NAS-survey
A survey on Neural Architechture Search
list (latest to oldest)
- Neural Operator Search (under review at ICLR2020)
https://openreview.net/forum?id=H1lxeRNYvB- heterogeneous search space: feature, attention, dynamic conv
- Towards Fast Adaptation of Neural Architectures with Meta Learning (under review at ICLR2020))
https://openreview.net/forum?id=r1eowANFvr- meta-architecture that is able to adapt to a new task quickly through a few gradient steps
- efficient first-order approximation algorithm to solve the bilevel optimization
- few-shot learning
- StacNAS: Towards Stable and Consistent Optimization for Differentiable Neural Architecture Search (under review at ICLR2020)
https://openreview.net/forum?id=rygpAnEKDH- grouping similar operations to compensate for the effect of multicollinearity
progressive backward variable pruning- simpler one-level joint optimization of both architecture and model parameters
- Understanding Architectures Learnt by Cell-based Neural Architecture Search (under review at ICLR2020)
https://openreview.net/forum?id=BJxH22EKPS- NAS architectures generated by popular NAS algorithms tend to have the widest and shallowest cells among all candidate cells in the same search space.
- NAS evaluation is frustratingly hard (under review at ICLR2020)
https://openreview.net/forum?id=HygrdpVKvr- the use of tricks in the evaluation protocol has a predominant impact on the reported performance of architectures
- the cell-based search space has a very narrow accuracy range, such that the seed has a considerable impact on architecture rankings
- the hand-designed macrostructure (cells) is more important than the searched micro-structure (operations)
- the depth-gap is a real phenomenon, evidenced by the change in rankings between 8 and 20 cell architectures.
- RESIZABLE NEURAL NETWORKS (under review at ICLR2020)
https://openreview.net/forum?id=BJe_z1HFPr- each sub-network obtains a unique feature map scale. The resize operation for feature map resolution is performed on the stage-level by a non-integer scaling ratio. (change traditional operators into different size of feature maps)
- Resizable as Architecture Search (Resizable-NAS), Resizable as Data Augmentation (Resizable-Aug), Adaptive Resizable Network (Resizable-Adapt)
- BETANAS: BALANCED TRAINING AND SELECTIVE DROP FOR NEURAL ARCHITECTURE SEARCH (under review at ICLR2020)
https://openreview.net/forum?id=HyeEIyBtvr - UNDERSTANDING AND ROBUSTIFYING DIFFERENTIABLE ARCHITECTURE SEARCH (under review at ICLR2020)
https://openreview.net/forum?id=H1gDNyrKDS- eigenspectrum of the Hessian of the validation loss with respect to the architectural parameters --> smaller Hessian spectrum, better generalization properties
- early stopping
- DARTS+: Improved Differentiable Architecture Search with Early Stopping (Liang et al. 2019)
https://arxiv.org/abs/1909.06035- early stopping
- Rethinking the Number of Channels for Convolutional Neural Networks (Zhu et al. 2019)
https://arxiv.org/abs/1909.01861- channel expanding strategies
- HM-NAS: Efficient Neural Architecture Search via Hierarchical Masking (Yan et al. 2019; accepted at ICCV’19 Neural Architects Workshop)
https://arxiv.org/abs/1909.00122- hierachical masking on node, edge and weight
- no need to train from scratch, so the overall time can be reduced
- SCARLET-NAS: Bridging the gap Between Scalability and Fairness in Neural Architecture Search (Chu et al. 2019)
https://arxiv.org/abs/1908.06022- resolve problem of identy operator in one-shot method (observed in FairNas)
- linearly equivalent transformation
- consider SE block
- PC-DARTS: Partial Channel Connections for Memory-Efficient Differentiable Architecture Search (Xu et al. 2019)
https://arxiv.org/abs/1907.05737 - FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search (Chu et al. 2019)
https://arxiv.org/abs/1907.01845 - Transfer NAS: Knowledge Transfer between Search Spaces with Transformer Agents (Borsos et al. 2019)
https://arxiv.org/abs/1906.08102- different search space definitions require restarting the learning process from scratch
- propose a novel agent based on the Transformer that supports joint training and efficient transfer of prior knowledge between multiple search spaces and tasks
- Adaptive Stochastic Natural Gradient Method for One-Shot Neural Architecture Search (Akimoto et al. 2019; accepted at ICML’19)
https://arxiv.org/abs/1905.08537 - Searching for A Robust Neural Architecture in Four GPU Hours (Dong and Yang 2019, accepted at CVPR’19)
https://github.com/D-X-Y/GDAS - Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation (Chen et al. 2019)
https://arxiv.org/abs/1904.12760 - Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours (Stamoulis et al. 2019)
https://arxiv.org/abs/1904.02877 - Single Path One-Shot Neural Architecture Search with Uniform Sampling (Guo et al. 2019)
https://arxiv.org/abs/1904.00420 - Random Search and Reproducibility for Neural Architecture Search (Li and Talwalkar 2019)
https://arxiv.org/abs/1902.07638 - Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation (Liu et al. 2019; accepted at CVPR’19)
https://arxiv.org/abs/1901.02985 - SNAS: Stochastic Neural Architecture Search (Xie et al. 2018; accepted at ICLR’19)
https://arxiv.org/abs/1812.09926 - IRLAS: Inverse Reinforcement Learning for Architecture Search (Guo et al. 2018; accepted at CVPR’19)
https://arxiv.org/abs/1812.05285 - FBNet: Hardware-Aware Efficient ConvNet Designvia Differentiable Neural Architecture Search (Wu et al. 2018; accepted at CVPR’19)
https://arxiv.org/abs/1812.03443 - ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware (Cai et al. 2018; accepted at ICLR’19)
https://arxiv.org/abs/1812.00332- the output feature maps of all N paths are calculated and stored in the memory, while training a compact model only involves one path (different from one-shot, darts)
- binary gate, latency, latency prediction model
- search space: MBC {3,5,7} {3,6}, skip
- RL, Gradient
- Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search (Wu et al. 2018)
https://arxiv.org/abs/1812.00090 - InstaNAS: Instance-aware Neural Architecture Search (Cheng et al. 2018)
https://arxiv.org/abs/1811.10201 - Neural Architecture Optimization (Luo et al. 2018; accepted at NeurIPS’18)
https://arxiv.org/abs/1808.07233- mapping models into continuous space using encoder and decoder
- Path-Level Network Transformation for Efficient Architecture Search (Cai et al. 2018; accepted at ICML’18)
https://arxiv.org/abs/1806.02639 - MnasNet: Platform-Aware Neural Architecture Search for Mobile (Tan et al. 2018; accepted at CVPR’19)
https://arxiv.org/abs/1807.11626 - DARTS: Differentiable Architecture Search (Liu et al. 2018; accepted at ICLR’19)
https://arxiv.org/abs/1806.09055 - Efficient Neural Architecture Search via Parameter Sharing (Pham et al. 2018; accepted at ICML’18)
https://arxiv.org/abs/1802.03268 - Understanding and Simplifying One-Shot Architecture Search (Bender et al. 2018; accepted at ICML’18)
http://proceedings.mlr.press/v80/bender18a/bender18a.pdf - Progressive Neural Architecture Search (Liu et al. 2017; accepted at ECCV’18)
https://arxiv.org/abs/1712.00559 - Learning Transferable Architectures for Scalable Image Recognition (Zoph et al. 2017; CVPR’18)
https://arxiv.org/abs/1707.07012 - SMASH: One-Shot Model Architecture Search through HyperNetworks (Brock et al. 2017; accepted at NeurIPS workshop on Meta-Learning’17)
https://arxiv.org/abs/1708.05344 - Neural Architecture Search with Reinforcement Learning (Zoph and Le. 2016; accepted at ICLR’17)
https://arxiv.org/abs/1611.01578
Gradient-based

bilevel optimization problem

approximate by adapting w using only a single training step, without solving the inner optimization

chain rule

finite difference approximation

Evaluating the finite difference requires only two forward passes for the weights and two backward passes for α, and the complexity is reduced from O(|α||w|) to O(|α| + |w|).
-
Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation
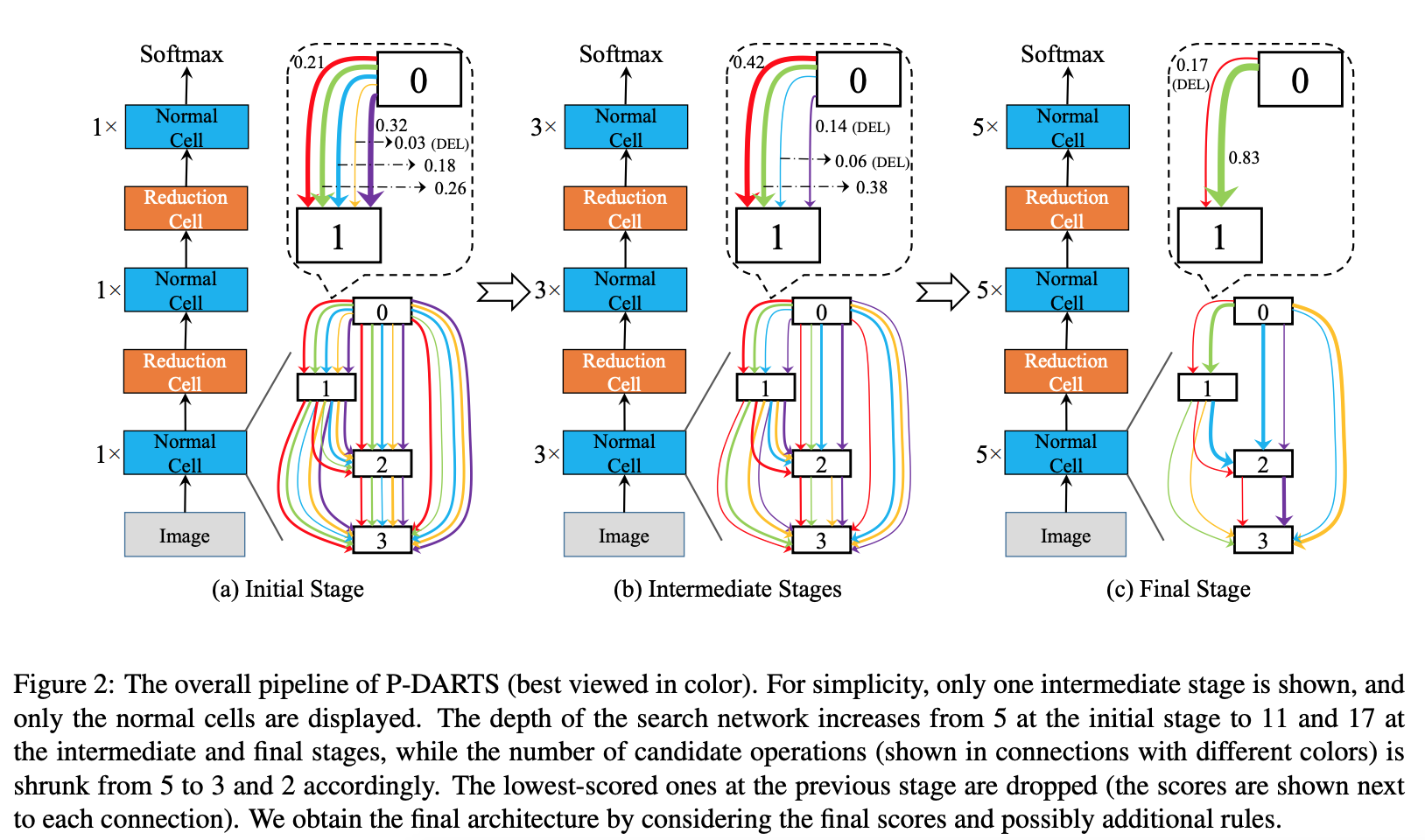
-
PC-DARTS: Partial Channel Connections for Memory-Efficient Differentiable Architecture Search
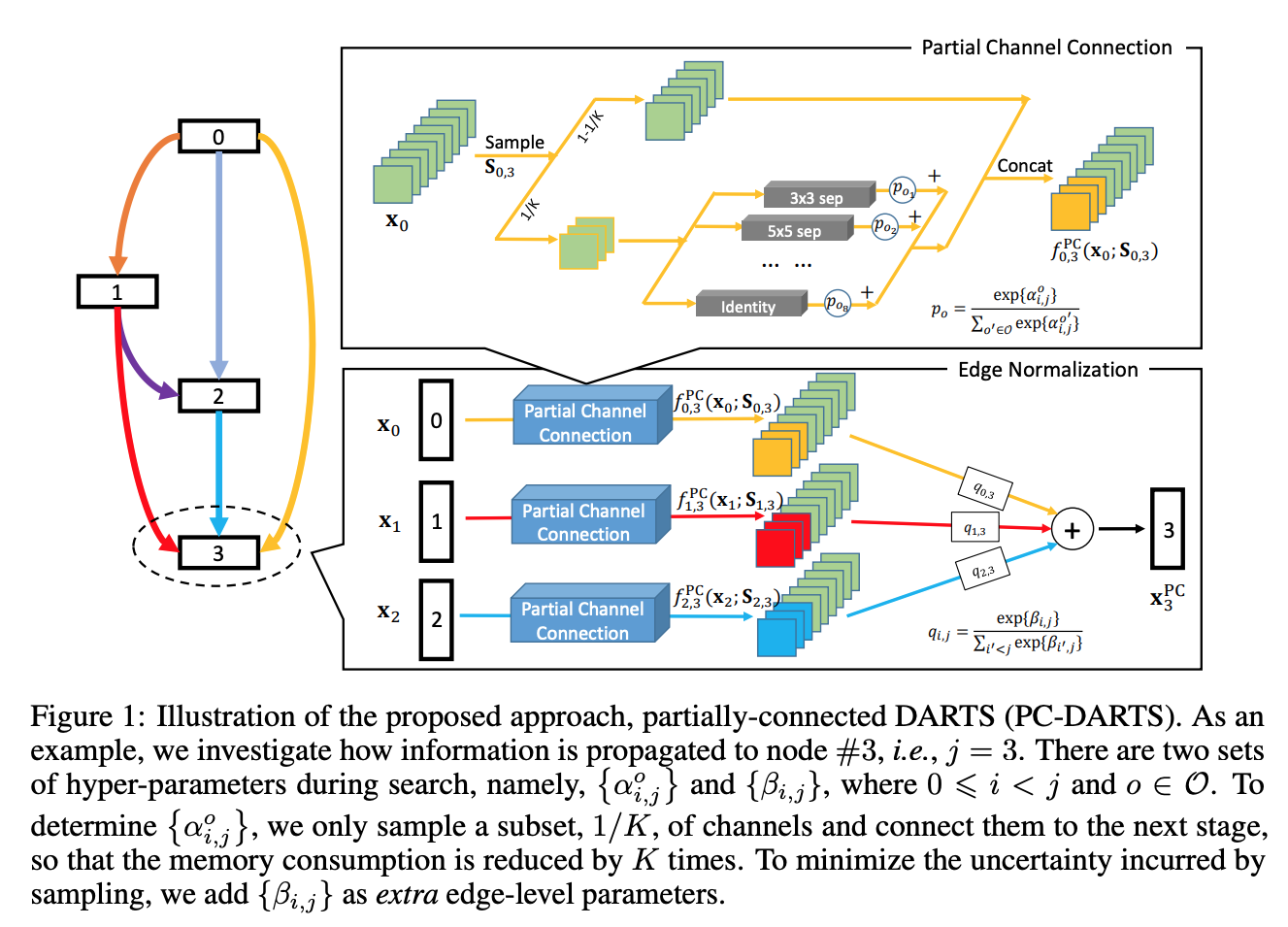



- SNAS: STOCHASTIC NEURAL ARCHITECTURE SEARCH
- DARTS+: Improved Differentiable Architecture Search with Early Stopping
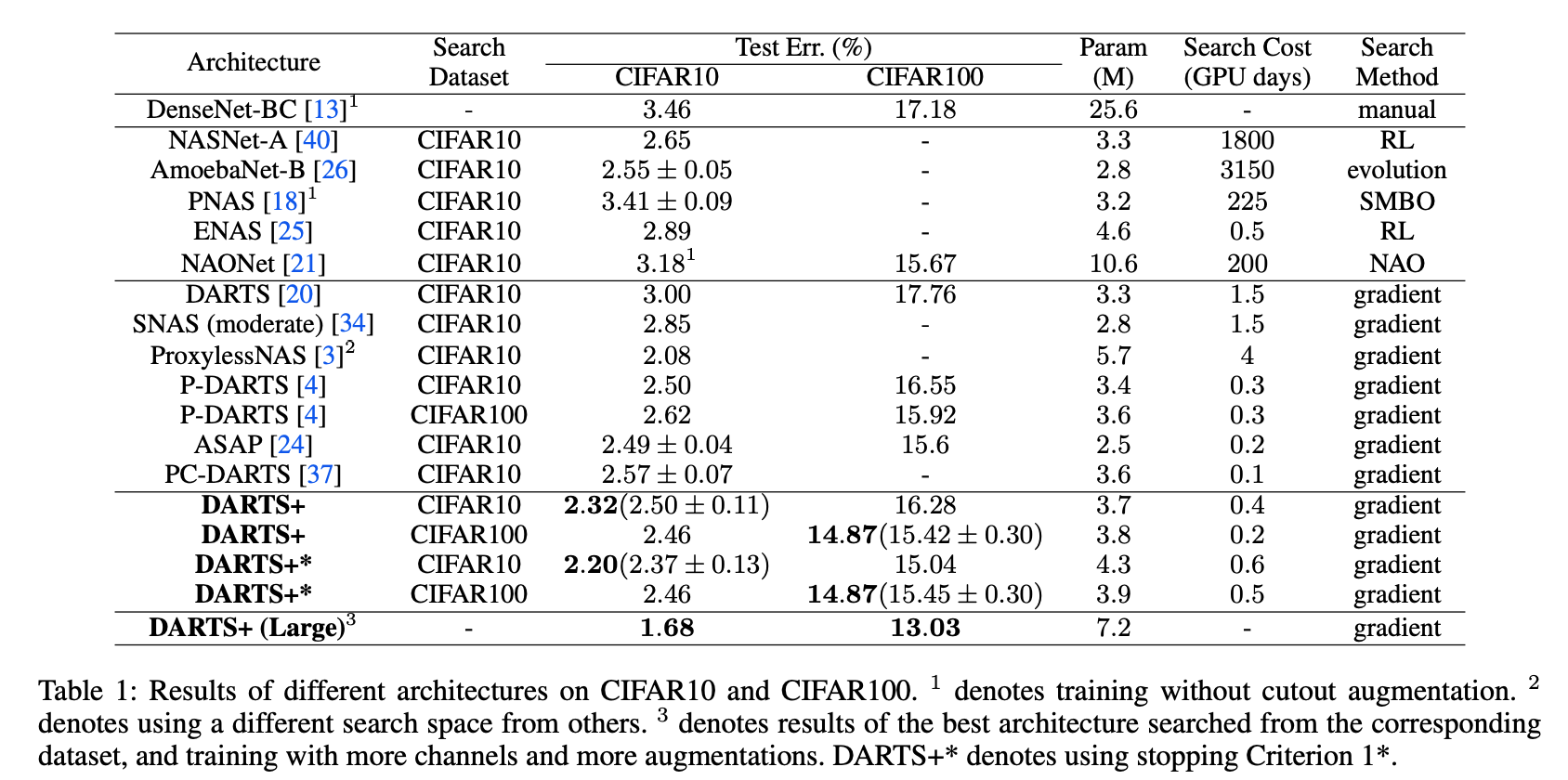


Others








- FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search
- MANAS: Multi-Agent Neural Architecture Search
- Network Pruning via Transformable Architecture Search
- Understanding and Simplifying One-Shot Architecture Search





New image
Cmd+Ctrl+Shift+4Cmd+Alt+V
Preview
Cmd+K V