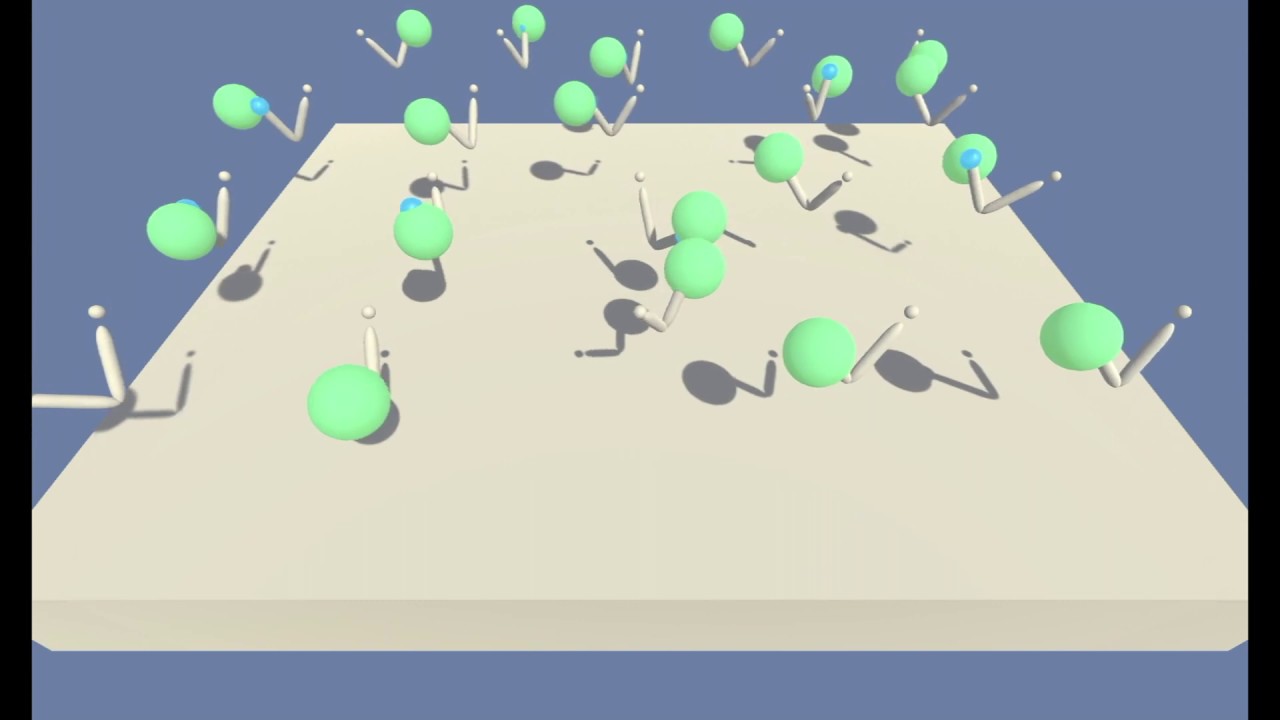
In this environment, a double-jointed arm can move to target locations. A reward of +0.1 is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. A sample observation looks like this :
0.00000000e+00 -4.00000000e+00 0.00000000e+00 1.00000000e+00
-0.00000000e+00 -0.00000000e+00 -4.37113883e-08 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 -1.00000000e+01 0.00000000e+00
1.00000000e+00 -0.00000000e+00 -0.00000000e+00 -4.37113883e-08
0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 5.75471878e+00 -1.00000000e+00
5.55726671e+00 0.00000000e+00 1.00000000e+00 0.00000000e+00
-1.68164849e-01Each action is a vector with 4 numbers, corresponding to torque applicable to two joints. Every entry in the action vector should be a number between -1 and 1.
The Environment is considered solved if the average score for 100 consecutive episode reaches +30. In the case that there are multiple agents in the environment, the score for each episode is the average score between each agent presented in the environment.
The environment is solvable with Deep Deterministic Policy Gradient (DDPG) algorithm. For benchmarking purposes, a PPO agent is also trained on the Multiple-Arm version of the environment. The code for PPO is heavily inspired by the Dulat Yerzat's RL-Advanture2 repository.
- Use
DDPG-Train.ipynbnotebook for Training a DDPG agent. - Use
PPO-Train.ipynbnotebook for Training a PPO agent. - Use
DDPG-Test.ipynbnotebook for Testing a trained PPO agent. - Use
PPO-Test.ipynbnotebook for Testing a trained DDPG agent. - For Report check out
Report.ipynbnotebook.
agents.pycontains a code for a PPO and DDPG Agent.brains.pycontains the definition of Neural Networks (Brains) used inside an Agent.
TrainedAgentsfolder contains saved weights for trained agents.Benchmarkfolder contains saved weights and scores for benchmarking.Imagesfolder contains images used in the notebooks.Moviesfolder contains recorded movies from each Agent.
It is highly recommended to create a separate python environment for running codes in this repository. The instructions are the same as in the Udacity's Deep Reinforcement Learning Nanodegree Repository. Here are the instructions:
-
Create (and activate) a new environment with Python 3.6.
- Linux or Mac:
conda create --name drlnd python=3.6 source activate drlnd- Windows:
conda create --name drlnd python=3.6 activate drlnd
-
Follow the instructions in this repository to perform a minimal install of OpenAI gym.
-
Here are quick commands to install a minimal gym, If you ran into an issue, head to the original repository for latest installation instruction:
pip install box2d-py pip install gym
- Clone the repository (if you haven't already!), and navigate to the
python/folder. Then, install several dependencies.
git clone https://github.com/taesiri/udacity_drlnd_project2
cd udacity_drlnd_project2/
pip install .- Create an IPython kernel for the
drlndenvironment.
python -m ipykernel install --user --name drlnd --display-name "drlnd"- Open the notebook you like to explore.
See it in action here: