Criado pelo Linkedin e posteriormente doada para a Apache Foundation, o Apache Kafka é uma plataforma de streaming distribuída, mas o que isso significa?
Uma plataforma de streaming possui três recursos principais:
-
Publique e assine fluxos de registros, semelhantes a uma fila de mensagens ou sistema de mensagens corporativo;
-
Armazene fluxos de registros de maneira durável e tolerante a falhas;
-
Processe fluxos de registros conforme eles ocorrem;
Kafka é geralmente usado para duas grandes classes de aplicativos:
-
Construção de pipelines de dados de streaming em tempo real que obtêm dados entre sistemas ou aplicativos de maneira confiável.
-
Construção de aplicativos de streaming em tempo real que transformam ou reagem aos fluxos de dados.
Para entender como Kafka faz essas coisas, vamos nos aprofundar e explorar os recursos de Kafka de baixo para cima.
Primeiro alguns conceitos:
-
O Kafka é executado como um cluster em um ou mais servidores que podem abranger vários datacenters.
-
O cluster Kafka armazena fluxos de registros em categorias chamadas tópicos.
-
Cada registro consiste em uma chave, um valor e data / hora.
O Kafka possui 5 core APIs:
O Producer API permite que um aplicativo publique um fluxo de registros em um ou mais tópicos Kafka.
O Consumer API permite que um aplicativo assine um ou mais tópicos e processe o fluxo de registros produzidos para eles.
A Streams API permite que um aplicativo atue como um processador de stream, consumindo um stream de entrada de um ou mais tópicos e produzindo um stream de saída para um ou mais tópicos de saída, transformando efetivamente os fluxos de entrada em fluxos de saída.
A Connector API permite criar e executar produtores ou consumidores reutilizáveis que conectam tópicos Kafka a aplicativos ou sistemas de dados existentes. Por exemplo, um conector para um banco de dados relacional pode capturar todas as alterações em uma tabela.
A Admin API permite gerenciar e inspecionar tópicos, intermediários e outros objetos Kafka.
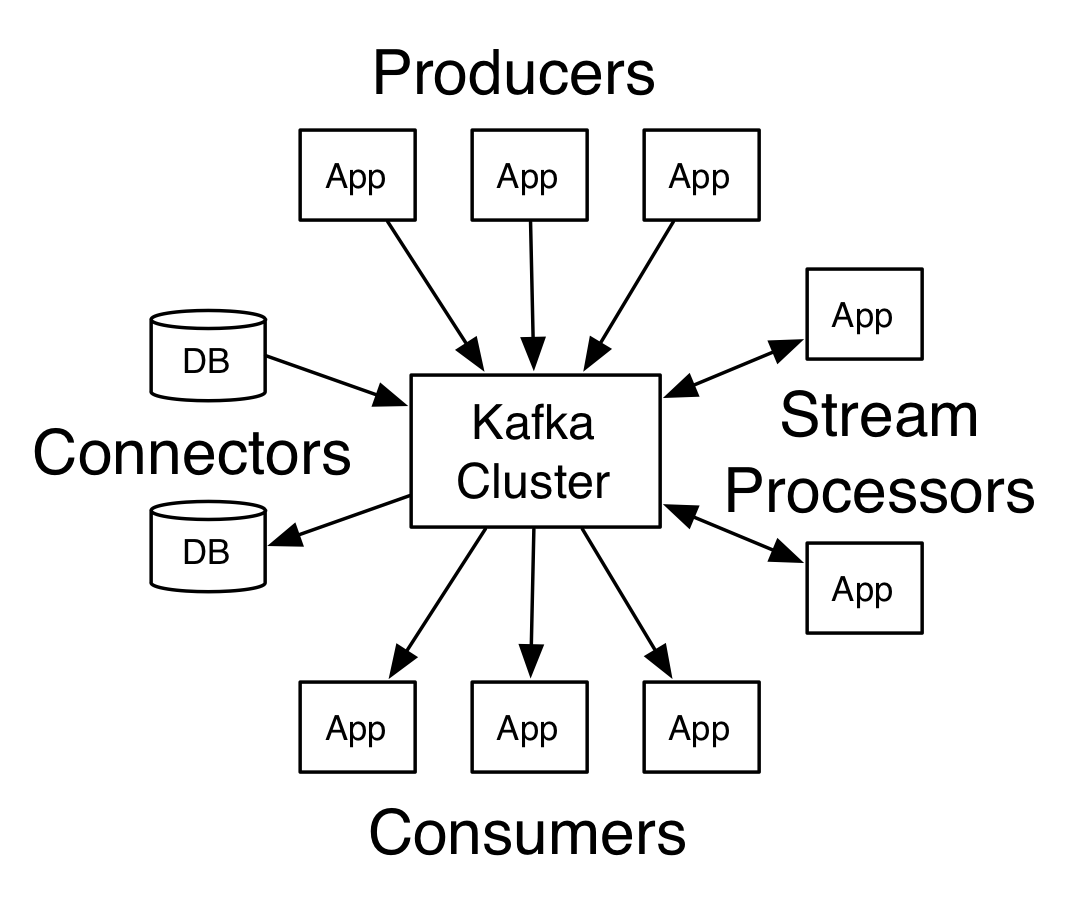
fonte: https://kafka.apache.org
Vamos primeiro mergulhar na abstração principal que Kafka fornece um fluxo de registros - o tópico.
Um tópico é um nome de categoria ou feed no qual os registros são publicados. Os tópicos no Kafka são sempre multi-assinantes; isto é, um tópico pode ter zero, um ou muitos consumidores que assinam os dados gravados nele.
Para cada tópico, o cluster Kafka mantém um log particionado semelhante a este:
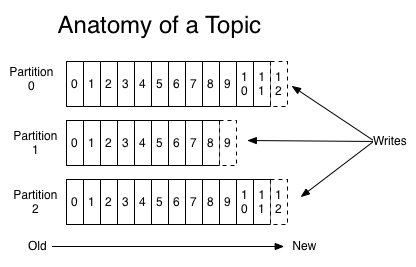
fonte: https://kafka.apache.org
Cada partição é uma sequência imutável e ordenada de registros que é continuamente anexada a - um log de confirmação estruturado. Cada registro nas partições recebe um número de identificação seqüencial chamado deslocamento que identifica exclusivamente cada registro na partição.
O cluster Kafka persiste de maneira duradoura em todos os registros publicados - tenham ou não sido consumidos - usando um período de retenção configurável. Por exemplo, se a política de retenção for definida como dois dias, nos dois dias após a publicação de um registro, ela estará disponível para consumo, após o que será descartada para liberar espaço. O desempenho do Kafka é efetivamente constante em relação ao tamanho dos dados, portanto, armazenar dados por um longo tempo não é um problema.
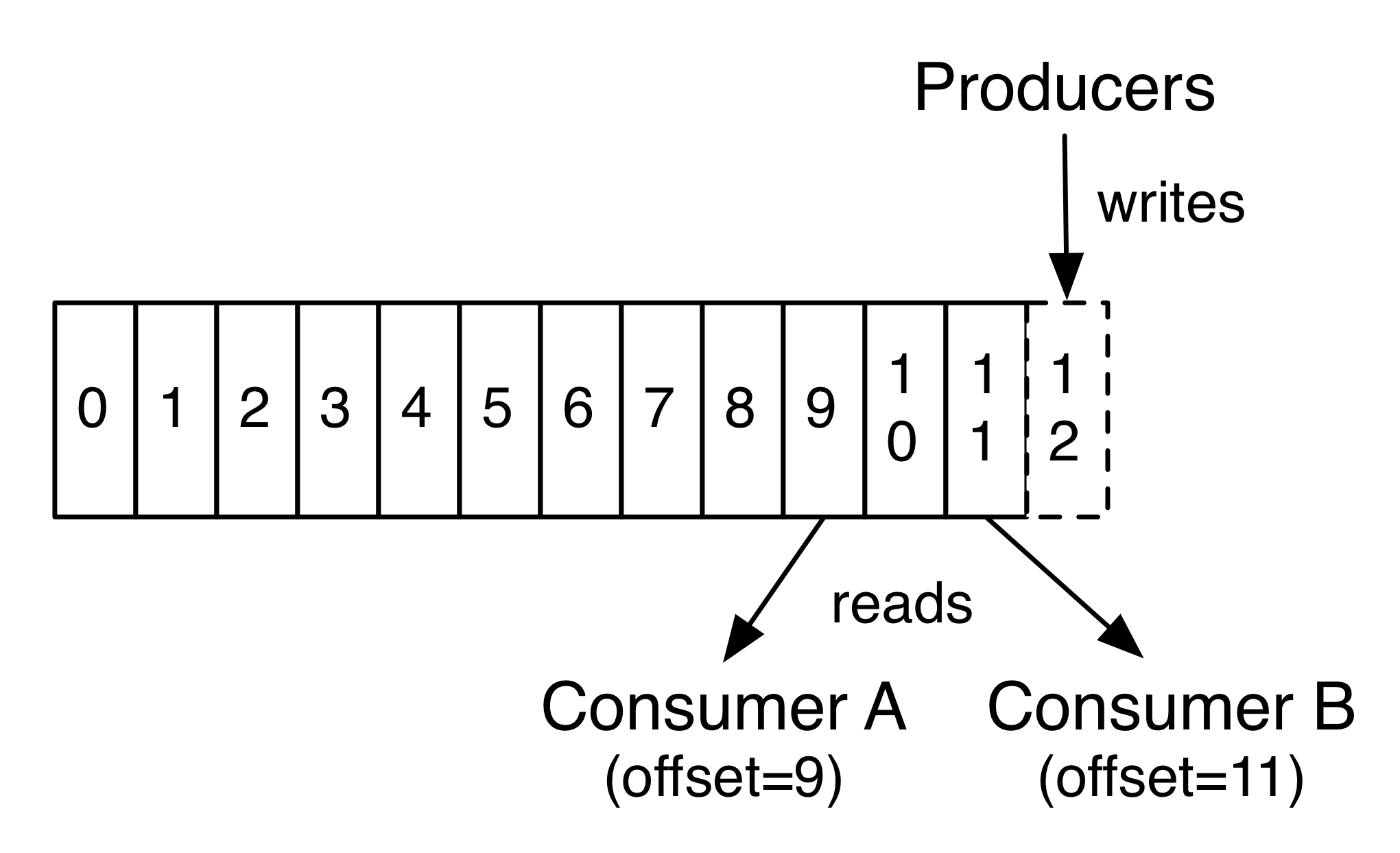
fonte: https://kafka.apache.org
De fato, os únicos metadados retidos por consumidor são a compensação ou a posição desse consumidor no log. Essa compensação é controlada pelo consumidor: normalmente um consumidor avançará sua compensação linearmente enquanto lê registros, mas, de fato, como a posição é controlada pelo consumidor, pode consumir registros em qualquer ordem que desejar. Por exemplo, um consumidor pode redefinir para um deslocamento mais antigo para reprocessar dados do passado ou pular para o registro mais recente e começar a consumir "agora".
Essa combinação de recursos significa que os consumidores Kafka são muito baratos - eles podem ir e vir sem muito impacto no cluster ou em outros consumidores. Por exemplo, você pode usar nossas ferramentas de linha de comando para "ajustar" o conteúdo de qualquer tópico sem alterar o que é consumido por qualquer consumidor existente.
As partições no log servem a vários propósitos. Primeiro, eles permitem que o log seja dimensionado além de um tamanho que caiba em um único servidor. Cada partição individual deve caber nos servidores que a hospedam, mas um tópico pode ter muitas partições para poder lidar com uma quantidade arbitrária de dados. Segundo, eles agem como a unidade do paralelismo - mais sobre isso daqui a pouco.
Os produtores publicam dados nos tópicos de sua escolha. O produtor é responsável por escolher qual registro atribuir a qual partição dentro do tópico. Isso pode ser feito de maneira round-robin simplesmente para equilibrar a carga ou pode ser feito de acordo com alguma função de partição semântica (digamos, com base em alguma chave no registro). Mais sobre o uso do particionamento em um segundo!
Os consumidores se rotulam com um nome de grupo de consumidores e cada registro publicado em um tópico é entregue a uma instância de consumidor em cada grupo de consumidores assinante. As instâncias do consumidor podem estar em processos separados ou em máquinas separadas.
Se todas as instâncias do consumidor tiverem o mesmo grupo de consumidores, os registros serão efetivamente balanceados por carga sobre as instâncias do consumidor.
Se todas as instâncias do consumidor tiverem grupos de consumidores diferentes, cada registro será transmitido para todos os processos do consumidor.
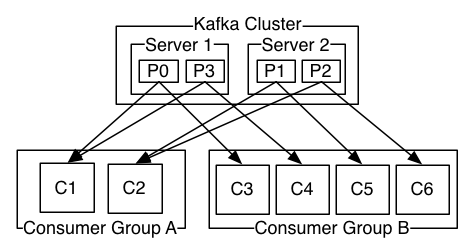
fonte: https://kafka.apache.org
Um cluster Kafka de dois servidores que hospeda quatro partições (P0-P3) com dois grupos de consumidores. O grupo de consumidores A tem duas instâncias de consumo e o grupo B tem quatro.
Mais comumente, no entanto, descobrimos que os tópicos têm um pequeno número de grupos de consumidores, um para cada "assinante lógico". Cada grupo é composto de muitas instâncias do consumidor para escalabilidade e tolerância a falhas. Isso nada mais é do que a semântica de publicação e assinatura, em que o assinante é um cluster de consumidores em vez de um único processo.
A maneira como o consumo é implementado no Kafka é dividindo as partições no log pelas instâncias do consumidor, para que cada instância seja o consumidor exclusivo de um "compartilhamento justo" de partições a qualquer momento. Esse processo de manutenção da associação ao grupo é tratado pelo protocolo Kafka dinamicamente. Se novas instâncias ingressarem no grupo, elas assumirão algumas partições de outros membros do grupo; se uma instância morrer, suas partições serão distribuídas para as instâncias restantes.
O Kafka fornece apenas uma ordem total sobre os registros dentro de uma partição, não entre diferentes partições em um tópico. A ordenação por partição combinada com a capacidade de particionar dados por chave é suficiente para a maioria dos aplicativos. No entanto, se você precisar de um pedido total por registros, isso poderá ser alcançado com um tópico que tenha apenas uma partição, embora isso signifique apenas um processo do consumidor por grupo de consumidores.
Kafka já é utilizado por mais de 1/3 das empresas da lista da fortune 500 e 7 dos 10 maiores banco do mundo.
Ele pode ser utilizado para diferentes finalidades. Você pode ver uma lista completa delas no site.
1 - Atualizar o SO:
sudo apt update2 - Instalar o JDK 8:
sudo apt install openjdk-8-jdk3 - Verificar se a instalação ocorreu com sucesso:
java -version4 - Baixar os binários do Kafka, neste link.
5 - Descompactar os binários:
tar -xvf kafka_2.12-2.5.0.tgz6 - Renomear e mover a pasta para o caminho ~
mv kafka_2.12-2.5.0 kafka
mv kafka/ ~7 - Editar o arquivo .bashrc para reconhecer os comandos utilizados no Kafka como por exemplo o kafka-topics.sh
gedit .bashrcIncluir no final do arquivo .bashrc
export PATH=/home/seu_nome_usuario/kafka/bin:$PATH8 - Acessar o diretório do kafka e incluir as pastas data/kafka e data/zookeeper. São nesses diretórios que o Apache Kafka armaneza os dados dos tópicos e logs.
cd kafka/
mkdir data
cd data
mkdir kafka
mkdir zookeeper9 - Editar o arquivo zookeeper.properties e alterar o parâmetro dataDir para /home/seu_usuario/kafka/data/zookeeper e salvar as alteração:
cd kafka/config
gedit zookeeper.properties10 - Editar o arquivo server.propertiese alterar o parâmetro log.dirs para /home/seu_usuario/kafka/data/kafka e salvar as alterações
cd kafka/config
gedit server.properties11 - Subir os serviços Zookeeper e Kafka:
zookeeper-server-start.sh /home/seu_usuario/kafka/confi/zookeeper.properties
kafka-server-start.sh /home/seu_usuario/kafka/confi/server.propertiesAcessar o diretório com o arquivo docker-compose.yml e executar o comanado abaixo:
docker-compose up -d- Confluent
https://www.confluent.io/confluent-cloud
- AWS
https://aws.amazon.com/pt/msk/
- Azure
https://azure.microsoft.com/en-us/services/event-hubs/
- GCP
https://cloud.google.com/pubsub/
- Kubernetes
https://docs.confluent.io/5.1.2/installation/installing_cp/cp-helm-charts/docs/index.html
https://docs.confluent.io/current/installation/operator/index.html
kafka-topics.sh —-bootstrap-server localhost:9092 —-listkafka-topics.sh --bootstrap-server localhost:9092 --topic <nome_topico> --describekafka-topics.sh —-bootstrap-server localhost:9092 —-create —-topic <nome_topico>kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic <nome_topico> --partitions 4kafka-topics.sh —-bootstrap-server localhost:9092 —-delete —-topic <nome_topico>kafka-console-producer.sh —-bootstrap-server localhost:9092 —-topic <nome_topico>
> { mensagem: “mensagem teste” }kafka-console-consumer.sh —-bootstrap-server localhost:9092 —-topic <nome_topico> kafka-console-consumer.sh —-bootstrap-server localhost:9092 —-topic <nome_topico> --group <nome_grupo>Abaixo seguem alguns links que utilizei neste post: Kafka documentation