A collection of papers and resources about the utilization of large language models (LLMs) in software testing.
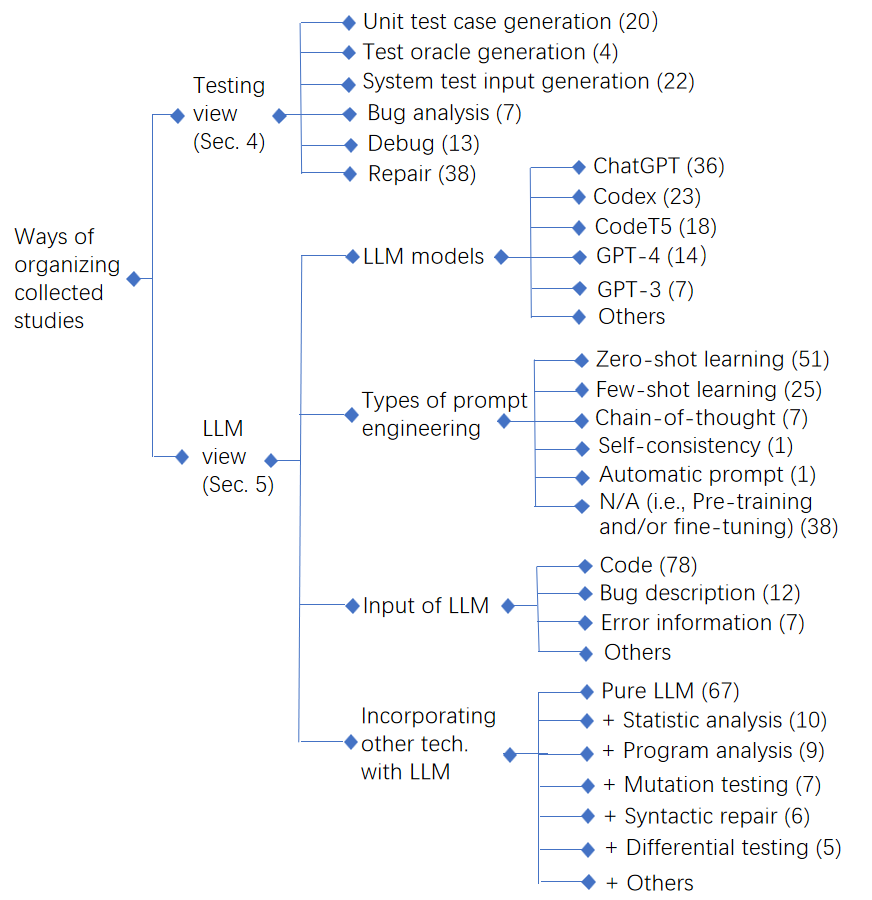
Software testing is a critical task that is essential for ensuring the quality and reliability of software products. As software systems become increasingly complex, new and more effective software testing techniques are needed. Recently, large language models (LLMs) have emerged as a breakthrough technology in natural language processing and artificial intelligence. These models are capable of performing various coding-related tasks, including code generation and code recommendation. Therefore, the use of LLMs in software testing is expected to yield significant improvements. On one hand, software testing involves tasks such as unit test generation that require code understanding and generation. On the other hand, LLMs can generate diverse test inputs to ensure comprehensive coverage of the software being tested. In this repository, we present a comprehensive review of the utilization of LLMs in software testing. We have collected 102 relevant papers and conducted a thorough analysis from both software testing and LLMs perspectives, as summarized in Figure 1.
We hope this repository can help researchers and practitioners to get a better understanding of this emerging field. If this repository is helpful for you, please help us by citing this paper:
@article{Wang2023SoftwareTW,
title={Software Testing with Large Language Model: Survey, Landscape, and Vision},
author={Junjie Wang and Yuchao Huang and Chunyang Chen and Zhe Liu and Song Wang and Qing Wang},
journal={ArXiv},
year={2023},
volume={abs/2307.07221},
url={https://api.semanticscholar.org/CorpusID:259924919}
}
This project is under development. You can hit the STAR and WATCH to follow the updates.
- Our LLM for mobile GUI testing paper: Make LLM a Testing Expert: Bringing Human-like Interaction to Mobile GUI Testing via Functionality-aware Decisions is accepted by ICSE 2024. Note that, it is a follow-up work of Chatting with GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing.
- Our LLM for text input fuzzing paper: Testing the Limits: Unusual Text Inputs Generation for Mobile App Crash Detection with Large Language Model is accepted by ICSE 2024.
- Our LLM for crash reproduction paper: CrashTranslator: Automatically Reproducing Mobile Application Crashes Directly from Stack Trace is accepted by ICSE 2024.
- Our LLM for semantic text input generation paper: Fill in the Blank: Context-aware Automated Text Input Generation for Mobile GUI testing is published in ICSE 2023.
- Our roadmap paper:Software Testing with Large Language Models: Survey, Landscape, and Vision is now public.

We find that LLMs have proven to be efficient in the mid to late stages of the software testing lifecycle. During the mid-phase of software testing, LLMs have been successfully applied for various test case preparation tasks, including the generation of unit test cases, test oracle generation, and system test input generation. In later phases, such as the bug fix phase and the preparation of test reports/bug reports, LLMs have been utilized for tasks like bug analysis, debugging, and repair.
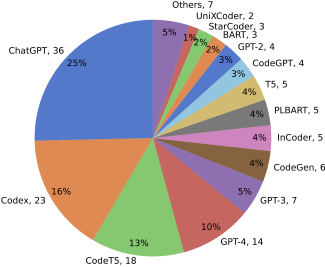
In our collected studies, the LLM most frequently employed is ChatGPT, widely recognized and popular for its exceptional performance across various tasks. The second most commonly used LLM is Codex, trained on an extensive code corpus, aiding researchers in coding-related tasks. Ranked third is CodeT5, an open-source LLM capable of conducting pre-training and fine-tuning with domain-specific data, thereby achieving better performance.
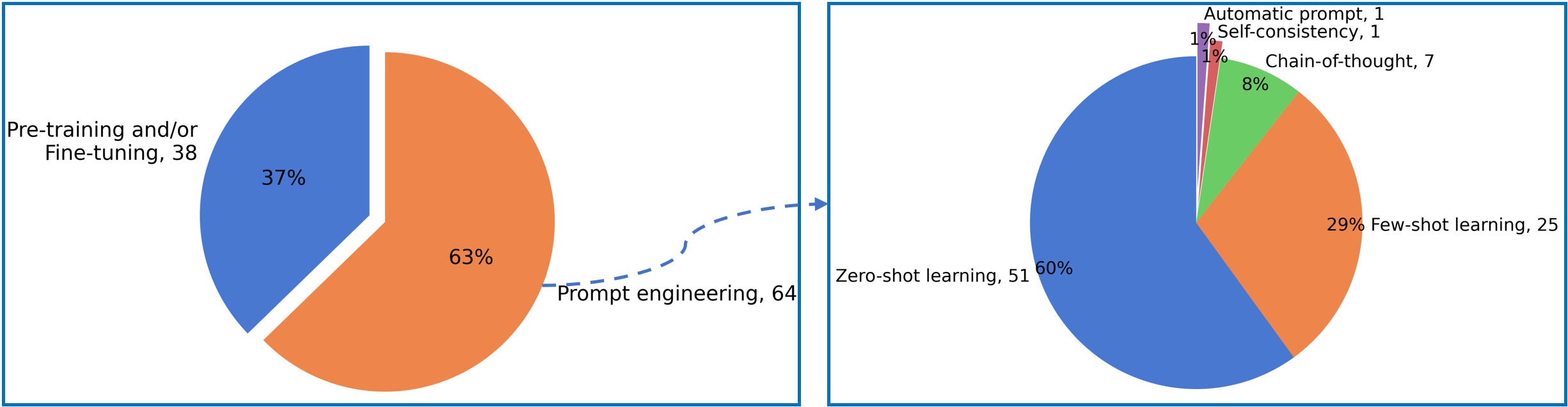
In our collected studies, 38 studies utilize the LLMs through pre-training or fine-tuning schema, while 64 studies employ the prompt engineering to communicate with LLMs to steer its behavior for desired outcomes without updating the model weights. Among them, 51 studies involve zero-shot learning, and 25 studies involve few-shot learning. There are also studies involving the chain-of-thought (7 studies), self-consistency (1 study), and automatic prompt (1 study).
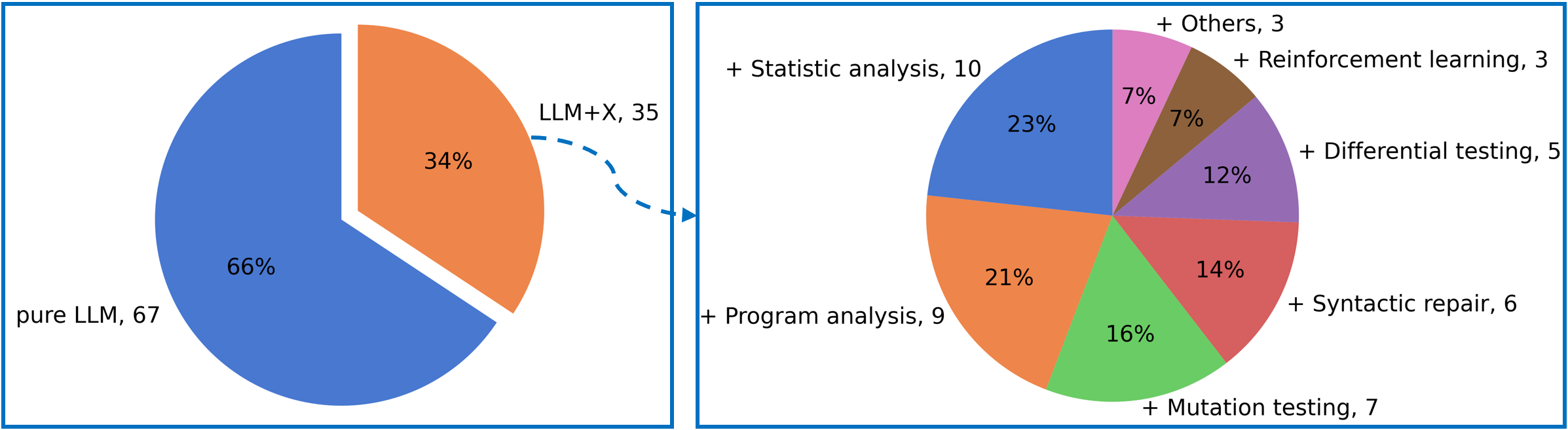
In our collected studies, 67 of them utilize LLMs to address the entire testing task, while 35 studies incorporate additional techniques. These techniques include mutation testing, differential testing, syntactic checking, program analysis, statistical analysis, etc. .
- Large Language Models for Software Engineering A Systematic Literature Review (in Arxiv)
- Large Language Models for Software Engineering Survey and Open Problems (in Arxiv)
- Large Language Models Meet NL2Code A Survey (in ACL 2023)
- Unit Test Case Generation with Transformers and Focal Context (in Arxiv)
- Codet: Code Generation with Generated Tests (in ICLR 2023)
- Interactive Code Generation via Test-Driven User-Intent Formalization (in Arxiv)
- A3Test: Assertion-Augmented Automated Test Case Generation (in Arxiv)
- An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation (in Arxiv)
- An Initial Investigation of ChatGPT Unit Test Generation Capability (in SAST 2023)
- Automated Test Case Generation Using Code Models and Domain Adaptation (in Arxiv)
- Automatic Generation of Test Cases based on Bug Reports: a Feasibility Study with Large Language Models (in Arxiv)
- Can Large Language Models Write Good Property-Based Tests? (in Arxiv)
- CAT-LM Training Language Models on Aligned Code And Tests (in ASE 2023)
- ChatGPT vs SBST: A Comparative Assessment of Unit Test Suite Generation (in Arxiv)
- ChatUniTest: a ChatGPT-based Automated Unit Test Generation Tool (in Arxiv)
- CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models (in ICSE 2023)
- Effective Test Generation Using Pre-trained Large Language Models and Mutation Testing (in Arxiv)
- Exploring the Effectiveness of Large Language Models in Generating Unit Tests (in Arxiv)
- How Well does LLM Generate Security Tests? (in Arxiv)
- No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation (in Arxiv)
- Prompting Code Interpreter to Write Better Unit Tests on Quixbugs Functions (in Arxiv)
- Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation (in Arxiv)
- Unit Test Generation using Generative AI: A Comparative Performance Analysis of Autogeneration Tools (in Arxiv)
- Generating Accurate Assert Statements for Unit Test Cases Using Pretrained Transformers (in AST 2022)
- Learning Deep Semantics for Test Completion (in ICSE 2023)
- Using Transfer Learning for Code-Related Tasks (in TSE 2022)
- Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning (in ICSE 2023)
- Automated Conformance Testing for JavaScript Engines via Deep Compiler Fuzzing (in PLDI 2021)
- Fill in the Blank: Context-aware Automated Text Input Generation for Mobile GUI Testing (in ICSE 2023)
- Large Language Models are Pretty Good Zero-Shot Video Game Bug Detectors (in Arxiv)
- Slgpt: Using Transfer Learning to Directly Generate Simulink Model Files and Find Bugs in the Simulink Toolchain (in EASE 2021)
- Augmenting Greybox Fuzzing with Generative AI (in Arxiv)
- Automated Test Case Generation Using T5 and GPT-3 (in ICACCS 2023)
- Automating GUI-based Software Testing with GPT-3 (in ICSTW 2023)
- AXNav: Replaying Accessibility Tests from Natural Language (in Arxiv)
- Can ChatGPT Advance Software Testing Intelligence? An Experience Report on Metamorphic Testing (in Arxiv)
- Efficient Mutation Testing via Pre-Trained Language Models (in Arxiv)
- Large Language Models are Edge-Case Generators:Crafting Unusual Programs for Fuzzing Deep Learning Libraries (in ICSE 2024)
- Large Language Models are Zero Shot Fuzzers: Fuzzing Deep Learning Libraries via Large Language Models (in ISSTA 2023)
- Large Language Models for Fuzzing Parsers (Registered Report) (in FUZZING 2023)
- LLM for Test Script Generation and Migration: Challenges, Capabilities, and Opportunities (in Arxiv)
- Make LLM a Testing Expert: Bringing Human-like Interaction to Mobile GUI Testing via Functionality-aware Decisions (in ICSE 2024)
- PentestGPT: An LLM-empowered Automatic Penetration Testing Tool (in Arxiv)
- SMT Solver Validation Empowered by Large Pre-Trained Language Models (in ASE 2023)
- TARGET: Automated Scenario Generation from Traffic Rules for Testing Autonomous Vehicles (in Arxiv)
- Testing the Limits: Unusual Text Inputs Generation for Mobile App Crash Detection with Large Language Model (in ICSE 2024)
- Understanding Large Language Model Based Fuzz Driver Generation (in Arxiv)
- Universal Fuzzing via Large Language Models (in ICSE 2024)
- Variable Discovery with Large Language Models for Metamorphic Testing of Scientific Software (in SANER 2023)
- White-box Compiler Fuzzing Empowered by Large Language Models (in Arxiv)
- Itiger: an Automatic Issue Title Generation Tool (in FSE 2022)
- CrashTranslator: Automatically Reproducing Mobile Application Crashes Directly from Stack Trace (in ICSE 2024)
- Cupid: Leveraging ChatGPT for More Accurate Duplicate Bug Report Detection (in Arxiv)
- Employing Deep Learning and Structured Information Retrieval to Answer Clarification Questions on Bug Reports (in Arxiv)
- Explaining Software Bugs Leveraging Code Structures in Neural Machine Translation (in ICSE 2023)
- Prompting Is All Your Need: Automated Android Bug Replay with Large Language Models (in ICSE 2024)
- Still Confusing for Bug-Component Triaging? Deep Feature Learning and Ensemble Setting to Rescue (in ICPC 2023)
- Detect-Localize-Repair: A Unified Framework for Learning to Debug with CodeT5 (in EMNLP 2022)
- Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction (in ICSE 2023)
- A Preliminary Evaluation of LLM-Based Fault Localization (in Arxiv)
- Addressing Compiler Errors: Stack Overflow or Large Language Models? (in Arxiv)
- Can LLMs Demystify Bug Reports? (in Arxiv)
- Dcc --help: Generating Context-Aware Compiler Error Explanations with Large Language Models (in SIGCSE 2024)
- Explainable Automated Debugging via Large Language Model-driven Scientific Debugging (in Arxiv)
- Large Language Models for Test-Free Fault Localization (in ICSE 2024)
- Large Language Models in Fault Localisation (in Arxiv)
- LLM4CBI: Taming LLMs to Generate Effective Test Programs for Compiler Bug Isolation (in Arxiv)
- Nuances are the Key: Unlocking ChatGPT to Find Failure-Inducing Tests with Differential Prompting (in ASE 2023)
- Teaching Large Language Models to Self-Debug (in Arxiv)
- A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair (in Arxiv)
- Using Transfer Learning for Code-Related Tasks (in TSE 2022)
- Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning (in ICSE 2023)
- A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair (in Arxiv)
- Examining Zero-Shot Vulnerability Repair with Large Language Models (in SP 2023)
- Automated Repair of Programs from Large Language Models (in ICSE 2023)
- Fix Bugs with Transformer through a Neural-Symbolic Edit Grammar (in Arxiv)
- Practical Program Repair in the Era of Large Pre-trained Language Models (in ICSE 2023)
- Repairing Bugs in Python Assignments Using Large Language Models (in Arxiv)
- Towards JavaScript Program Repair with Generative Pre-trained Transformer (GPT-2) (in APR 2022)
- An Analysis of the Automatic Bug Fixing Performance of ChatGPT (in APR 2023)
- An Empirical Study on Fine-Tuning Large Language Models of Code for Automated Program Repair (in ASE 2023)
- An Evaluation of the Effectiveness of OpenAI's ChatGPT for Automated Python Program Bug Fixing using QuixBugs (in iSemantic 2023)
- An Extensive Study on Model Architecture and Program Representation in the Domain of Learning-based Automated Program Repair (in APR 2023)
- Can OpenAI's Codex Fix Bugs? An Evaluation on QuixBugs (in APR 2022)
- CIRCLE: Continual Repair Across Programming Languages (in ISSTA 2022)
- Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback (in Arxiv)
- Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Automated Program Repair (in FSE 2023)
- Domain Knowledge Matters: Improving Prompts with Fix Templates for Repairing Python Type Errors (in ICSE 2024)
- Enhancing Genetic Improvement Mutations Using Large Language Models (in SSBSE 2023)
- FixEval: Execution-based Evaluation of Program Fixes for Programming Problems (in APR 2023)
- Fixing Hardware Security Bugs with Large Language Models (in Arxiv)
- Fixing Rust Compilation Errors using LLMs (in Arxiv)
- Framing Program Repair as Code Completion (in ICSE 2022)
- Frustrated with Code Quality Issues? LLMs can Help! (in Arxiv)
- GPT-3-Powered Type Error Debugging: Investigating the Use of Large Language Models for Code Repair (in SLE 2023)
- How Effective Are Neural Networks for Fixing Security Vulnerabilities (in ISSTA 2023)
- Impact of Code Language Models on Automated Program Repair (in ICSE 2023)
- Inferfix: End-to-end Program Repair with LLMs (in FSE 2023)
- Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT (in Arxiv)
- Neural Program Repair with Program Dependence Analysis and Effective Filter Mechanism (in Arxiv)
- Out of Context: How important is Local Context in Neural Program Repair? (in ICSE 2024)
- Pre-trained Model-based Automated Software Vulnerability Repair: How Far are We? (in IEEE Transactions on Dependable and Secure Computing.)
- RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot (in Arxiv)
- RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair (in FSE 2023)
- STEAM: Simulating the InTeractive BEhavior of ProgrAMmers for Automatic Bug Fixing (in Arxiv)
- Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions (in Arxiv)
- VulRepair: a T5-based Automated Software Vulnerability Repair (in FSE 2022)
- What Makes Good In-Context Demonstrations for Code Intelligence Tasks with LLMs? (in ASE 2023)