What I will do with this repository:
- Python basic usage (basic var types, define func & class, etc.);
- Python advanced features (GIL, singleton, @decorator, etc.);
- Powerful built-in modules (multiprocessing, re, threading, etc.);
- Powerful third-party packages (asyncio, requests, selenium, etc.);
-
对象有一个
__str__()方法,打印的时候可以打印对应的字符串 -
slice
-
enumerate, zip
-
range
-
more about super
-
more singleton
-
copy
-
with
-
标识符由字母、数字、下划线组成
-
不能以数字开头
-
区分大小写
-
以下划线开头的标识符是有特殊意义的。以单下划线开头
_foo的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用from xxx import \* 而导入。 -
以双下划线开头的
__foo代表类的私有成员,以双下划线开头和结尾的__foo__代表 Python 里特殊方法专用的标识,如__init__()代表类的构造函数。 -
关键字不能用作常数或变数,或任何其他标识符名称
-
所有 Python 的关键字只包含小写字母。
#单行```, """多行
- python 最具特色的就是用缩进来写模块。
- 缩进的空白数量是可变的,但是所有代码块语句必须包含相同地缩进空白数量,这个必须严格执行。
- 建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用
+-*, **/直接求除数//取整部分,%取余:=边赋值边计算
| 学名 | 符号 | 解释 |
|---|---|---|
| 与 | & | ab都为1则返回1,否则为0 |
| 或 | | | 有一个为1,就返回1 |
| 异或 | ^ | ab不同则返回1,相同返回0 |
| 取反 | ~ | 按位取反 |
| 左移 | << | a<<3,左移三位,高位丢弃,低位补0 |
| 右移 | >> | 同上 |
and, or, not
a is b用于判断内存地址是否一致a == b判断值
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^| | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
-
type(object), isinstance(object, type)可用于判断类型 -
mutable: list, set, dict
-
immutable: number, tuple, string
-
mutable 的对象,如果对对象做了修改,就是在原有内存地址上修改
-
immutable对象的修改,实际上会在另一个内存地址上放置新的数据
-
mutable和immutable是十分具有特色的特征,如果不注意这个特征,可能会带来意外的错误
分成int, float, complex, bool, 但用起来没什么区别
- 常用slice来截取一部分
r""可以避免转义- str.count('a') 返回数量
- str.find(substr, beg, end) 可判断substr是否在str中,返回下标/-1
- str.index() 同上,但不返回-1,而是报错
- isnumeric, isalnum, islower, isdigit等
- strip 截掉空白字符
- replace(old, new)
- split(char), return [str]
f-string的用法:
- 使用大括号替换资源
print(f"name = {name}") - 高效concat
- 右对齐,
f'{x:>10},左对齐<,居中= - 使用特殊字符占位,默认空格
f'{x:->10}' - 格式化浮点数,
f'{x:.2f}' - 转换进制,
f"{int:b}",b-2,o-8,x-16,X-16大写,c-ascii
据说底层是C的array,每个元素都是一个指针
- 可以容纳任何东西,但通常是储存同种类型的元素
- 常用slice, enumerate
- list.append/extend()会在原有基础上增加
- 而 list + another list 会返回一个新的列表
- list.copy()返回一个shallow copy
- pop(), append(), count()
- list.reverse() 返回新列表
- list.sort() 原地修改,而global sorted() 返回新列表
我不喜欢用这个,建议用下面的collections.deque
- 和list差不多,api基本一致,但是deque很方便
- pop, popleft, append, appendleft
- extend, extendleft
- 和list差不多,但是immutable
- 不能修改,但可以连接生成新的tuple
- key 必须是 immutable
dict[key] = value可以用来创建k-vdel dict[key]可以删除一个键- 创建方法除了推导式,还有
dict = dict([ (k1,v1), (k2,v2) ]) - 常用dict.keys(), values(), items()来遍历
- dict是有序的 (>= Python 3.7)
- dict传入的都是真实值,如下:
a = 1
b = a
dct = {a: 'value'}
print(dct[b]) # --> 'value'
print(dct[1]) # --> 'value'Counter继承自dict类型,相当于是一种只用来计数的hashmap。以下是一部分常用操作:
- 可选的初始化:
c=Counter('ababc') - 查询:
c['a'] - 对于一个不存在的键,默认返回0
- 修改:
c['a'] += 1 - 删除:
del c['a'] - 清空:
c.clear() - 总数:
c.total() == sum(c.values()),values是dict的方法 - 合并两个Counter:
c.update(d), d is Counter - 减另一个Counter:
c.subtract(d) - 查询前若干个,未指定则按出现次数排序所有:
c.most_common(k) - 返回键的列表:
sorted(c) - 返回键重复值的次数的列表,如
c.elements() == list("aabbc")
也是继承自dict类型。
- 使用的时候应该是
a = defaultdict(list) - 如果访问一个不存在的key,就会返回一个空列表(根据选择的类型)
- 除了常规赋值,也可以使用
a[1].append(2)这种形式(根据选择的类型)
- 无序的、不重复的、自动去重的序列;
- set.add(), update()
- remove()当元素不存在时会报错,discard()不报错
- pop() 随机弹出一个
- list comprehensions:
[i*2 for i in range(5) if i%2] - dict comprehensions:
{i:i**2 for i in range(5) if i%2} - generator comprehensions:
(i**2 for i in range(5) if i%2)

先介绍一些概念:
- 可迭代协议: 实现了
__iter__()方法 - 迭代器协议: 实现了
__iter__()和__next__()方法 - Iterable, 可迭代对象: 实现了
__iter__()方法的一个类,往往预先知道长度和数据; container:容器通常都是可迭代对象,容器包括list, tuple, dict这些container:容器,只能用来装元素,比如列表、元组。大部分容器都实现了__iter__()方法;但是不实现__next__()方法就不能 取 元素;- Iterator, 迭代器: 继承自
iterable,实现了__iter__()和__next__()方法的类。是惰性的,只有通过next才能返回元素; - 惰性:通过next来一个一个地返回里面的元素
- next(iterator)只能单向前进,长江黄河不会倒流
- 内置函数
iter()可以把可迭代对象变成迭代器,因为加了一个__next__()方法。 - 比如
for mem in list,或者enumerate其实是先使用了list.__iter__()生成一个迭代器,然后不断next(),直到ErrorIteration停止; generator:生成器,也能实现实现了__iter__()和__next__()方法,但更像是一个函数而不是一个类;属于迭代器,但是更高级更简洁;generator更优雅,可以这么定义:- 一个函数中通过
yield返回元素, - 推导式中用
()代替[]。 - LAZY: 并不提前计算所有值,而是在需要的时候才计算,因此节约内存;
- 一个函数中通过
python内置的全局函数
iter(), next()实际上是在调用对象的__iter__(), __next__()函数。
- 可迭代(容器)已经很熟悉了
- 迭代器(for, enumerate, zip)也比较熟悉
- 生成器用的比较少
举个例子,如果需要生成前10个平方数并打印,可以这么做:
lst = [i*i for i in range(10)] # list is iterable
for v in lst: # 'for' will implicitly call iter(lst) and call next()
print(v)但在两种情况下使用generator更好,通常是用于:
- 序列很长,很占用内存
- 不知道总长度,可能会无限使用
- 定义方式:两种
- 使用方式:使用for、enumerate等隐式调用,或者用while+next+StopIteration来手动使用
生成器的定义方式一:推导式
# generator comprehension
lst = (i**i for i in range(10))
# ---
for v in lst:
print(v)
# ---
while True:
try:
print(next(lst))
except StopIteration:
break定义方式二:函数+yield关键字
def lst(k):
curr = 0
while curr < k:
yield curr * curr
curr += 1
return 'done'
a = lst(10)
# ---
for v in a:
print(v)
# ---
while True:
try:
print(next(a))
except StopIteration:
breakyield 关键字的作用是:
- 在被next调用时,函数运行到yield这一行之后就返回yield后面的内容;
- 下一次被next调用时,从yield后面的开始执行,再到yield停止;
- 到return 真正终止。
- if, elif, else
- 条件判断是短路形式的,比如
1>0 or 1/0是True, 即使第二个表达式计算不出来
for element in iterator:
statements
while x <= 10:
statements- continue, break 用于循环控制
while/for - else用于正常结束循环的时候(break不算正常退出),额外执行的语句
def func(*args, **kwargs):
"""
description
"""
statements
return result- 返回的值可以写多个,会自动封包成一个tuple
- 在声明函数使用参数时,可以标注参数类型,方便被调用:
def func(x: [int])建议传入一个整数列表
func = lambda x: x+1
a = func(2)
a = (lambda x: x+1)(2)- 必备参数:就平时写的那种
- 关键字参数:使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值,在内部组装成dict
- 默认参数:默认值必须是immutable,默认参数在定义时必须在最后面
- 不定长参数:可以让函数处理额外的参数。
- 一个星号,导入的是tuple,常用
*args - 两个星号,导入的是dict,常用
**kw, **kwargs - 星号的作用是对iterable的对象拆分元素,*args = 1,2,3,对一个(args元组)拆分等于分散的元素
- 在函数内不用写星号
- 强制位置参数:
def func(a, /, b, * c)则星号后面的必须以关键字参数的形式传入,/ 之前的必须是不能是关键字参数,之间的随便
例子:假如我们要计算一些数的平方和,我们可以传入[1, 2, 3],但是这不优雅,所以利用*args可以不组装成list。
def sq_sum(*args):
s = 0
for i in args:
s += i * i
return s
print(sq_sum(1,2,3,4,5,6,7,8,9,10))- 在函数里的某个参数,作用域是这个函数整体
- 内层嵌套函数可以调用外层函数的参数
- 函数想修改非函数部分的参数(想在局部空间使用全局变量),需要在函数内使用 global 关键字
- map(func, iterable) -> map object(iterable), 返回一个映射
- functools.reduce(func(2 args), iterable), 返回一个结果;先计算前两个值,再将结果和第三个值相加
- filter(func, iterable) -> filter object(iterable), func(ele)为True的显示,为False的去掉
- itertools.accumulate(iterable, func(2 args)) -> accumulate obj, 返回一个累计值
sorted(iterable, key = [func[, reverse=True]]), 默认从小到大,reverse控制方向,func控制比较的值- list.sort() 和 sorted() 差不多,但是原地修改;sorted返回一个列表
from functools import reduce
from itertools import accumulate
a = [1, 3, 2, 5]
print(reduce(lambda x, y: x + y, a))
print(list(filter(lambda x: x % 2, a)))
print(list(accumulate(a, lambda x, y: 10 * x + y, )))
---
11
[1, 3, 5]
[1, 13, 132, 1325]functools.partial(func, kw), 偏函数: 固定函数的某个值。
import functools
s = '1011'
int2 = functools.partial(int, base=2)
def int2_self(x): return int(x, base=2)
print(int(s, base=2))
print(int2(s))
print(int2_self(s))- 通常类名要大写
- 所有Python的类,都继承自object
class Student:
# __init__ 是初始化的函数,这里面都是properties
# __init__ 的第一个参数必须是self,表示inst本身,并且调用的时候不用传递这个arg
def __init__(self, name, number, age):
self.name = name
self.number = number
self.age = age- 如果没有定义任何属性,则可以
alice = Student(); - 如果定义了参数,则应当
alice = Student('Alice', 114514, 19); - 应该在定义类的时候,将属性和方法都写出来。当然也可以在外部给一个inst增加未定义的属性,但是这样不安全,可读性差
和面向对象相对的是面向过程。如果采用面向对象的程序设计**,我们首选思考的不是程序的执行流程,而是把数据被视为一个对象。
面向对象里最重要的就是Class和Instance。Class是抽象的模板,形容了一系列instance;而instance是一个个对象。
对象包括两大点:属性(attribute/property)和方法(method)。 比如定义一个类student,“Alice”和“Bob”是这个类下的两个实例。在类中包括了属性:学号,身高,体重,年龄;还有方法(函数),比如吃饭,学习。
面向对象的几个特点:
- 数据封装,限制访问,继承和多态
“封装也称为信息隐藏,是利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。”
好处:
- 控制存取属性值的语句来避免对数据的不合理的操作
- 一个封装好的类,是非常容易使用的
- 代码更加模块化,增强可读性
- 隐藏类的实现细节,让使用者只能通过程序员规定的方法来访问数据
通过在class里定义一些方法(一些函数),来实现各种接口。比如定义打印年龄的函数:
# 除了第一个参数是self外,其他和普通函数一样
def print_age(self):
print(f"{self.name}的年龄是:{self.age}")使用方法的方法:
alice.print_age()为了使得内部属性不被随意访问和修改(但是可以初始化),在创建类的属性时应这样:
class Student(object):
def __init__(self, name, age):
self.__name = name
self.__age = age在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能read。
__name__这种是可以直接访问的特殊变量;__name这种是private变量;_name这种是在class中表示是公开的,但是不建议随意访问。按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。- 单下划线
_name命名的变量(包括类,函数,普通变量)不能通过**from module import **导入到另外一个模块中。 - 双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问
__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量:alice._Student__name。但是不同版本的Python解释器可能会把__name改成不同的变量名。 - 如果我直接给私有变量赋值会怎么样呢?基于上一条,如果我在类外直接给
instance.__attr赋值,其实会有两个属性:__attr, _ClassName__attr————后者才是我们想要的
上面的写法带来的问题:除了初始化,否则无法赋值;全程都无法读取
Java-like 的解决方案:通过定义 get 和 set 函数来解决问题:
- 副作用:顺便可以在 set 的时候校验参数一致性!
class Student(object):
def __init__(self, name, age):
self.__grade = None
self.name = name
self.age = age
def set_grade(self, num):
self.__grade = num
def print_age(self):
print(f"{self.name}的年龄是:{self.age}")Pythonic 的解决方案:使用 @property 和 @[attr].setter
class Student(object):
def __init__(self):
self.__score = None
@property
def score(self):
return self.__score
@score.setter
def score(self, i):
# check value
if not isinstance(i, int):
raise ValueError('int only, you fool')
elif 0 <= i <= 100:
pass
else:
raise ValueError('[0, 100] only, you fool')
# set value
self.__score = i
instA = Student()
instA.score = 76 # set score
print(instA.score) # get score有几个要注意的点:
- 必须先写
@property把一个方法变成属性,才能写@attr.setter,调换顺序不行;而且应该是先把某个method变成attr了,接下来才能写@attr.setter,不同名是不行的; - 这里不用担心两个函数重复名字的问题,调用的时候都直接写属性名字就行(不该加下划线);
- 现在在外部可以和之前一样赋值和读取了
@property和@*.setter都写是可读写,如果只写第一个就是只读————可以用只读这个属性来实现一些需求- 假如是只读的,就不能给它赋值,包括在
__init__里定义并初始化也不行 - api和实例变量不能同名,否则解释器不知道是调用api还是变量名,就会无限递
继承:可以从一个父类、基类(base class)超类(Super class)创建子类(subclass)。
继承可以把父类的所有功能都直接拿过来,这样就不必重零做起,子类只需要新增自己特有的方法,也可以把父类不适合的方法覆盖重写。
继承什么?公有的属性和方法:
- 假如子类和父类都有同样名字的方法,子类的会覆盖父类的(多态);
- 假如一个inst属于某个subclass,那他也属于base class;
class Human:
pass
class Student(Human):
pass
# 学生单继承自人类多态:指为不同数据类型的实体提供统一的接口,同一个行为具有多个不同表现形式或形态的能力。
多态存在的三个必要条件:
- 继承
- 重写
父类引用指向子类对象:Parent p = new Child();
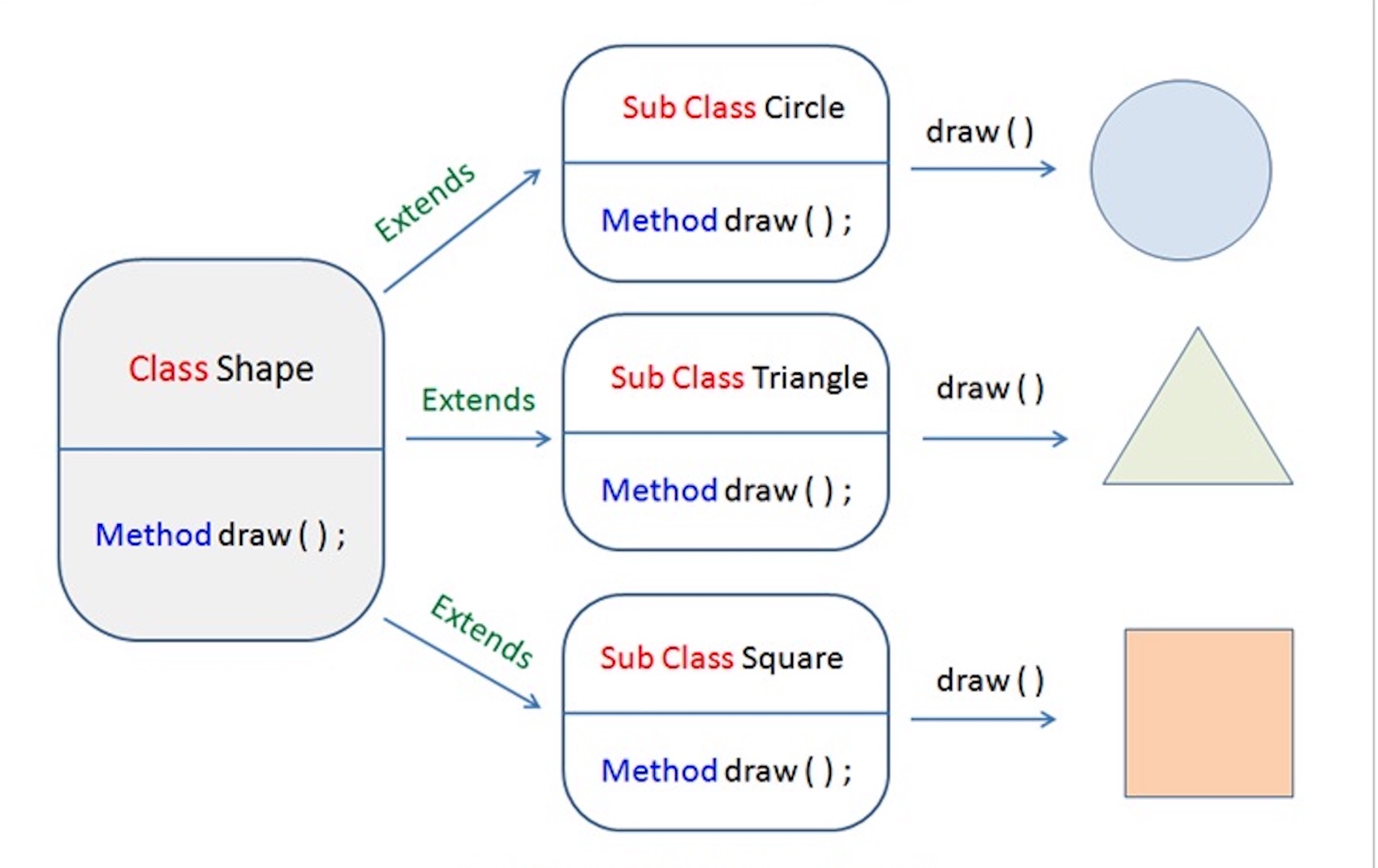
在上图中,每个子类可以重写(override)父类的方法。
著名的“开闭”原则:
- 对扩展开放:允许新增
BaseClass的子类; - 对修改封闭:不需要修改依赖
BaseClass类型的draw()等函数。
鸭子类型(英语:duck typing)是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由"当前方法和属性的集合"决定。
当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。
——James Whitcomb Riley
Python这种动态语言不要求严格的继承,假如我新建一个class,不从animal继承,直接从object继承,再给他写一个run方法,那么也可以run。
我觉得都可以理解,因为是根据inst所在的class来找run的。只要这inst有run这个名字的方法,就都可以用。
在Python中有一些双下划线作为前缀和后缀的函数,一般称呼他们为魔法方法/语法糖,因为的确非常方便。
有的时候,我们希望当我们print(obj)的时候能输出一些特殊信息。
比如我有一个ListNode类,和一个LinkedList类。我希望当我在打印一个LinkedList对象时,能打印链表中的所有元素。
但如果直接print,可能会显示这样的<__main__.ClassName object at 0x0000023EFCD14AF0>
为了增加可读性,我们可以在类里定义一个:
def __str__(self):
return f"{self.name} is Auto"这样print的时候就好看多了。
__str__是面向用户的,即用户在控制台输入print(obj)即可返回友好的提示。__repr__差不多,但是是面对开发者的。在控制台直接输入obj回车,也会返回:<__main__.Auto object at 0x00000289E3335420>- 为了增加可读性,我们在类里重构一下:
__repr__ = __str__此时obj.__repr__是一个和__str__绑定的函数,这样obj.__repr__()也能返回友好的提示。
正常情况下,当调用不存在的属性时会报错。但是我们可以这样定义,让class对特定的一些属性作出响应:
def __getattr__(self, attr):
if attr == 'score':
return stm但是对于未考虑到的attr,为了也作出响应,可以这么写:
def __getattr__(self, attr):
if attr == 'score':
return something
raise AttributeError('you fool')对于iterable来说,可以通过list[index]的方式访问value。如果我们希望一个自定义的类也能支持这种功能,就需要通过这个方法来重载[]运算符。
这里还有两个具体的方式:
- 通过方括号索引
- 通过方括号切片
因此要在定义函数时区分这两种情况。
def __getitem__(self, n):
if isinstance(n, int): # n是索引
return self.items[n]
if isinstance(n, slice): # n是切片
start = n.start
stop = n.stop
return self.items[n.start:n.stop]对于dict来说,可以通过dict[key] = value的方式创建一个键值对。如果我们希望一个自定义的类也能支持这种功能,就需要通过这个方法来重载[]运算符。
def __setitem__(self, k, v):
self.put(k, v)例如我自定义了一个链表,我希望判断某个元素是否在列表中,如 if x in linked_list,可以通过这个函数重载in运算符。
一种写在类内部的声明,通过预先声明实例属性等对象并移除实例字典来节省内存。 虽然这种技巧很流行,但想要用好却并不容易,最好是只保留在少数情况下采用,例如极耗内存的应用程序,并且其中包含大量实例。 ——Python Official Doc
-
如果正常给实例增加属性(通过init,或者在运行时动态增加属性),都会给对象产生两个属性:
__dict__ & __weakref__。 -
__dict__里面是属性 - 具体内容的kv对 -
dict导致了:访问速度慢,作为动态变量不安全
-
但是使用
__slots__就不会创建以上两个属性 -
更加安全,访问速度更快(直接写到内存里),节约内存空间
-
可以禁止运行时动态增加属性
在定义类的时候,增加一个类属性( 最好是tuple,否则会产生问题 ):
class Human:
__slots__ = ('name', 'age', '__salary')- 现在这个类的实例就只能有这两个属性,不能增加更多了。
- 如果赋予slots以外的属性会报错
__slots__有一个继承相关的特点:
- 子类继承父类的时候会继承
__slots__, 但如果子类不定义__slots__的话就不会起作用,仍然可以增加属性,会创建__dict, weakref__ - 如果子类想保持父类里的限制,可以定义一个
__slots__ = tuple(),相当于才能激活父类里的限制 - 子类可以再增加新的限制
在class里定义一个__call__(),即可把一个inst当func来用。甚至可以加一些args。
可用callable()函数,判断一个对象是否能被调用(是否可以被当作函数)。
__len__是对象的一个方法,而常用的len()函数只是调用了对象的这个方法,比如len(list)。
如果我想让自定义的类也能用len,可以自己在class里写一个
iter返回一个
模块通常是一个定义对象和语句的文件,一般是定义函数。比如模块文件mymodule.py里定义了函数myfunc,在其他位置里调用方法:
import mymodule
import mymodule as mm # 我猜如果这两句话同时出现,仍然只会导入一次(py不会重复导入),但是使用原名和昵称 *确实* 都行
---
mm.myfunc(args)
-------------------------
from mymodule import myfunc [as xxx] # 就可以不加module.了,而且可以自定义名字
from mymodule import * # 全部导入
myfunc(args)- 包就是一个文件夹
- 包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
- 里面必须包含__init__.py,里面可以是空的
- 如果在PyCharm里新建一个软件包,里面自带一个
__init__.py
调用方法:
- 在某处有一个主程序,在同级目录里还有一个包(文件夹),这是前提;
- 导入方法:
from package_name import file_name(推荐使用)import package_name.file_namefrom package.file import func(然后就可直接用函数名了)
在win下文件不分大小写,因此导入可能会有问题。所以一般在__init__.py里写一个变量:
__all__ = ['file1', 'file2']示例:模块里定义了一个类:

from pythonds.basic.Stack import Stack这是正确的写法。
一个错误写法是:
from pythonds.basic import Stack问题在于:
我是从Stack.py这个文件里导入Stack这个类,所以虽然文件和类重名,但是关系要搞清楚。
- 从解释器所在的位置开始查找,通常是内置/第三方 的 模块/包
- 从工作路径里查找
.代表同一文件夹,当前目录;每多一个点就上一层
- Python中一切异常都继承自
BaseException,具体的可以查看ErrorClass的列表。 - 可以自定义一个异常,但至少要继承自
BaseException - 可以同时捕捉多种异常
异常可以通过语句来处理:

try:
statements
except (A-exception, B-exception...) as e:
statements
else:
statements
finally:
statements可以主动抛出异常,通过raise和assert:
raise SomeError([string]),似乎大多数都支持在这里传入一个字符串,存疑assert expression[, string], 但只能抛出AssertionError
及其容易出错的特性,很多时候并没有memcpy,而是reference;所以这进一步引出了shallow copy和deep copy的区别
- python中,万物皆对象。
- python中不存在所谓的传值调用,一切传递的都是对象的引用,也可以认为是传址。
- 对于mutable: 类似C++的引用传递,将 a 真正的传过去,修改后fun外部的a也会受影响
- 对immutable: 类似C++的值传递,传递的只是a的值,没有影响a对象本身
def myfunc(t):
t += 2
print(id(t))
a = 1
print(id(a))
myfunc(a)
print(a)
print(id(a))
--------------------
2543723217136
2543723217168
1
2543723217136
# 因为 *不可变对象number* ,所以只传入了内存里的值;
# 可以看到a对应的地址没变,函数myfunc没有改变a对应的地址的内存里的内容,而是另外找了个地方
# 最后 a 对应的地址里面的内存内容还是 1
-----------------------------------------------
def myfunc2(t):
t.append('fuck')
print(id(t))
b = [1, 2, 'a']
print(id(b))
print(myfunc2(b))
print(b)
print(id(b))
--------------------
2345014392832
2345014392832
None
[1, 2, 'a', 'fuck']
2345014392832
# 可以看到 *可变对象list* 所指的内存地址是不变的还有一个特性,python为小int做了优化,有一个[-5, 256]的小整数池,在解释器启动的时候就创建了,可以避免频繁使用对象(假设频繁使用小整数)的创建和销毁。所有小整数对象都指向固定的地址。
a = 1
print(id(a))
b = 100
print(id(b))
b -= 99
print(id(b))
----------
1767367180528
1767367183696
1767367180528- MRO, Method Resolution Order
- 多继承,是指在继承的时候可以继承多个类:
class A(B, C, D) - MRO解决了多继承的复杂情况下,调用方法到底调用的是哪个类的方法的问题。
- MRO类似BFS,相对的是DFS。
- MRO在python体现为
ClassName.__mro__

在上图中,箭头指向父类。如果有多个子类继承了同一个父类,那么这个父类则放在它能够出现的所有位置中最左的位置。
MRO是一个列表,满足原则:
-
子类永远在父类前面;
-
如果有多个父类,会根据它们在列表中的顺序被检查;
-
如果对下一个类存在两个合法的选择,选择第一个父类;比如
A(B, C),选择B;
入度为0:没有箭头指向一个类。
在解析上图时,先找入度为0的类,并剪掉所有与之相连的箭头;两个符合条件的类,先整左边的。所以就能得到[A, B, C, D, E, F, Object]。
super返回一个proxy object,可以借此调用被重写的方法。
super(type, object_or_type=None)- object_or_type 决定了mro的搜索起点
- 如果一个mro是DCBA,object;obj_or_type指定为C,则会在BAobject里搜索
- mro指的是obj_or_type的mro
- 如果第二个参数给出,并且是obj,那么必须满足
isinstance(obj, type) - 如果第二个参数给出,并且是typ,那么必须满足
issubclass(type_arg_2, type) - 缺省参数
super()代表当前类和self
这部分内容参考自 python实现单例模式的5种方法, 但有一些修改
通过import导入的module是天然的单例模式,因为只会导入一次
- 装饰器装饰了一个类,在这个类的内存空间里,加入了一个闭包:闭包中记录了实例。
- 用一个k-v记录实例
- 如果有实例,k-v就是:class本身 - single instance
- class本身,是因为类本身在一个不可变的内存地址上
def singleton(cls):
instance = {}
def inner(*args, **kw):
if cls not in instance:
instance[cls] = cls(*args, **kw)
return instance[cls]
return inner
@singleton
class MyClass:
pass但以上的方法是线程不安全的,多个线程同时判断,有可能都判断为 暂时还没有实例 ;所以可以加一把锁
from threading import RLock
single_lock = RLock()
def singleton(cls):
instance = {}
def inner(*args, **kw):
with single_lock:
if cls not in instance:
instance[cls] = cls(*args, **kw)
return instance[cls]
return inner通过类变量,来检查是否存在实例
from threading import RLock
class Singleton:
single_lock = RLock()
def __init__(self, name):
self.name = name
@classmethod
def instance(cls, *args, **kwargs):
with cls.single_lock:
if not hasattr(cls, "_instance"):
cls._instance = cls(*args, **kwargs)
return cls._instance
single_1 = Singleton.instance('第1次创建')
single_2 = Singleton.instance('第2次创建')
print(single_1 is single_2) # True
print(single_2.name) # 第1次创建因为new才是真正的构造函数,所以可以在这个层面上作出修改。
from threading import RLock
class Singleton:
single_lock = RLock()
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
with cls.single_lock:
if not hasattr(cls, "_instance"):
cls._instance = super().__new__(cls)
return cls._instance
single_1 = Singleton('第1次创建')
print(single_1.name) # 第1次创建
single_2 = Singleton('第2次创建')
print(single_1.name, single_2.name) # 第2次创建 第2次创建
print(single_1 is single_2) # True- 但这么做有个问题,因为init依赖于new的返回值,所以在第二次创建实例时,会对已有的实例重新初始化。
- 为了解决这个问题,还需要对init做修改
- 如果已经被初始化了,就不再初始化
def __init__(self, name):
if hasattr(self, 'name'):
return
self.name = name- class Singleton(metaclass=SingletonType) 这行代码定义了一个类,
- 这个类是元类SingletonType 的实例,是元类SingletonType的__new__构造出来的,
- Singleton是实例,那么Singleton('第1次创建')就是在调用元类SingletonType 的__call__方法,__call__方法可以让类的实例像函数一样去调用。
- 在__call__方法里,cls就是类Singleton,
- 为了创建对象,使用super来调用__call__方法,而不能直接写成cls(*args, **kwargs),
- 这样等于又把SingletonType的__call__方法调用了一次,形成了死循环。
from threading import RLock
class SingletonType(type):
single_lock = RLock()
def __call__(cls, *args, **kwargs): # 创建cls的对象时候调用
with SingletonType.single_lock:
if not hasattr(cls, "_instance"):
cls._instance = super(SingletonType, cls).__call__(*args, **kwargs) # 创建cls的对象
return cls._instance
class Singleton(metaclass=SingletonType):
def __init__(self, name):
self.name = name
single_1 = Singleton('第1次创建')
single_2 = Singleton('第2次创建')
print(single_1.name, single_2.name) # 第1次创建 第1次创建
print(single_1 is single_2) # True通常的递归,会导致函数栈帧不断增加,直至达到最大限值——可能伴随着内存不足。Python 默认的最大递归深度为1000,但是可以手动修改。
一个递归的例子是求前n项正整数的和,或者乘积。
def func(x):
if x == 1:
return x
return x + func(x-1)上面的例子意味着每一层栈帧都依赖于更上一层函数栈帧的计算结果。但是我们可以将这个函数优化成尾递归:函数返回值只由递归函数本身组成。
def func(x, pre=0):
if x == 1:
return x+pre
return func(x-1, x+pre)
print(func(5)) # --> 15- 尽管如此,有些语言没有对尾递归做优化。
- Python/CPython解释器就没有优化,上一段的写法仍然会导致栈帧溢出。
- gcc -O2 级别的优化就会做优化
以下内容在参考内容的基础上做了一点改进:
import sys
# 一个异常,用于传递参数
class TailRecursionError(BaseException):
def __init__(self, args, kwargs):
self.args = args
self.kwargs = kwargs
def tail_rec_opt(func):
def _opt_exec(*args, **kwargs):
f = sys._getframe()
if f.f_back and f.f_back.f_back and f.f_back.f_back.f_code == f.f_code:
raise TailRecursionError(args, kwargs)
while True:
try:
return func(*args, *kwargs)
except TailRecursionError as e:
args = e.args
kwargs = e.kwargs
return _opt_exec
# 一个递归函数,尾递归形式,用于计算1+2+...n的和
@tail_rec_opt
def recursion(n, pre=0):
if n == 1:
return pre + 1
else:
return recursion(n - 1, pre + n)
print(recursion(5))- 尾递归实际上,是在装饰器里的while循环里完成的
在执行的过程中,首先栈帧会变成下面的样子:
| 层数编号 | 栈帧函数 | 要求返回值 |
|---|---|---|
| 4 | _opt_exec(4, 5) | |
| 3 | func(5, 0) | opt_exec(4, 5) |
| 2 | _opt_exec(5, 0) | return func(5, 0) |
| 1 | module | - |
- 此时帧4会触发异常,因为和帧2的函数名一样。此时会结束函数调用,销毁帧4,并且返回一次递归函数计算的结果:
e(4, 5) - 此时异常会向下返回,直至回到帧2的return部分
- return的异常将被try-except捕捉,并修改帧2中的args和kwargs
此时将变成:
| 层数编号 | 栈帧函数 | 要求返回值 |
|---|---|---|
| 2 | _opt_exec(4, 5) | return func(4, 5) |
| 1 | module | - |
并继续运算,变成:
| 层数编号 | 栈帧函数 | 要求返回值 |
|---|---|---|
| 4 | _opt_exec(3, 4) | |
| 3 | func(4, 5) | opt_exec(3, 4) |
| 2 | _opt_exec(4, 5) | return func(4, 5) |
| 1 | module | - |
继续运行循环,直至:
| 层数编号 | 栈帧函数 | 要求返回值 |
|---|---|---|
| 3 | func(1, 14) | |
| 2 | _opt_exec(1, 14) | return func(1, 14) |
| 1 | module | - |
这次帧3直接返回了15,因此整个函数返回了15,递归结束。
有这样一类问题,有时我们会申请资源,但如果忘记释放资源就会出问题,比如lock.acquire()但不lock.release(),socket.connect()但不socket.close()。
另一类问题是,如果在拥有资源时出现了异常,我们希望仍然能正常释放资源。
以上问题的一个解决方案是使用try-except-finally:
try:
socket.connect()
socket.send()
except SomeSocketError:
do something
finally:
socket.close()with…是一种语法糖,内含了try-finally组合,可以自动申请-释放资源。他实际上应用了context manager protocol,通过__enter__()申请资源,通过__exit__()释放资源,例如文件上下文管理器:
# a simple file writer object
class MessageWriter(object):
def __init__(self, file_name):
self.file_name = file_name
def __enter__(self):
self.file = open(self.file_name, 'w')
return self.file
def __exit__(self, *args):
self.file.close()
# using with statement with MessageWriter
with MessageWriter('my_file.txt') as xfile:
xfile.write('hello world')还比如在使用锁时常用:
with lock: # 可以不as
do something提醒:with内的语句正常执行完才会触发__exit__(),如果中间退出/异常,都不会触发。
TODO:
- weakref: https://zhuanlan.zhihu.com/p/425426122
- threading
- multiprocessing
- re
- time
- bisect
- collections
- functools
- itertools