
env._max_episode_steps = 10000 # FrozenLake-v0は100手で終了してしまう(TimeLimitでラップしてある)ので、制限を緩めておきます。
# Qテーブルを作成します。
q_table = np.zeros((env.observation_space.n, env.action_space.n), dtype=np.float32)
# 学習します。
def train():
for _ in range(5000): # 5,000エピソード繰り返して学習します。
observation = env.reset() # 環境を初期化します。
done = False
while not done: # エピソードが終了になるまで、ループします。
action = np.argmax(q_table[observation]) if np.random.random() < 0.9 else env.action_space.sample() # 基本はQテーブルからだけど、時々ランダムでアクションを決定します。
next_observation, reward, done, _ = env.step(action) # アクションを実行します。
if done and reward == 0: # FrozenLake-v0はゴールに辿り着いた時の報酬が1でそれ以外は0なので、行動を避ける方向の学習が働きません(Qテーブルの初期値をゼロにしたので、マイナスがないと同じ行動が何度も選択されてしまう)。
reward = -1 # なので、終了 and 報酬 == 0のとき(穴に落ちた or TimeLimitに引っかかったとき)は、報酬を-1にしておきます。本当はラッパーを作るべきなのだけどごめんなさい。
q_table[observation, action] += learning_rate * (reward + discount * np.max(q_table[next_observation]) - q_table[observation, action]) # Qテーブルを更新します。
observation = next_observation
# 学習結果を確認します。
def check():
observation = env.reset()
done = False
while not done:
env.render()
action = np.argmax(q_table[observation])
observation, reward, done, _ = env.step(action)
env.render()
if __name__ == '__main__':
train()
check()OpenAI Gymは、env.reset()で初期化して、env.step()で行動を実行できます。reset()の戻り値は観察結果で、step()の戻り値は行動した後の環境を観測した結果、報酬、エピソードが終了したかどうかの真偽値、その他オプション情報のタプルです。あと、env.render()で環境を画面に表示できます。というわけで、たとえばランダムに行動を実行してどんな環境なのかを画面に表示させて理解したいなら、以下のコードで実現できます。
env = ... # 環境を作成
observation = env.reset()
done = False
while not done:
env.render()
observation, _, done, _ = env.step(env.observation_space.sample())
env.render()話をQ学習に戻しましょう。Q学習では「観測結果がこれこれのときにこんな行動をした場合の結果の価値はどれくらいか」を表現するテーブルを作成します。先程のコードでのq_tableがそれ。観測結果のバリエーションは4×4の16個、行動のバリエーションは左下右上(左が0で下が1、右が2、上が3)の4個で、この情報はenv.observation_space.nとenv.action_space.nから取得できます。今回は、NumPyを使用してQテーブルを作成しました。位置0で下である1の行動を選んだ場合の価値は、q_table[0, 1]で取得でき、位置0で最大の価値をもたらす行動は、np.argmax(q_table[0])で取得できます(np.argmax()は、最大の値を持つ要素のインデックスを返してくれるNumPyの便利関数です)。
Qテーブルは試行錯誤して得た報酬を使用してどんどん良くなっていくのですけど、でも、Qテーブルに従う行動を取るばかりだと他の可能性を無視することになってしまいます。過去の経験からプログラミング言語はJavaが最良である……と信じて毎回Javaを使うだけじゃなくて、ときにはPythonを使ってみるという冒険が最適な解を得るためには必要なんですな。というわけで、基本はQテーブルからアクションを決定しますけど、時々ランダムで適当な手を選ぶようにしています。
action = np.argmax(q_table[observation]) if np.random.random() < 0.9 else env.action_space.sample() # 基本はQテーブルからだけど、時々ランダムでアクションを決定します。さて、本題のQテーブル更新です。Qテーブル更新部分のコードを再掲しましょう。
q_table[observation, action] += learning_rate * (reward + discount * np.max(q_table[next_observation]) - q_table[observation, action]) # Qテーブルを更新します。Qテーブルを今回の結果でまるっと書き換えると過去に学習した内容が消えてしまうので、少しずつ書き換えています。「新しい値 - 現在の値」でどのくらい変化したのかを取得して、それにlearning_rate(値は0〜1。上のコードでは0.1)という適当な値をかけて小さくした結果を足し合わせているわけですね。これで、Qテーブルの要素の値は、少しずつ増減を繰り返して正しい値に収斂していきます。
で、問題はその正しい値として何を使うのかです。この話を始めたのは「今回の行動で得た報酬を以前の行動にも反映させる」方法を考えるためでしたよね? それをやっているのが、reward + discount * np.max(q_table[next_observation])の部分です。理解するために、うまいこと位置14からゴールに移動できて報酬1を得た次のエピソードで、ある行動を選択した結果として位置13から位置14に移動するところなのだと考えてください。位置13から今回選択した行動を取る場合の価値の計算に、next_observation(次の観測結果である位置14が入っている)を使用しています。で、Qテーブルの位置14の行動0〜3のどれかに相当するところには、前のエピソードでうまいことゴールしたときに得た報酬1で少し大きくなった値が入っているわけで、エージェントは最適な行動を選ぶので位置14の価値はnp.max(q_table[14])(位置14での各種行動の価値の最大値)と置き換えてもよいはず。この価値を、discount(値は0〜1。上のコードでは0.9)を掛けて適当に割り引いた上で位置13の価値に足し込んでいます。一回の更新だけで見ると先の行動で得た報酬を今回の行動に反映させているように見えるけど、これを何回も何回も繰り返せば、今回の行動で得た報酬を前の行動に反映させたことになるというわけ。
で、これをグリグリと5,000回ほど繰り返して、前の行動に後の行動の価値を割り引いて足しこみ続けてみたら、Qテーブルの位置0における各行動の価値はこんな感じになりました。
[ 0.0496024 0.03457151 0.03058874 0.03276635] # 左、下、右、上の順です。
えっと、左への行動が優勢? 位置0の左にはマスがないんだけど、どういうこと?
実はこれで正しくて、位置0からの行動は左が最適なんですよ。もし右に進んでゴールに向かう場合は位置6(左も右も「H」で危険)を通ることになって、位置6から下への行動を選択すると、下か右か左にそれぞれ1/3の確率で進むので2/3の確率で穴に落ちちゃう。だから、右には進みたくない。でも、下への行動を選ぶとと1/3の確率で行きたくない右に進んじゃう。だから敢えて左への行動にして、左か上か下に進むことにして、左や上の場合には進めないので2/3の確率で位置の変更はなし、そして1/3の確率で安全に下に進めるので嬉しいというわけ。ほら、位置0での行動は左が最適で、これを勝手に学んだQ学習は凄いでしょ?
でもね、Q学習って適用範囲が狭いんですよ……。
FrozenLake-v0でQ学習できたのは、状態や行動のバリエーションの数が少ないからなんです。0〜9の10個の値を取る変数が10個あれば、10×10×10×10×10×10×10×10×10×10は10,000,000,000なので100億通りの状態がありえちゃう。これに行動のバリエーション数をかけた巨大なQテーブルを作成するのは辛すぎるでしょ?
だから深層学習のニューラル・ネットワークでQテーブルを置き換えちゃおうというのが、Atari 2600のゲームの29種類でプロゲーマー以上のパフォーマンスを見せて世界を驚かせたDQNです。深層学習のニューラル・ネットワークはあらゆる関数を近似できて、Qテーブルってのは状態と行動を引数にして価値を返す関数だと考えることもできるので、ほら、深層学習で置き換えることができちゃう。
このDQNは、過去の経験を溜め込んでサンプリングした結果を教師データとして機械学習するexperience replayという仕組を入れたり、報酬の範囲を-1〜1に限定したりと他にもいろいろ工夫をしているのですけど、基本はQ学習なので簡単に実装できたりして素晴らしい。
ではさっそくDQNで深層強化学習してみる……のは、今回の課題だとちょっと難しいんですよ。
世の中には、たとえば所有するオートバイの台数みたいに1台、2台と数えられるもの(私は少々頭が悪いので5台持っています。バイクはバカにしか乗れません)と、たとえば体重みたいにどこまでも細かくしていけるもの(コロナ太りで79.9kgになりました。体重計が80kgだと表示しても79.999999...kgを丸めて80kgと表示したのだと信じます)があり、前者を離散量、後者を連続量と呼びます。
で、DQNは行動が離散量の場合にしか使えない手法なんです(ちなみにQ学習は状態も離散量でないと駄目)。残念なことに、今回の課題の行動は、アクセル操作(-1.0〜1.0)とブレーキ操作(0.0〜1.0)とステアリング操作(-1.0〜1.0)なので、見事に連続量です。適当な範囲に区切ることで連続量を離散量として扱うという手もあるのですけど、美しくないのでなんか嫌。区切り方次第で結果が変わってしまいそうで怖いですしね。
でも大丈夫。深層学習ってのは微分可能な式のパラメーターを逆誤差伝播法で更新していくという手法で、だから微分可能な式でさえあれば途中にいろいろな計算を入れることができて、数学的に証明された美しい方法で連続量の行動を最適化していくなんてことも可能なんです。このような手法の中には凄いのもあって、時々ランダムにアクションする部分をどうすればよいのかまで、数学的に美しく決定する手法もあったりします。この手法の内容を数式で……
表現したかったのですけど、実は私はゴリゴリの文系人間で、とにかく数学できないんですよ。数式を見ると気持ち悪くなっちゃう。だから数式の紹介は省略させてください。
で、そんな私ごときがなぜ深層強化学習できるのかといえば、数学が得意な人がすでにプログラムを組んでライブラリ化してくれたから。今回は、Stable-Baselines3を使用しました。OpenAIという人工知能を研究する非営利団体があって、そこが強化学習するための環境として本稿の前の方で使用したFrozenLake-v0等を含んでいるOpenAI Gymというのを作っていて、でも環境があっても強化学習のアルゴリズムをプログラミングするのはやっぱり大変だろうということでBaselinesという強化学習アルゴリズムの実装を作ってくれて、ただしこのBaselinesは動きはするんだけど再利用に難があって、だからフォークしてインターフェースを統一したりコメントを入れたりリファクタリングしたりして作り直したのがStable-Baselinesで、これはTensorflowのバージョン1向けに作られているんですけど、Tensorflowはバージョン2で大きな変更があって対応が大変で、ならもういっそのこと流行りのPyTorchで作り直しちゃえということで作られたのがStable-Baselines3で、タイミングが良いことに今年(2021年)にv1.0がリリースされました。
連続量を扱える、かつ、できるだけ新しい、かつ、Stable-Baselines3で実装済みなアルゴリズムとして、今回は2018年に論文が発表されたSAC(論文1、論文2)にしてみました。
SACの数式は私では全く理解できませんでしたけど、方策(どの行動を選べば良いのか)を学習するActorと状態の価値を学習するCriticが協調して動作するという、ウルトラマンAで北斗隊員と南隊員が合体して変身したことを思い出させるような美しい構成で、でも学習後に実際に使うときはActorだけを使うという、途中で南隊員が月に帰ってしまって北斗隊員が単独で変身していた後半の切なさを思い出させる動きが素敵です。まぁ、今どきの深層強化学習アルゴリズムの多くはActor-Criticなので、別にSACに限った話ではないんですけどね。
で、SACのSはSoftのSで、SoftってのはSoft-Q学習のSoftです。どれくらい探索したかを表現する方策エントロピーを数式に入れて、その方策エントロピーを最大化させることで、「時々ランダム」みたいな原始的な方法とは異なる、数学的に優れた探索をしてくれる……らしい。私では数式を全く理解できなかったけどな。でもエントロピーって言葉がなんだか宇宙っぽくてかっこいいから、今回はSACでやることにします。
ともあれ、使用するアルゴリズムが決まりましたので、いざ深層強化学習……
……する前に、Stable-Baselines3が前提としているOpen AI Gym形式の環境を作らなければなりません。早く深層強化学習をやりたいので、いきなりソース・コードを載せます。
import gym
import numpy as np
import pygame
import pymunk
from funcy import concat, flatten, mapcat
from game import FPS, Game, OBSTACLE_COUNT, STAR_COUNT
from operator import itemgetter, methodcaller
from simulator import MAX_SPEED
class SelfDriving(gym.Env):
def __init__(self):
self._seed = None
self.name = 'SelfDriving'
self.action_space = gym.spaces.Box(np.array((-1, -1, -1), dtype=np.float32), np.array((1, 1, 1), dtype=np.float32), dtype=np.float32)
self.observation_space = gym.spaces.Box(
np.array(tuple(concat(
(
-1, # my_car.position.x
-1, # my_car.position.y
-1, # my_car.angle
-1, # my_car.velocity_angle
0, # my_car.velocity_length
-1, # my_car.steering_angle
-1, # my_car.steering_torque
0, # my_car.score
0, # my_car.crash_energy
),
mapcat(lambda _: (
-1, # other_car.position_angle
0, # other_car.position_length
-1, # other_car.angle
-1, # other_car.velocity_angle
0, # other_car.velocity_length
-1, # other_car.steering_angle
0, # other_car.score
0, # other_car.crash_energy
), range(7)),
mapcat(lambda _: (
-1, # obstacle.position_angle
0 # obstacle.position_length
), range(OBSTACLE_COUNT)),
mapcat(lambda _: (
-1, # star.position_angle
0 # star.position_length
), range(STAR_COUNT)),
)), dtype=np.float32),
np.array(tuple(concat(
(
1, # my_car.position.x
1, # my_car.position.y
1, # my_car.angle
1, # my_car.velocity_angle
1, # my_car.velocity_length
1, # my_car.steering_angle
1, # my_car.steering_torque
1, # my_car.score
1, # my_car.crash_energy
),
mapcat(lambda _: (
1, # other_car.position_angle
1, # other_car.position_length
1, # other_car.angle
1, # other_car.velocity_angle
1, # other_car.velocity_length
1, # other_car.steering_angle
1, # other_car.score
1, # other_car.crash_energy
), range(7)),
mapcat(lambda _: (
1, # obstacle.position_angle
1 # obstacle.position_length
), range(OBSTACLE_COUNT)),
mapcat(lambda _: (
1, # star.position_angle
1 # star.position_length
), range(STAR_COUNT)),
)), dtype=np.float32),
dtype=np.float32
)
self.screen = None
self.reset()
@classmethod
def _create_observation(cls, game):
# dict形式のデータを、深層学習で扱えるように数値の集合に変換します。
def get_values(observation):
return flatten(concat(
observation['my_car'].values(),
mapcat(methodcaller('values'), sorted(observation['other_cars'], key=itemgetter('position_length'))), # 距離が近い順にソートします。前後も分けたほうが良い?
mapcat(methodcaller('values'), sorted(observation['obstacles' ], key=itemgetter('position_length'))), # noqa: E202
mapcat(methodcaller('values'), sorted(observation['stars' ], key=itemgetter('position_length'))) # noqa: E202
))
# -1〜1の範囲になるように、observationを変換します。
observation = (
np.array(tuple(get_values(game.create_observation(game.cars[0]))), np.float32) / # noqa: W504
np.array(tuple(concat(
(
1000, # my_car.position.x
1000, # my_car.position.y
np.pi, # my_car.angle
np.pi, # my_car.velocity_angle
MAX_SPEED / FPS, # my_car.velocity_length
np.pi, # my_car.steering_angle
10, # my_car.steering_torque
30, # my_car.score
10 * FPS, # my_car.crash_energy
),
mapcat(lambda _: (
np.pi, # other_car.position_angle
1000, # other_car.position_length
np.pi, # other_car.angle
np.pi, # other_car.velocity_angle
MAX_SPEED / FPS * 2, # other_car.velocity_length
np.pi, # other_car.steering_angle
30, # other_car.score
10 * FPS, # other_car.crash_energy
), range(7)),
mapcat(lambda _: (
np.pi, # obstacle.position_angle
1000 # obstacle.position_length
), range(OBSTACLE_COUNT)),
mapcat(lambda _: (
np.pi, # star.position_angle
1000 # star.position_length
), range(STAR_COUNT)),
)), dtype=np.float32)
)
observation[observation < -1] = -1
observation[observation > 1] = 1 # noqa: E222
return observation
def reset(self):
self.game = Game((self,), self._seed)
return self._create_observation(self.game)
@classmethod
def _calc_car_and_star_distance(cls, game, car):
return min(map(lambda star: (star.position - car.position).length, game.stars))
@classmethod
def _calc_reward(cls, game, car, last_score, last_distance):
return 1 if car.score > last_score else 0
def step(self, action):
last_score = self.game.cars[0].score
last_distance = self._calc_car_and_star_distance(self.game, self.game.cars[0])
self.action = action
done = self.game.step()
return self._create_observation(self.game), self._calc_reward(self.game, self.game.cars[0], last_score, last_distance), done, {}
def render(self, mode='human'):
pygame.init()
pymunk.pygame_util.positive_y_is_up = True
surface = self.game.create_surface()
if mode == 'rgb_array':
return np.reshape(np.frombuffer(pygame.image.tostring(surface, 'RGB'), dtype=np.uint8), (surface.get_height(), surface.get_width(), 3))
if mode == 'human':
if self.screen is None and mode == 'human':
pygame.display.set_caption('self driving')
self.screen = pygame.display.set_mode((800, 640))
self.screen.blit(surface, (0, 0))
pygame.display.flip()
def seed(self, val):
self._seed = val
def get_action(self, _):
return self.action[0], self.action[1] / 2 + 0.5, self.action[2]上のコードでやっている工夫その1は、観察結果を-1〜1の範囲に正規化していることです。というのも、深層学習で学習する際の係数などは、入力が標準正規分布していることを前提に調整されている場合が多くて、入力が標準正規分布から大きくずれているとうまく学習してくれないんですよ。だから、上のコードでは、適当な値(たとえばobstacle.position_lengthは最大でsqrt(2000 ** 2 + 2000 ** 2)になるのだけど、とても遠い場合はあまり関係ないだろうということで1000にしました)で割り算した上で、-1〜1の範囲でクリッピングしています。
工夫その2は、他の参加者の自動車や障害物、スターを距離でソートしていることです。深層学習の入力は行列なのですけど、他の参加者1の自動車の位置は1番目に、他の参加者2の自動車の位置は2番目にあるみたいなデータ構造だと、今すぐ避けなければならない一番近くの車がどれかを調べるのに全部の自動車の位置を調べなければならなくなっちゃう。十分な大きさのニューラル・ネットワークを作成して大量のデータで時間をかけて学習させればいい感じにいろいろ見てくれるようになるとは思うのですけど、事前にソートしてあげたほうが一箇所をみるだけで済むようになるので深層学習さんが楽なんじゃないかなぁと。
それ以外は、Stable-Baselines3が動作する程度にOpenAI Gymの仕様に合わせただけです。面倒だったので、今回は他の参加者の考慮はしていません。一人だけのゲームになります。報酬は、本稿の最初でやったFrozenLake-v0と同様にスターを獲得したら(スコアが前より上がったら)1、そうでなければ0にしてみました。
準備が完了しましたので、SACで深層強化学習してみましょう。Stable-Baselines3のドキュメントのSACのページにサンプルがあったので、それを真似して作ってみます。
from self_driving import SelfDriving
from stable_baselines3 import SAC
from PIL import Image
# 環境を作成します。
env = SelfDriving()
# Stable-Baselines3のSACで深層強化学習します。
model = SAC('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000, log_interval=1)
model.save('self-driving')
# 学習結果を確認するために、実際に動かして動画を保存します。
images = []
observation = env.reset()
done = False
while not done:
images.append(env.render(mode='rgb_array'))
action, _ = model.predict(observation, deterministic=True)
observation, reward, done, _ = env.step(action)
images.append(env.render(mode='rgb_array'))
images = tuple(map(lambda image: Image.fromarray(image), images))
images[0].save('self-driving.gif', save_all=True, append_images=images[1:], duration=1 / 30 * 1000)Stable-Baselines3は本当にすごいですな。学習する部分のコードは保存まで含めて3行だけです。さっそく実行してみましょう。
---------------------------------
| rollout/ | |
| ep_len_mean | 1.8e+03 |
| ep_rew_mean | 0 |
| time/ | |
| episodes | 1 |
| fps | 61 |
| time_elapsed | 29 |
| total timesteps | 1800 |
| train/ | |
| actor_loss | -13.5 |
| critic_loss | 0.0198 |
| ent_coef | 0.601 |
| ent_coef_loss | -2.58 |
| learning_rate | 0.0003 |
| n_updates | 1699 |
---------------------------------
実行すると、上のような内容が画面に表示されました。rolloutは試行錯誤で溜まった経験の内容で、ep_len_meanはエピソードの長さの平均でしょう。1ゲームは60秒で1/30秒に1回行動を入力できるので、エピソードの長さは1,800ちょうどになっています。ep_rew_meanがエピソード単位の報酬の合計の平均でまだスターを獲得していなくて0のまま。timeは実行時間に関する情報で、trainは学習に関する情報です。数式を理解していないので、ごめんなさい、trainの出力の意味は分かりません。誰か教えてください……。
私の型落ちCPUのデスクトップPCで148秒待ったところ、学習が完了しました。で、この画面の中で瀕死のミミズみたいな微妙な動きをしているのが、深層強化学習した結果……。
まぁ、よく考えてみたら、今回の課題は、適当に試行錯誤したらスターを獲得できちゃうような簡単なゲームではありません。だから結局最後までep_rew_mean(エピソードあたりの報酬の平均)は0のままで、報酬がなければ何が良い行動なのかは分からなくて、だから何も学習できなかったのは当たり前ですね。
というわけで、とりあえずゲームをもっと簡単にしましょう。まずは自動車が動いてくれないと話にならないので、自動車の前方向への速度を報酬にしてみます。環境のプログラムの報酬を計算する部分を、以下に修正しました。
@classmethod
def _calc_reward(cls, game, car, last_score, last_distance):
return car.velocity.rotated(-car.angle).x / MAX_SPEED # 前方向への速度なので、ワールド座標での速度を自動車の角度分逆回転させて、前方向であるxの値を取得します。これで、速度を落とす原因になる障害物を華麗に避けながら高速で駆け抜けてくれるんじゃないかなぁ。
……いやいや、ぜんぜん駄目でした。というか、よく考えてみたら10,000ステップって5エピソードとちょっとですもんね。その程度でうまくいくはずなんかありませんな。
しょうがないので、学習するステップ数を増やしましょう。景気よく、100倍の1,000,000ステップで学習させてみます。学習のプログラムの該当する箇所を、以下に変更しました。
model.learn(total_timesteps=1_000_000, log_interval=10)時間はかかるだろうけど、でもまぁ、コンピューターが勝手に頑張ってくれるわけで、私はダラダラしていればよいのだから余裕っすよ。
……ぜんぜん余裕じゃなかったよ! 学習が終わるまでに16,970秒(4時間42分50秒)も待たされて、暇すぎて死んじゃうかと思ったよ! 学習した結果も、思っていたのと違うし。ドリフトしながら障害物を避けまくる華麗なドライビングを期待していたのに、障害物がない外周をぐるぐる回るという卑怯なやり方を学習しやがりました。
まずは、待ち時間が長過ぎるという問題を解決しましょう。といっても、時間がかかることそのものはどうしようもないので、せめて途中で確認できるように学習途中のモデルを保存させるようにします。そうすれば、どのくらい学習したのかを途中で確認することができるので暇すぎて死んじゃう問題は解決できるでしょう。学習途中でのモデルの保存は、Stable-Baselinse3のCheckpointCallbackで実現できるので実装はとても簡単。学習のプログラムを、以下のように修正しました。
from game import FPS, GAME_PERIOD_SEC
from self_driving_4 import SelfDriving
from stable_baselines3 import SAC
from PIL import Image
from stable_baselines3.common.callbacks import CheckpointCallback
env = SelfDriving()
model = SAC('MlpPolicy', env, verbose=1)
model.learn(
total_timesteps=1_000_000,
log_interval=10,
callback=CheckpointCallback(save_freq=GAME_PERIOD_SEC * FPS * 10, save_path='log', name_prefix='self-driving') # CheckpointCallbackを使用して、途中経過を保存させます。
)
model.save('self-driving-train')保存された途中経過を確認するためのプログラムはこんな感じ。
import os
from funcy import last # funcyは、私が大好きなPython向け関数型プログラミングのためのライブラリです。
from glob import glob
from self_driving import SelfDriving
from stable_baselines3 import SAC
from stable_baselines3.common.evaluation import evaluate_policy
env = SelfDriving()
model_path = last(sorted(glob('log/*.zip'), key=lambda f: os.stat(f).st_mtime)) # 最新のモデル・ファイルのパスを取得します。
model = SAC.load(model_path, env) # モデルをロードします。
print(model_path)
reward_mean, _ = evaluate_policy(model, env, n_eval_episodes=1, render=True, warn=False) # Stable-Baselines3が提供する評価処理を使用します。楽ちん。戻り値の2つ目は標準偏差なのですけど、今回は盤面が毎回同じなのでn_eval_episodes=1にしているため、使用していません。
print(f'reward: {reward_mean:.02f}')次に、報酬設計のやり直しです。深層強化学習さんに悪気はなくて、与えられた報酬における最適解を探し出しちゃっただけで、つまるところ私が作ったプログラムの報酬が悪かったというわけ。外周を回らせたくないなら、中心から遠ざかるとペナルティを与えるような報酬設計をしなければならなかったんですな。深層強化学習では、こんな感じで報酬設計がキモとなります。で、前に進むのは飽きたので、ゲームのルールに立ち戻って、ゲームの目的に合う報酬に加えて、さらに、報酬が多い方に進むと自然と目的に近づく中間報酬を与えるために、環境の報酬を計算する部分を以下のコードに変更しました。
@classmethod
def _calc_reward(cls, game, car, last_score, last_distance):
if car.score > last_score: # スターを獲得したら……
return 100 # とても大きな報酬を与えます。-1〜1の縛りから外れますが、そんなに発生しないので大丈夫かなぁと。
if car.crash_energy: # 衝突したら……
return -1 # マイナスの報酬を与えます。
return delta if (delta := last_distance - cls._calc_car_and_star_distance(game, car)) > 1 else 0 # スターに高速で近づく場合は報酬を与えます。最後の1行が中間報酬で、出鱈目に進むのではなく、スターに向けて進むように誘導しています(スターとの距離が小さくなった場合に報酬を与えています)。で、スターを獲得するには敢えて遠回りをしなければならない場合があるわけで、だから遠ざかってもペナルティは与えないようにしてみました。あと、ゆっくりとスターに近づかれても困るので、> 1にしています。
……駄目だー! ぜんぜん学習していないー! ちょっとだけバックして、あとは全く動かないでやんの。
こんな駄目な結果になった理由を考えるのを脳が拒否したので現実逃避でダラダラとStable-Baselines3のドキュメントを眺めていたら、RL Baselines3 Zooとしていろいろな問題でのハイパー・パラメーターが集めてあるから参考にしろと書いてありました。活用しないのはもったいないので、RL Baselinse3 Zooのhyperparams/sac.yamlを見てみます。でも、なんだかデフォルト値からあまり変更していませんな……。ニューラル・ネットワークをデフォルトの64ユニット×64ユニットから400ユニット×300ユニットの大きさに変更するためにpolicy_kwargs={'net_arch': [400, 300]}にしているのと、use_sde=Trueにしている程度でしょうか。use_sdeのSDEってのは、State-Dependent Explorationとかいう名前の、探索を増やすための方式みたい。SACのSはSoft Q学習のSで方策エントロピーが良い感じにいろいろ探索してくれるはずなのになんで更に探索を入れるかのという疑問は封印して、use_sde=Trueも追加します。
あと、最初にやったFrozenLake-v0では盤面が固定だったことも思い出しました。ランダムな盤面だと、自分の自動車の前方にスターがある盤面と後方にスターがある盤面が交互にやってきたりして最適な行動が何なのか分からなくなっちゃうわけで、だから、乱数のシードを固定した方がよさそうです。適当なシードをいくつか試してみて、これならなんとなく最初のスターの獲得が簡単そうだなぁという盤面が表示された1234を選びました。
それ以外にも、学習するステップ数をさらに増やしてみました。さらに10倍の10,000,000ステップです。その3の結果から考えると丸2日(ニューラル・ネットワークを大きくしたことを考慮するとそれ以上)かかることになりますけど、途中経過を見て喜んだり悲しんだりして時間を潰せるのでなんとかなるはず。というか、今どきのCPUはコアが複数あって、でも今回の課題のシミュレーターはシングル・スレッドなのでコアを1つしか使わないのだから、報酬やハイパー・パラメーターをいろいろ変更しながら並列で試せばよいわけ。仮に4並列でやったとすれば、1試行あたり半日という計算になります。途中で十分に学習が完了したり途中経過が悪くて打ち切ったりする場合も考慮すれば、さらに短い時間になりますしね。
from game import FPS, GAME_PERIOD_SEC
from self_driving import SelfDriving
from stable_baselines3 import SAC
from stable_baselines3.common.callbacks import CheckpointCallback
env = SelfDriving()
model = SAC(
'MlpPolicy',
env,
use_sde=True, # SDEを使用して、探索する範囲を広げます。
verbose=1,
policy_kwargs={'net_arch': [400, 300]}, # ニューラル・ネットワークを大きくします。
seed=1234 # 環境の乱数シードを固定します。
)
model.learn(total_timesteps=10_000_000, log_interval=10, callback=CheckpointCallback(save_freq=GAME_PERIOD_SEC * FPS * 10, save_path='log', name_prefix='self-driving'))
model.save('self-driving')やってやりました! うまくいきましたよ! 流れるような華麗なドライビングです!
なんか最後は止まっちゃっていますけど(100万ステップくらい学習したところでもここで止まっているので、たぶんその5のやり方での限界。途中で学習を打ち切ればよかった)、気にしないことにします。もっと他に気になることがあるからで、それは「乱数シードが変わるとどうなるのか」です。試してみましょう。
for _ in range(10):
env.seed(None) # 乱数シードをNone(現在時刻を使う)に設定します。
observation = env.reset()
done = False
while not done:
action, _ = model.predict(observation, deterministic=True)
observation, reward, done, _ = env.step(action)
env.render()
……あれ? ぜんぜん華麗じゃない。さっきのは、特定の盤面での最適な行動を学習しただけなの?
ほら、あれだ。ずっと同じ盤面をやっていたので過学習したんじゃないかな? というわけで、最初のころのモデル、300万ステップくらい学習したときのモデルも試してみました。

やはり過学習していたみたいで(本当に、途中で学習を打ち切ればよかった)、かなりマシでした。でもやっぱり、どんな盤面でも華麗なドライビングを決める汎化性能は得ていないみたい。まだまだ先は長いですな。
まだ途中なのですけど、ごめんなさい、ここで時間切れになってしまいました……。というわけで、強引だけどまとめです。まずは、今回の試行で得た知見です。
- 深層強化学習は、たしかに凄いのだけど、そんなに凄くありません。ミッションを成功した場合に1を返す報酬を定義しただけでは、適当に試行錯誤すれば何度も成功できるような簡単な問題しか解けません。ミッション成功に導く中間報酬が必要で、人間が解き方を考えてあげなければならないんです。報酬設計を頑張ってください。
- 今どきの深層強化学習はいろいろ自動化されてハイパー・パラメーター・チューニングの手間は減ってきたのですけど、やっぱりチューニングは必要です。ハイパー・パラメーターをどのようにしたらどんな成績になったのかはまとめられていますので、これらを参考にして、最適なハイパー・パラメーターになるようにチューニングを頑張ってください。
- 深層強化学習について書かれたものを読むと凄そうなことが書かれていて、高い汎化性能を簡単に実現できるように感じるかもしれませんけど、騙されないでください。同じような問題を気が遠くなるくらい繰り返し解いて、その問題と似ている問題を解けるようになる程度です。似ていない別の問題を解くには、別の問題で学習させなければなりません。
- 時間がかかるのは覚悟してください。機械学習する時間はもちろん、そのためのデータを集めるために多大な時間がかかるためです。
あと、今回の試行の先を頑張ってみようという皆様へのヒントを。
- 他の自動車が参加するとマルチ・エージェントになるので、難易度が跳ね上がります。multi agentとreinforcement learningで検索するといろいろ見つかりますから、参考にしてみてください(私はまだ調べてないので私には聞かないで。でも、面白そうなのがあったら教えてください)。
- 簡単なタスクから複雑なタスクへと階層化する、階層型強化学習が使えるかもしれません(私は階層型強化学習をやったことないので、分かりませんけど)。
- 階層化ではなく、解くべきタスクをだんだん複雑にしていくというカリキュラム強化学習でも、良い感じの性能が出るかもしれません。どんなカリキュラムを作れば良いのかで、また悩むことになりますけど。あと、新しいことを覚えたら前に覚えたことを忘れてしまうという問題にも注意してください。
- 本稿では触れなかった(私ではどんなモデルを作ればよいのか分からなかった)モデル・ベース学習だと、AlphaZeroの例から考えればより高度なことができるかもしれません。
- 逆強化学習という、人間等が作成した成功例のデータを活用するやり方もあるみたいです。逆強化学習の一つのGAIL(Generative Adversarial Imitation Learning)は、GAN(Generative Adversarial Networks)の形をしていてかっこいいです。
- 数学大好きクラスタの方であれば、数式から導いた適切なハイパー・パラメーターで精度向上とか、最新の論文を読んでアルゴリズムを独自実装しちゃうとか、新しい深層強化学習のアルゴリズムを考えて論文を発表しちゃって脚光を浴びるとかできるんだろうなぁ。羨ましいなぁ。
- 小さくて単純な目的(他の自動車や障害物やスターのない環境で「これこれの地点まで最終的な速度や方向がこんな感じになるように移動する」とか)を実現するための方策だけを深層強化学習でやって、ゲーム上でどのような目的を設定するかは自前のアルゴリズムで決めるというやり方もいいかもしれません。操作性に難がある自動車をいい感じに制御するという部分だけを深層強化学習で実現して、自動車に何をせせるのかは独自のやり方で頑張る方式ですね。
- 私がDQNのところで書いた「深層強化学習で人間のプレイヤーよりもハイスコアを出した」に類した記述は、ごめんなさい、ミス・リードを誘う誤った書き方です。対戦格闘ゲームとかでの、深層強化学習を使用しないで普通に作られた敵プレイヤーAIでは、人間よりも強いなんてのは簡単に実現可能で、どうやって自然に見えるように弱くするかで苦労していたりします。だから、モデル・フリーの深層強化学習では、今のところ「ゲームのプレイ方法をプログラミングしていないのに解けた」ところが凄いだけなんです。ゲームの強さは、あまり凄くないんですな。本稿で深層強化学習を勧めておいてアレなのですけど、深層強化学習を使わないで普通にプログラムを組んでも、十分に強いAIを作れると思いますよ。
ともあれ、深層学習や深層強化学習はとても楽しいです。楽しみながら、深層強化学習をやってみてください。
……えっと、深層強化学習はまったく使えないという誤解が発生しそうなので、補足です。簡単な問題なら、深層強化学習はとても役に立ちますよ。OpenAI Gymの環境を作り直して、移動(明るい丸が移動先で、暗い丸はその次の移動先)だけをやればよい問題で深層強化学習した場合の結果は、以下のようになりました。

かなりスゴイでしょ? 報酬は移動先に達した場合は100で、中間報酬は移動先との距離の差。遠ざかった場合や速度が遅い場合の考慮なしの簡単設計です。あと、簡単な問題なので乱数のシードを固定しなくても学習できましたから、どんな盤面でも華麗なドライビングを決めています。やっぱり、深層強化学習はとても楽しいですな。