A PyTorch implementation of "SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient." (Yu, Lantao, et al.). The code is highly simplified, commented and (hopefully) straightforward to understand. The policy gradients implemented are also much simpler than in the original work (https://github.com/LantaoYu/SeqGAN/) and do not involve rollouts- a single reward is used for the entire sentence (inspired by the examples in http://karpathy.github.io/2016/05/31/rl/).
The architectures used are different than those in the orignal work. Specifically, a recurrent bidirectional GRU network is used as the discriminator.
The code performs the experiment on synthetic data as described in the paper.
You are encouraged to raise any doubts regarding the working of the code as Issues.
To run the code:
python main.pymain.py should be your entry point into the code.
The following hacks (borrowed from https://github.com/soumith/ganhacks) seem to have worked in this case:
-
Training Discriminator a lot more than Generator (Generator is trained only for one batch of examples, and increasing the batch size hurts stability)
-
Using Adam for Generator and Adagrad for Discriminator
-
Tweaking learning rate for Generator in GAN phase
-
Using dropout in both training and testing phase
-
Stablity is extremely sensitive to almost every parameter :/
-
The GAN phase may not always lead to massive drops in NLL (sometimes very minimal) - I suspect this is due to the very crude nature of the policy gradients implemented (without rollouts).
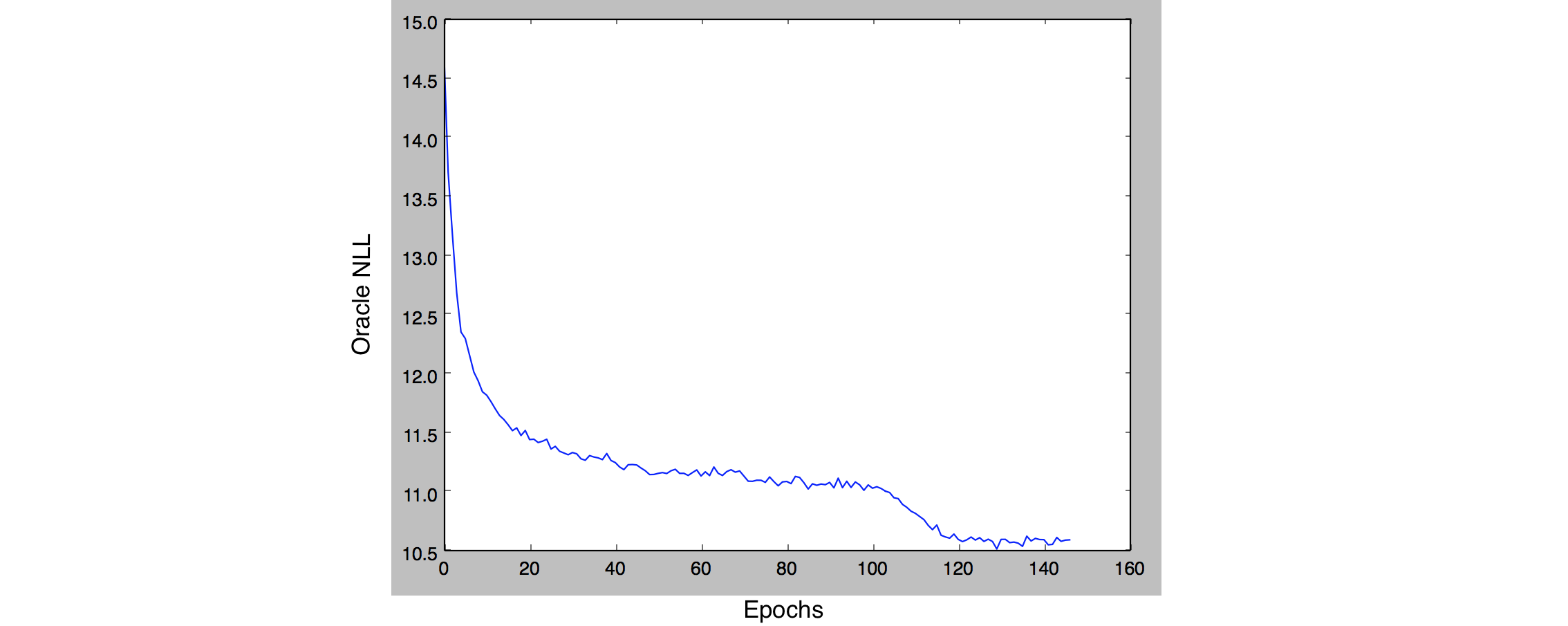
Learning curve obtained after MLE training for 100 epochs followed by adversarial training. (Your results may vary!)