❗ SuperVessel upgrade is coming ❗
Start Date: 9-Jan-2019 8:00 am EST
End Date: 18-Jan-2019 8:00 am EST (All data will be deleted)
The hardware and software in NY site will be updated to the latest version, all users' dataset will be CLEANED.
Please back up important data immediately, all data will be permanently deleted after January 18th.
If you have any problems after this time frame with regard to connectivity, or if you have any questions regarding the >maintenance at any point, please mail to help@ptopenlab.com .
We appreciate your patience during this work and welcome any feedback.
Thank you.

Whether you are counting cars on a road or products on a conveyer belt, there are many use cases for computer vision with video. With video as input, automatic labeling can be used to create a better classifier with less manual effort. This Code Pattern shows you how to create and use a classifier to identify objects in motion and then track the objects and count them as they enter designated regions of interest.
In this Code Pattern, we will create a video car counter using PowerAI Vision Video Data Platform, OpenCV and a Jupyter Notebook. We'll use a little manual labeling and a lot of automatic labeling to train an object classifier to recognize cars on a highway. We'll load another car video into a Jupyter Notebook where we'll process the individual frames and annotate the video.
We'll use our deployed model for inference to detect cars on a sample of the frames at a regular interval. We'll use OpenCV to track the cars from frame to frame in between inference. In addition to counting the cars as they are detected, we'll also count them as they cross a "finish line" for each lane and show cars per second.
Credit goes to Michael Hollinger for his initial notebook counting objects with the PowerAI Vision Video Data Platform.
When the reader has completed this Code Pattern, they will understand how to:
- Use automatic labeling to create an object detection classifier from a video
- Process frames of a video using a Jupyter Notebook, OpenCV, and PowerAI Vision
- Detect objects in video frames with PowerAI Vision
- Track objects from frame to frame with OpenCV
- Count objects in motion as they enter a region of interest
- Annotate a video with bounding boxes, labels and statistics

- Upload a video using the PowerAI Vision web UI.
- Use automatic labeling and train a model.
- Deploy the model to create a PowerAI Vision inference API.
- Use a Jupyter Notebook to detect, track, and count cars in a video.
- IBM Power Systems: A server built with open technologies and designed for mission-critical applications.
- IBM Power AI: A software platform that makes deep learning, machine learning, and AI more accessible and better performing.
- IBM PowerAI Vision Technology Preview: A complete ecosystem for labeling datasets, training, and deploying deep learning models for computer vision.
- Jupyter Notebook: An open source web application that allows you to create and share documents that contain live code, equations, visualizations, and explanatory text.
- OpenCV: Open source computer vision library.
- Nimbix Cloud Computing Platform: An HPC & Cloud Supercomputing platform enabling engineers, scientists & developers, to build, compute, analyze, and scale simulations in the cloud.
- Artificial Intelligence: Artificial intelligence can be applied to disparate solution spaces to deliver disruptive technologies.
- Cloud: Accessing computer and information technology resources through the Internet.
- Data Science: Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
- Mobile: Systems of engagement are increasingly using mobile technology as the platform for delivery.
- Python: Python is a programming language that lets you work more quickly and integrate your systems more effectively.

This Code Pattern was built with the PowerAI Vision Technology Preview v3.0.
NOTE: The steps and examples in this README assume you are using SuperVessel. To download and install the technology preview on-premise instead, refer to Download PowerAI Vision technology preview.
- To try the preview using the
SuperVesselcloud, login or register here.
The code included in this Code Pattern runs in a Jupyter Notebook. The notebook itself does not require PowerAI or Power Systems (only access to the deployed API). To run the Jupyter Notebook locally, install it using Anaconda. The installation instructions are here.
- Create a dataset in Video Data Platform
- Train and deploy
- Automatic labeling
- Train and deploy
- Run the notebook
- Create the annotated video
Hint: If you need a shortcut, you can import the dataset from
data/examples/dataset_auto_labeled.zip, train and deploy that dataset, and then run the notebook (but you'll get more out of this if you go through all the steps).
To create a new dataset for object detection training from a video, use PowerAI Video Data Platform and start with a small manually annotated dataset (we'll expand on it with automatic labeling later).
-
Download the video to use to train the dataset from here. Use the
Downloadbutton to createtraining_video.mp4in your browser's Downloads folder. -
Go to Video Data Platform and click on the
DataSetcard.
-
Click on
Create DataSet, provide a name and description, and clickConfirm. -
Use the dataset's operation button
☰for your dataset and selectManage Videosin the drop-down list.
-
Use the
Upload Videobutton to upload thetraining_video.mp4from above. -
Use the video's operation button
☰and selectAdd Labelin the drop-down list.
-
Type
carin theNeed More Tag? Input and Press enter...box and press enter. Thecartag is then added to theTagdrop-down list so you can start tagging cars.
-
Do manual tagging for at least 5 frames.
- Keep the
cartag shown in theTagbox. - Use the
Capture Framecamera icon to capture a frame. - Drag a bounding box around each car in the frame.
- Press the
Savebutton to save the annotated frame. - Click on the video to let it play and then pause on another frame.
- Capture, tag and save at least 5 frames annotated with at least 25 cars.
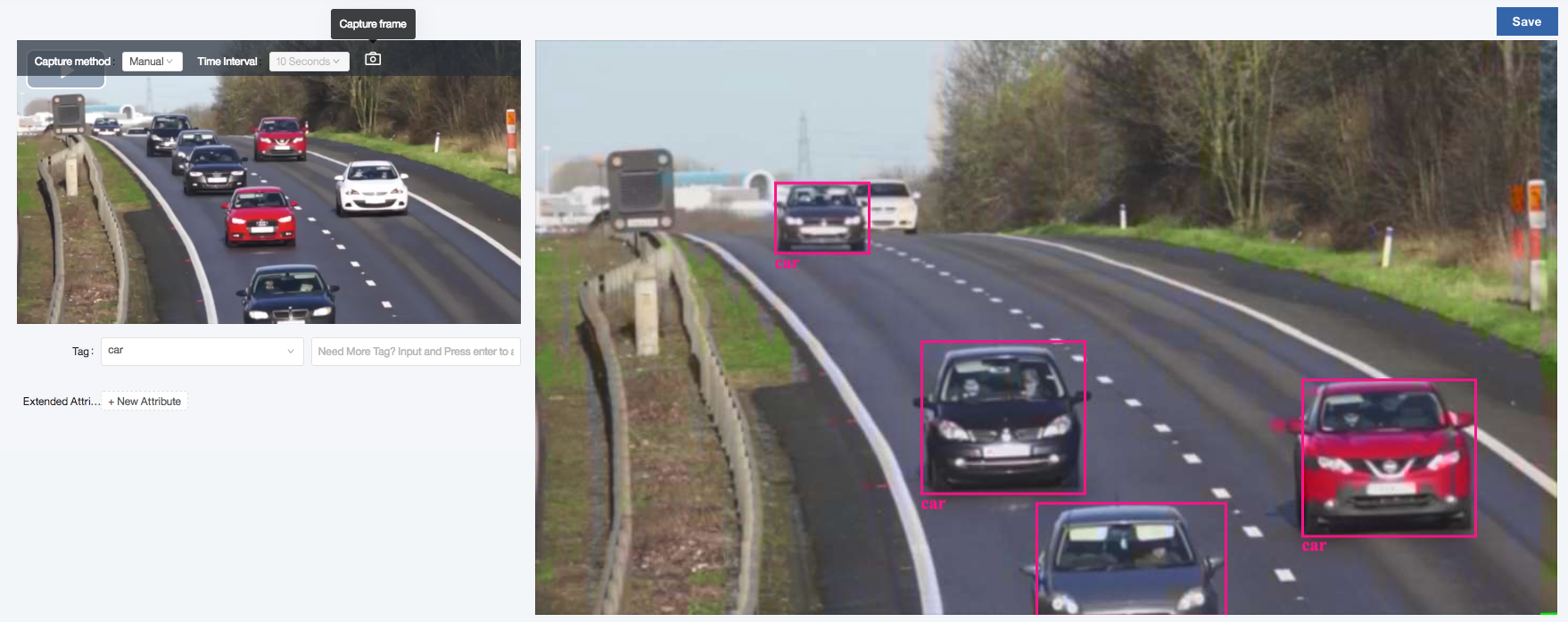
- Keep the
-
Use the breadcrumb to go back to
Video Management.
-
Use the video's operation button
☰and selectExport Labelsin the drop-down list.







We need to train and deploy the model so that we can use it (for automatic labeling).
-
Go to https://ny1.ptopenlab.com/AIVision/index.html#!/datasets. The dataset that you just created by exporting labels should be at the top of the list. Note the timestamp to make sure you know which dataset is the one you just created.
-
Click on
My DL Tasksunder My Workspace and then click theCreate New Taskbutton. Click onObject Detection. -
Give the Object Detector a name and make sure your dataset is selected, then click
Build Model.
-
A confirmation dialog will give you a time estimate. Click
Create New Taskto get it started. -
When the model is built, click on
Deploy and Test.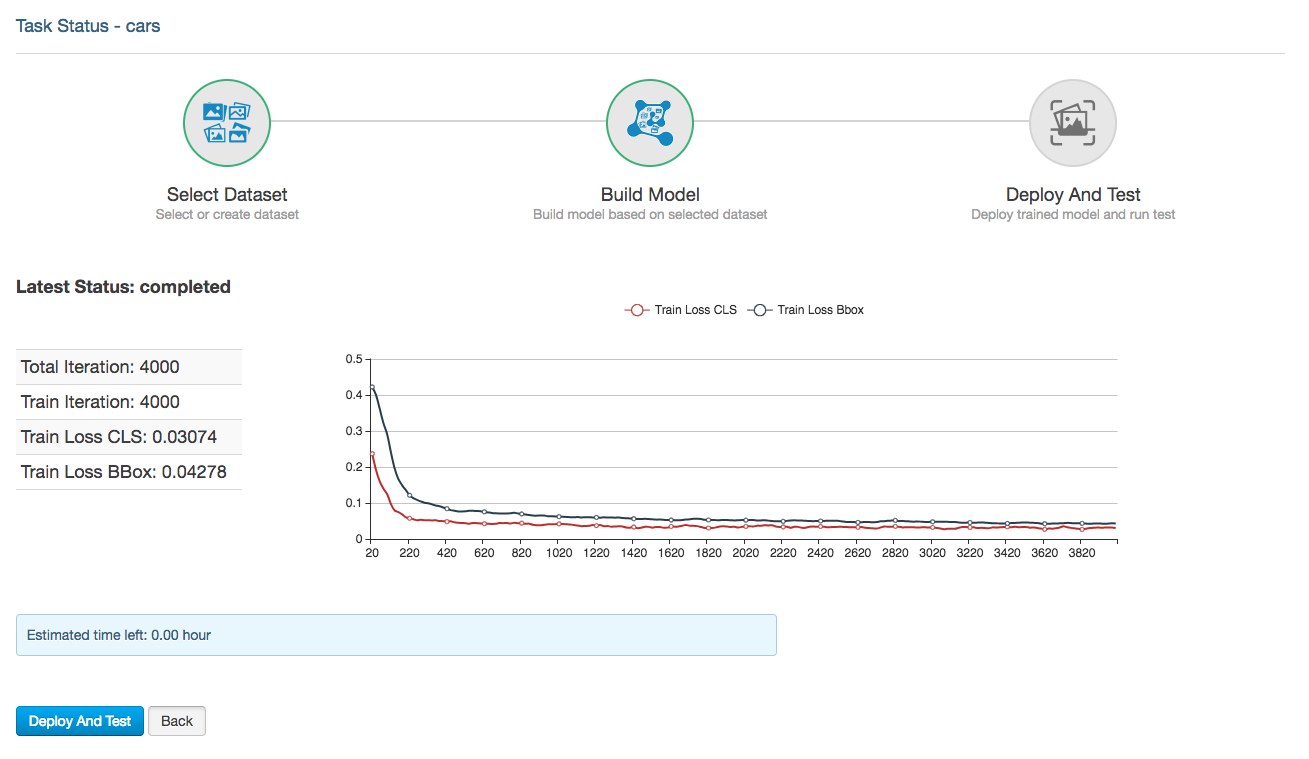
-
If/when you want to deploy/redeploy later, just click the
Deploybutton next to your trained model here: https://ny1.ptopenlab.com/AIVision/#!/trained-models.


We use the model that you trained with 5 or more manually annotated frames and use inference to automatically label more cars in your training video.
-
Use the sidebar to go back to
Video Data Platform. -
Use the video's operation button
☰and selectAuto Labelingin the drop-down list.
-
Click on the
Object to detectdrop-down list and selectcar. This API will be available while your car model is deployed.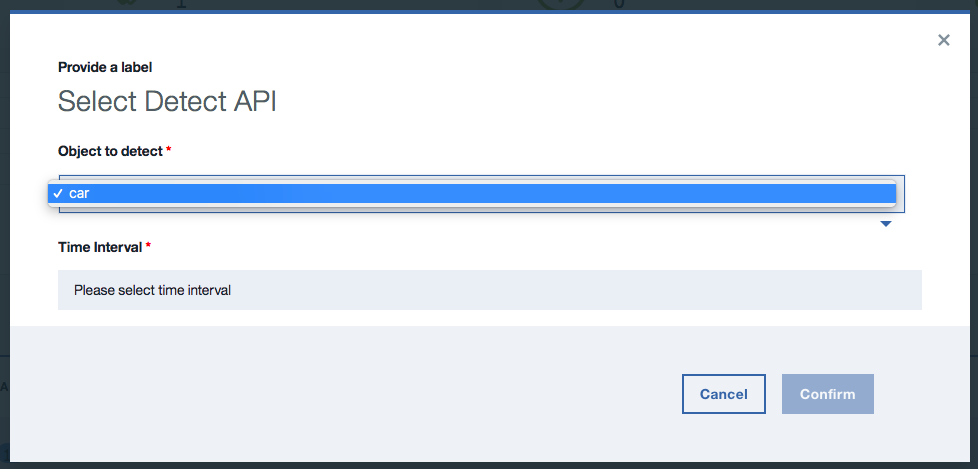
-
Use the
Time Intervaldrop-down list to select an interval. Use 1 second for our short video. -
Click
Confirm. -
You can watch the progress as the number under auto label increases and the progress bar shows you the auto labeling progress.

-
When the task completes, use the video's operation button
☰and selectValidateto review the auto labeling.



Export the labels again and repeat the above train and deploy process with the newest dataset which was enhanced with automatic labeling.
- Export labels
- Build model
- Deploy
This dataset has many more frames and labeled objects. It will create a much more accurate model.
The code included in this Code Pattern runs in a Jupyter Notebook. After you configure the URL of your deployed model in the notebook, you can just run it, read it, and watch the results.
-
Start your Jupyter Notebooks. Starting in your
powerai-counting-carscloned repo directory will help you find the notebook and the output as described below. Jupyter Notebooks will open in your browser.cd powerai-counting-cars jupyter notebook -
Navigate to the
notebooksdirectory and open the notebook file namedcounting_cars.ipynbby clicking on it.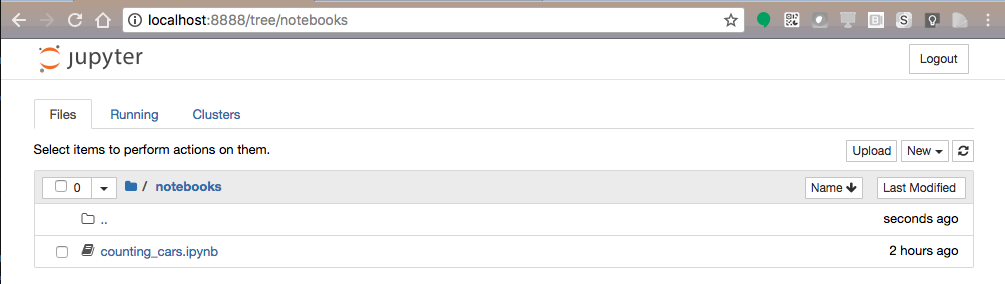
-
Edit the cell below Required setup! to replace your-guid-here with the ID of your deployed model. If you are not running on SuperVessel, edit the host name too.

-
Use the drop-down menu
Cell > Run Allto run the notebook, or run the cells one at a time top-down using the play button.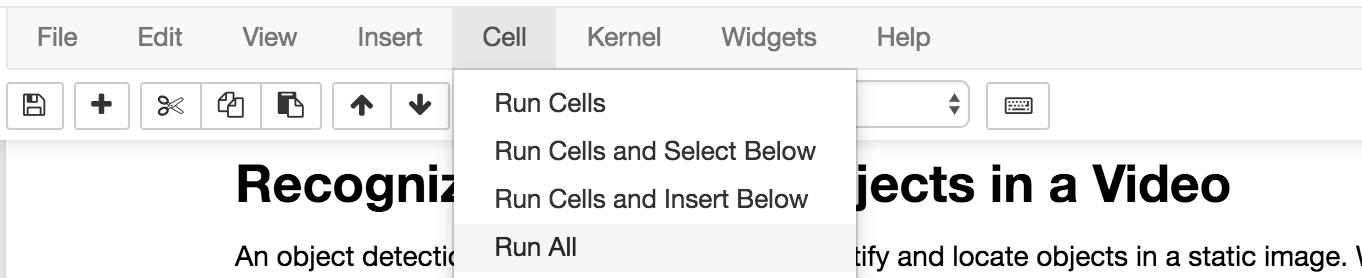
-
As the cells run, watch the output for results or errors. A running cell will have a label like
In [*]. A completed cell will have a run sequence number instead of the asterisk. -
The Test the API on a single frame cell will demonstrate that you have correctly deployed your inference API. It should output JSON that includes classified cars. A portion of the output would look something like this:
"classified": [ { "confidence": 0.9997443556785583, "ymax": 370, "label": "car", "xmax": 516, "xmin": 365, "ymin": 240 } ]
-
The Get object detection results for sampled frames cell runs inference on a sampling of the video frames. The output will show a progress counter like this:

-
The Inference, tracking, and annotation cell processes every frame and has a similar progress counter. You can also preview the annotated frames as they are created in the
outputdirectory. -
The Play the annotated frames in the notebook cell displays the annotated frames in a loop to demonstrate the new video after they are all created. The notebook animation is usually slower than the video.




You can create an MP4 video from the annotated frames if you have a working installation of ffmpeg. The command is commented out as the last cell of the notebook. You can run it from there, or use the script in tools/create_video.sh. The script takes the output directory (with the annotated frames) as an argument like this:
cd powerai-counting-cars
./tools/create_video.sh notebooks/outputNote: There is also a tool to create a gif from the video. We used that to show the sample output below.
As the notebook cells run, check for errors and watch the progress indicators. After the video has been annotated, the frames will play (like a video) in the notebook. The notebook playback is usually slow. If you used ffmpeg to create an annotated video, you can play it back at full speed.
Example annotated video: here
Example notebook with static output: here
Example compressed and converted to gif:
-
Stopped adding cars.
If you are using the shared SuperVessel environment, your model deployment may be limited to 1 hour. Simply deploy the model again and run the notebook over (or from where the errors started). Using cached results allows the notebook to continue where it left off. To deploy/redeploy the model, just click the
Deploybutton next to your trained model here: https://ny1.ptopenlab.com/AIVision/#!/trained-models.
- Computer vision: Read about computer vision on Wikipedia.
- Object detection: Read about object detection on Wikipedia.
- Artificial intelligence: Can artificial intelligence identify pictures better than humans?
- From the developers: IBM PowerAI Vision speeds transfer learning with greater accuracy — a real world example.
- Artificial intelligence and machine learning: Build artificial intelligence functions into your app.
- Artificial Intelligence Code Patterns: Enjoyed this Code Pattern? Check out our other AI Code Patterns.
- AI and Data Code Pattern Playlist: Bookmark our playlist with all of our Code Pattern videos
- PowerAI: Get started or get scaling, faster, with a software distribution for machine learning running on the Enterprise Platform for AI: IBM Power Systems
This code pattern is licensed under the Apache License, Version 2. Separate third-party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 and the Apache License, Version 2.