A collection of redistributable Python scripts to help organize ASPLOS 2022
This repository contains some Python scripts that we used to help us manage the ISCA 2021 conference. We use the scripts to manage the following things for ISCA 2021 Conference:
-
Conflict of Interest Crosscheck
We use DBLP to crosscheck the conflict list entered by each PC. The scripts will try to match each PC name, fetch DBLP profile, and gather all of the co-authors. The scripts are not yet perfect; there are still some manual works to do.
-
Paper Topic Assignment
The paper topic assignment is used to prioritize paper topic to help with reviewer assignment.
-
Paper Discussion Scheduler
Based on the availability of its PC reviewer, the script try to find possible window for paper discussion during PC meeting. The script is not perfect yet, so some manual adjustment maybe required. The output of the scripts can be used as starting point.
-
Zoom Meeting Config Generator
Based on the conflict information of each paper, the script generate the list of attendance for conflict room and discussion room to separate the meeting participant during PC meeting.
Our conference uses HotCRP to manage the submission, and thus our scripts are created to be compatible with the HotCRP v3.0b1. Unfortunately, as HotCRP is updated regularly, the scripts may not be compatible with future version of HotCRP. We recommend that you save your HotCRP states and configurations before making any changes or uploading any CSV files generated by these scripts.
We use the email address registered with HotCRP to uniquelly identify each person. Therefore, it is recommended that you collect the HotCRP email address everytime you create a form to collect information outside HotCRP (e..g, meeting availability, zoom email address, etc.).
There are 8 Python scripts provided in this repository.
-
s00_function.py
This script contains all of the functions that will be called by other script. You don't need to run this script unless you need to debug its functionality.
-
s01_pcname_to_dblp_person_id.py
This script is used to find DBLP person id based on the given first name and last name.
-
s02_pccoauthors_dblp_crawler.py
This script is used to find all of the co-authors for each PC member based on publications listed in DBLP.
-
s03_pcconflict_crosscheck.py
This script is used to crosscheck the co-authors from DBLP with the collaborators entered in HotCRP for each PC member.
-
s04_pcconflict_merge_hotcrp.py
This script is used to update missing collaborators from DBLP to HotCRP.
-
s05_paper_topic_assign.py
This script is used to assign paper topic based on topic priority.
-
s06_paper_discussion_window.py
This script is used generate paper discussion schedule used in PC meeting.
-
s07_zoom_meeting_generator.py
This script is used to generate Zoom Breakout Room Configuration used in PC meeting.
- Bagus Hanindhito, PhD Student
- Lizy Kurian John, PC Chair of ISCA 2021
Laboratory for Computer Architecture, Department of Electrical and Computer Engineering
The University of Texas at Austin, Austin, The United States of America
We would like to thank the following persons that give us ideas during the development of these scripts.
- Mario Drumond for PC Chair Kit (https://github.com/mdrumond/pc-chair-kit)
- Emery Berger for ASPLOS-21 scripts (https://github.com/emeryberger/ASPLOS-2021)
- Othneil Drew for README Template (https://github.com/othneildrew/Best-README-Template)
These scripts are licensed under GNU General Public License v2.0. Feel free to modify, use, and distribute these scripts.
The scripts may not suite your needs and may also contain some bugs and imperfections. We encourage users to actively participating these scripts and add more features into them. Feel free to open a pull request should you want to add new features to the scripts or just do a little bug fixing. Every contribution will definitely be helpful for our communities and future conferences.
If they are useful for you and your works, we would be happy if you could cite us.
Please follow the steps below to obtain the scripts and run them locally at your own machine.
The scripts are developed under Ubuntu 20.04.1 LTS running on Windows Subsystem Linux 2 (WSL2).
We use Python 3.6.12 64-bit with the following packages installed:
- ipython_genutils==0.2
- ipython==7.16.1
- pexpect==4.8.0
- decorator==4.4.2
- pyzmq==20.0.0
- traitlets==4.3.3
- jupyter_client==6.1.7
- zeromq==4.3.4
- parso==0.8.1
- jupyter_core==4.7.1
- prompt-toolkit==3.0.1
- pickleshare==0.7.5
- tornado==6.1
- backcall==0.2.0
- ipykernel==5.3.4
- pygments==2.8.1
- six==1.15.0
- python-dateutil==2.8.1
- jedi==0.17.0
- ptyprocess==0.7.0
- numpy==1.19.5
- pandas==1.1.5
- pytz==2021.1
- tqdm==4.59.0
- fuzzywuzzy==0.18.0
- unidecod==1.2.0
- xmltodict==0.12.0
The scripts are compatible with Visual Studio Code with Python plugin (v2021.2.633441544) and Jupyter Extension (v2021.2.576440691) for Visual Studio Code. It is recommended to use Visual Studio Code with these plugins to run the script cell-by-cell (just like in Jupyter Notebook). This makes it easier to debug the script should there is any error. Visual Studio Code also has a reliable interface with Windows Subsystem Linux 2 which is very useful if you use Windows Subsystem Linux 2 as your development environment.

- Interface seamlessly with Windows Subsystem Linux 2.
- Integration with Git version control system.
- Integration with Conda virtual environment for Python.
- Interactive Shell.
- Text editor with syntax highlighting.
- Cell-based code execution.
- Interactive variable inspection.
- Interactive output shell.
We recommend to use virtual environment (e.g., Anaconda) to install the required packages to avoid version conflict.
We recommend to use CSV Editor that can support UTF-8 encoding to avoid any miss-interpreted characters. We use Microsoft Office Excel 2019 to edit CSV downloaded from HotCRP and to prepare CSV to be uploaded to HotCRP.
-
Load CSV to Excel
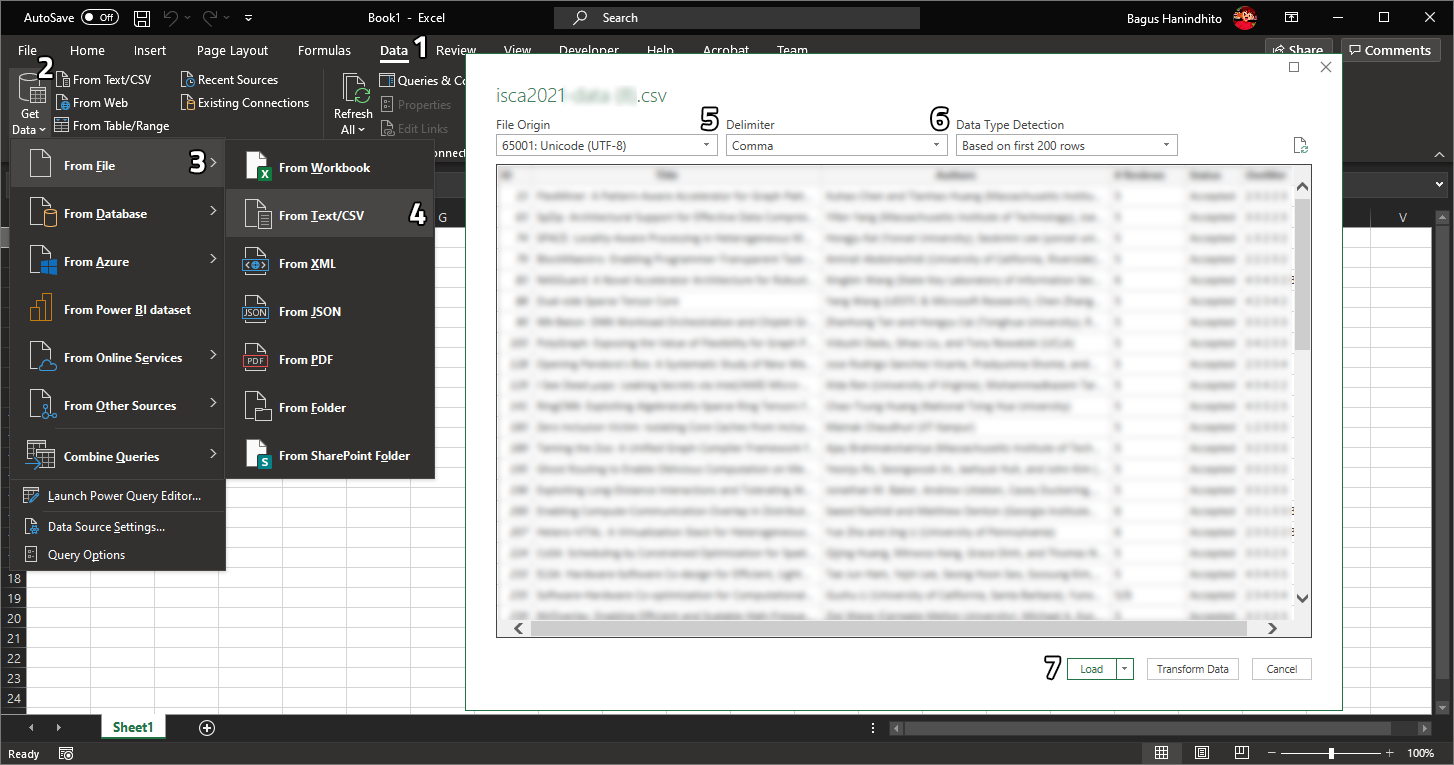
Please do not directly open the CSV file using Excel since it will be wrongly decoded. Open a blank Excel workbook and go to
Dataon the tab menu (1). SelectGet Data(2),From File(3),From Text/CSV(4). An open file dialog will appear to let you choose which CSV file you want to load.Then, data preview dialog will open as shown above. Please select
File Originas65001: Unicode (UTF-8)(5) andDelimiterasComma(6). Finally, clickLoad(7) to load the CSV into a worksheet. Now, you can manipulate the CSV data using Excel. -
Save CSV from Excel
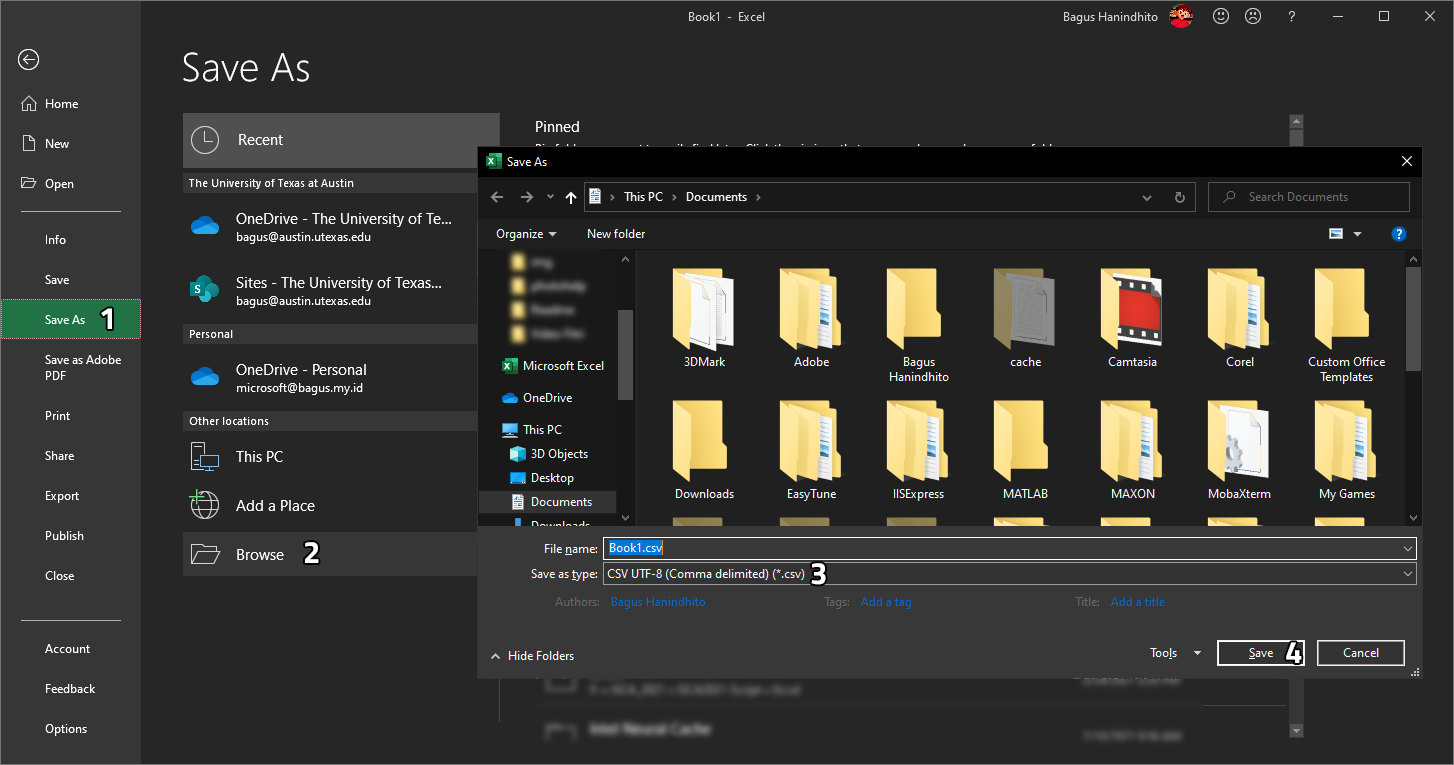
To save the data from Excel (.xlsx) to CSV, please select
File(not shown, it should be located on the top left), thenSave as(1). SelectBrowse(2) to find the folder where you want to save the CSV into. Then, selectCSV UTF-8 (Comma delimited) (*.csv)on theSave as type:(3) dropdown box. Finally, clickSave(4). This CSV file can now be uploaded into HotCRP or can be used as input to our Python scripts.


-
Clone the github repository
git clone https://github.com/hibagus/ISCA-2021-Script.git
-
Prepare and activate the virtual environment (We use Anaconda).
conda create -n COI_Redistributable python=3.6.12 conda activate COI_Redistributable
-
Install required packages
pip install -r requirements.txt
We provide some sample CSV data inside the directory sample-data to make you easier to use these scripts.
This section is used to do a Conflict of Interest Crosscheck between the conflict list entered by each PC member in HotCRP and the list of co-authors from all of the publications of each PC member listed in DBLP. It consists of three steps as follows.
First, we need to get correct DBLP Person ID for each PC member. The DBLP Person ID is used to get the URL to DBLP database that contains all of the publications each PC member has. The publications will later be used to get the co-authors data and the publication year to construct the list of co-authors. Because of the homonym (i.e., multiple persons have same name), the output of the script may contain multiple DBLP Person ID for each PC member although the script has tried to do fuzzy match to filter unnecessary entries. You must manually check and inspect the output CSV file from this script before moving forward. Please use Excel to inspect and modify the output CSV file. Follow the Recommendation above on how to import CSV into Excel with UTF-8 encoding and export CSV from Excel with UTF-8 encoding.
-
Script
Use script
s01_pcname_to_dblp_person_id.pyto accomplish this task. -
Input
The input to this script is a CSV file contains the PC info from HotCRP. To obtain this CSV file, go to the
Userson the side-panel of your HotCRP conference page which will bring you to the list of users registered. In theUser Selectionon the top, selectProgram committeeand clickGowhich will display all PC members. Then, go to the bottom of the page, clickselect all xxx, then Download:and choosePC info. ClickGoto download the CSV file.The header of this CSV file is shown below.
first,last,email,affiliation,country,roles,tags,collaborators,follow,"topic: ...","topic: ...",...
-
Output
The script will output a CSV file that contains several fields, including the URL to the DBLP database. The header of this CSV file is shown below. Each field will be explained afterwards.
full_name,first_name,last_name,affiliation,email,isUnique,isError,entrynum,name_confidence,affl_confidence,name_dblp,url_dblp,affiliation_dblp
-
isUniqueIndicates that the entry for a particular PC member is unique (i.e., no homonym) if it has value of
1. If it is not unique, then you will need to manually select the correct entry for a particular PC member. We suggest that you check both unique and not unique entries if you have time. -
isErrorIndicates that the script is unable to fetch the URL to the DBLP database. It may be because the person does not exist in DBLP database. You may need to manually check the entry that has
isErrorvalue of1. -
entrynumIndicates the number of entry for a particular PC member. If there is no homonym, the entry number should only be
0. Anything larger than0indicates that there are some homonym for a particular PC member that need to be solved. -
name_confidenceIndicates the fuzzymatch filtering confidence based on the first name and last name. The script tries to remove all non-relevant entries of homonym for each PC member. If the confidence level is lower than a predefined threshold, the entries will be removed, otherwise be kept. It is up to you to define the threshold; the higher the threshold, the less homonym entries will make through the output CSV file. We recommend to keep the threshold around 80 to 90.
-
affl_confidenceIndicates the fuzzymatch filtering confidence based on the affiliation. The script tries to remove all non-relevant entries of homonym for each PC member. If the confidence level is lower than a predefined threshold, the entries will be removed, otherwise be kept. It is up to you to define the threshold; the higher the threshold, the less homonym entries will make through the output CSV file. We recommend to keep the threshold around 80 to 90.
-
name_dblpName of PC member based on the DBLP
-
url_dblpThe URL to the DBLP database.
-
affiliation_dblpAffiliation of PC member based on the DBLP
-
Note: Please make sure that the result from this section is correct (i.e., the output CSV file). This file will be used repeatedly in the next section, and thus the correctness of the output CSV file is important.
Note: If you update the input CSV file, you will need to re-run this section.
Next, we collect the co-authors list for each PC member. The co-authors' names are obtained from DBLP through the publication list of each PC member. Unlike previous section, this section require little to none manual work. Make sure that the output CSV file from previous section is correct before you proceed through this section. You also need to set the threshold_year inside the script to limit the range of years in which the publications' co-authors should be marked as conflict.
-
Script
Use script
s02_pccoauthors_dblp_crawler.pyto accomplish this task. -
Input
The input to this script is a CSV file from the previous section that contains the URL to DBLP Database. The header of this CSV file is shown below.
full_name,first_name,last_name,affiliation,email,isUnique,isError,entrynum,name_confidence,affl_confidence,name_dblp,url_dblp,affiliation_dblp
-
Output
The script will output a CSV file that contains several fields as explained shortly. This output CSV file will be used for the next section. Normally, you don't need to do anything else manually at this section, providing that the input CSV file from previous section is correct.
full_name,first_name,last_name,affiliation,email,name_dblp,url_dblp,affiliation_dblp,coauthors_name_dblp,coauthors_url_dblp
-
name_dblpName of PC member based on the DBLP
-
url_dblpThe URL to the DBLP database.
-
affiliation_dblpAffiliation of PC member based on the DBLP
-
coauthors_name_dblpList of co-authors name based on the DBLP
-
coauthors_url_dblpList of co-authors URL to DBLP Database.
-
After that, we perform a crosscheck between the co-authors list obtained from DBLP and collaborators name obtained from HotCRP for each PC member. The script will do fuzzy match of the name to construct DBLP-only conflict list and HotCRP-only conflict list. The DBLP-only conflict list can be used to add missing conflict to each PC member in the next section. Meanwhile, the HotCRP-only conflict list is used to detect any wrongly-entered conflict by PC member. In our script, we only consider the DBLP-only conflict and add them to HotCRP in the next section.
-
Script
Use script
s03_pcconflict_crosscheck.pyto accomplish this task. -
Input
The input to this script is a CSV file from the previous section that contains the co-authors list for each PC member. The header of this CSV file is shown below.
full_name,first_name,last_name,affiliation,email,name_dblp,url_dblp,affiliation_dblp,coauthors_name_dblp,coauthors_url_dblp
-
Output
The script will output a CSV file that contains the list of DBLP-only conflict and HotCRP-only conflict for each PC member.
full_name,email,conflict_only_dblp_name,conflict_only_dblp_url,conflict_only_hotcrp
-
conflict_only_dblp_nameThe list of the name of person in conflict exist only in DBLP.
-
conflict_only_dblp_urlThe list of the URL to DBLP Database of person in conflict exist only in DBLP.
-
conflict_only_hotcrpThe list of the name of person in conflict exist only in HotCRP.
-
Finally, we update the missing conflict in HotCRP based on the DBLP-only conflict obtained by DBLP-HotCRP crosschecking in previous section. The DBLP-only conflict, by default, does not have information about their affiliations. The script is able to fetch the affiliations for each DBLP-only conflict before merge them into HotCRP-compatible CSV, but this requires very long runtime since it needs to crawl the DBLP database for each DBLP-only conflict. If you don't wish to wait, you can use default affiliation None <DBLP> by performing slight modification to the script (see the script on line 48-55 for more information).
The output of this script is a CSV file that is ready to be uploaded to HotCRP. Please backup your HotCRP data and configuration before uploading the CSV. To upload the CSV file, go to the Users, then click Create accounts. From there, choose Bulk Update and choose the correct CSV file. Finally, clicj Save Accounts. If successful, this will update the collaborators field of each PC member.
-
Script
Use script
s04_pcconflict_merge_hotcrp.pyto accomplish this task. -
Input
There are two CSV files that are used as input to this script:
-
The input to this script is a CSV file contains the PC info from HotCRP.
This input must be the same file as the section Getting DBLP Person ID. If you happens to change this CSV file, you need to start over from beginning.
The header of this CSV file is shown below.
first,last,email,affiliation,country,roles,tags,collaborators,follow,"topic: ...","topic: ...",...
-
The output of previous section, which is a CSV file that contains the list of DBLP-only conflict and HotCRP-only conflict for each PC member.
The header of this CSV file is shown below.
full_name,email,conflict_only_dblp_name,conflict_only_dblp_url,conflict_only_hotcrp
-
-
Output
The script will output an updated CSV file that is ready to be uploaded to HotCRP.
The header of this CSV file is shown below.
first,last,email,affiliation,country,roles,tags,collaborators,follow,"topic: ...","topic: ...",...
Each paper can fall into multiple topics since the authors can choose multiple topics that are appropriate for their paper. The PC members can also define their preference based on their expertise on what topics of the papers they want to review. This script helps to categorize the papers based on priority topic. The topic is prioritize based on the availability of reviewers with expertise on this topic. Usually, narrow topic has higher priority compared to more general topic. The script will output a single topic assigned for each paper. Based on this topic assignment, the papers are then tagged with distinctive tag on HotCRP as a guide to make it easier to assign reviewer to the papers. We use the HotCRP automatic assignment with some modification to help us assign reviewer to each paper.
-
Script
Use script
s05_paper_topic_assign.pyto accomplish this task. -
Input
There are two CSV files that are used as input to this script:
-
The CSV file that contains the list of papers with their selected topics.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectTopicsonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
paper,title,topic
-
The CSV file that contains predefined topic priority.
This file is created manually. It contains all of the topics used in the conference and its numerical priority. The lower the number, the higher the priority is. See the
sample-data/input/isca2021-topics-priority.csvfor more information. Note that the topic must be match with the topic defined in HotCRP.The header of this CSV file is shown below.
topics,priority
-
-
Output
The script will output an updated CSV file that is ready to be uploaded to HotCRP.
The header of this CSV file is shown below.
first,last,email,affiliation,country,roles,tags,collaborators,follow,"topic: ...","topic: ...",...
We collect the availability of PC member to attend the PC meeting using Doodle. We have two discussion days which divided into 1-hour slot to let each PC member choose which time slots they are available. Alternatively, you can also use Google Form to collect this data. Don't forget to collect the email used in HotCRP to make us easier to post-process the data.

The script will generate discussion schedule for each paper based on this priority.
- The availability of PC reviewer; the more PC reviewer available, the more likely the paper will be scheduled.
- The similarity of PC reviewer with previous scheduled paper; this to make Zoom Room Switching more seamless.
- The similarity of PC member in conflict with previous scheduled paper; this to make Zoom Room Switching more seamless.
The script is not perfect; it may schedule more paper at a time window, especially when the paper has very difficult time window in which all PC reviewer can attend. You may need to adjust the schedule by yourself; at least you have something to start with. You may need to adjust parameter target_paper_per_timeslot for load-balancing between timeslot. Try to reduce or increase the target to get the best scheduling for you.
-
Script
Use script
s06_paper_discussion_window.pyto accomplish this task. -
Input There are five CSV files that are used as input to this script. Because of the complicated data, at this point, we do not provide sample data for this script.
-
The CSV file that contains the list papers alongside of their authors.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectAuthorsonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
paper,title,first,last,email,affiliation,country,iscontact
-
The CSV file that contains the list papers alongside with its data.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectCSVonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
ID,Title,Authors,"# Reviews",Status,OveMer,Tags -
The CSV file that contains the list papers alongside with its PC conflict.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectPC ConflictonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
paper,title,first,last,email,conflicttype
-
The CSV file that contains the list papers alongside with its PC Reviewer Assignment.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectPC assignmentsonReview assignmentssubmenu, then clickGo.The header of this CSV file is shown below.
paper,action,email,round,title
-
The CSV file that contains the PC availability for each time slots.
This file is created manually from Doodle by exporting the doodle data to Microsoft Excel. The numbered columns are the time slot defined in the Doodle.
The header of this CSV file is shown below.
hotcrp_name,doodle_name,hotcrp_email,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,
-
-
Output
The script will output a schedule for paper discussion. Each column represents the time slot defined in the Doodle. It will output a tuple
[a, b]whereais the paper number andbis the scheduling indicator. The scheduling indicator equal to0means that all PC reviewer can attend on that section. The more negative the number, the less likely all PC reviewers can attend the paper discussion. Currently, the script will aggressively schedule all paper to achieve0scheduling indicator.The header of this CSV file is shown below.
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16
Finally, we want to also create Zoom meeting breakout room pre-assigned configuration. You will need to collect email used by each PC member to login into the zoom account since the pre-assigned configuration will identify each participant based on this email. We use Google Form to collect one primary zoom email and one secondary zoom email (optional) alongside the full name and email address used in HotCRP. The generated CSV is located in folder sample-data/output/zoom and named based on the paper number. It can be uploaded to the Zoom Web Configuration by following the PDF for the instructions.
There are three rooms configured on Zoom: main room, conflict room, and discussion room. The main room is where all participants first come after admitted to the meeting from waiting room. As the discussion progresses, the conflict room and discussion room are created dynamically, based on which paper is being discussed. All of PC members that are in conflict with the paper will be moved automatically to conflict room while the rest will join the discussion in discussion room. If there is PC members who get admitted to the meeting after the breakout room created, they will stay in main room until the room management move them manually based on the conflict list.
-
Script
Use script
s07_zoom_meeting_generator.pyto accomplish this task. -
Input
There are five CSV files that are used as input to this script. Because of the complicated data, at this point, we do not provide sample data for this script.
-
The CSV file that contains the list papers alongside of their authors.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectAuthorsonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
paper,title,first,last,email,affiliation,country,iscontact
-
The CSV file that contains the list papers alongside with its data.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectCSVonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
ID,Title,Authors,"# Reviews",Status,OveMer,Tags -
The CSV file that contains the list papers alongside with its PC conflict.
This file is obtained from HotCRP by clicking
Searchon the Search FieldAllinSubmitted. Then, move to the bottom of the page, clickselect all xxxand clickDownload. SelectPC ConflictonPaper Informationsubmenu, then clickGo.The header of this CSV file is shown below.
paper,title,first,last,email,conflicttype
-
The CSV file that contains the list of DBLP-only conflict and HotCRP-only conflict for each PC member.
The header of this CSV file is shown below.
full_name,email,conflict_only_dblp_name,conflict_only_dblp_url,conflict_only_hotcrp
This file is obtained from DBLP and HotCRP Crosscheck section.
-
The CSV file that contains the PC members zoom email.
This file is created manually from Google Form to collect the email address used to login into Zoom Client for each PC member.
The header of this CSV file is shown below.
Name,Institution,email,hotcrp_email,Zoom email 1,Zoom email 2
-
-
Output The script outputs some files organized in four folder.
-
zoom and zoom_hashed
This contains the CSV files to upload to the Zoom Web Configuration for break-out room pre-assignment. In the unhashed version, the CSV file has the name equal to the paper number while in hashed version, the paper number is hashed.
-
conflict and conflict_hashed
This contains text files that explicitly says which PC members are in conflict with each paper. In the unhashed version, the text file has the name equal to the paper number while in hashed version, the paper number is hashed. This file is useful if you need to move zoom meeting participants manually, in case they join the meeting late (e.g., after breakout room has been created).
-
Paper Summary
A csv file contains the summary of the paper.
-