CADM+: Confusion-based Learning Framework With Drift Detection and Adaptation for Real-time Safety Assessment
Real-time safety assessment (RTSA) of dynamic systems holds substantial implications across diverse fields, including industrial and electronic applications. However, the complexity and rapid flow nature of data streams, coupled with the expensive label cost, pose significant challenges. To address these issues, a novel confusion-based learning framework, termed CADM+, is proposed in this paper. When drift occurs, the model is updated with uncertain samples, which may cause confusion between existing and new concepts, resulting in performance differences. The cosine similarity is used to measure the degree of such conceptual confusion in the model. Furthermore, the change of standard deviation within a fixed-size cosine similarity window is introduced as an indicator for drift detection. Theoretical demonstrations show the asymptotic increase of cosine similarity. Additionally, the approximate independence of the change in standard deviation with the number of trained samples is indicated. Finally, extreme value theory is applied to determine the threshold of judging drifts. Several experiments are conducted to verify its effectiveness. Experimental results prove that the proposed framework is more suitable for RTSA tasks compared to state-of-the-art algorithms.

construction of confusion model module updates an existing classifier with a new set of labeled data to obtain a new model, aiming to generate a confusion model.
In drift detection module, upon the arrival of a new data chunk, the classifiers before and after incremental update will utilize the unlabeled data within it to calculate the cosine similarity. The resulting cosine similarity is then incorporated into a sliding window to compute the concept drift detection metric and threshold.
In model update module, if the concept drift is detected, all samples in the data chunk are labeled, and the classifier is retrained. Otherwise, part of the samples are selected for annotation to update the model. Subsequently, the detection and update modules iterate in a loop.
- Download files, then directly run the main.py file. You can also modify parameters and datasets in the main file.
- Example:
from CADM_plus_strategy import *
t1 = time.time()
stream = FileStream('datasets/LAbrupt.csv')
CADM_plus = CADM_plus_strategy(q = 0.03, stream=stream, train_size = 200, chunk_size = 100, label_ratio = 0.2,
class_count = stream.n_classes, max_samples=1000000, k=500, classifier_string="NB")
CADM_plus.main()
t2 = time.time()
print('total time:{}s'.format(t2 - t1))
- Output:
------------------ Result ------------------
The count of correct predicted samples: 922667
The count of all predicted samples: 999800
overall accuracy = 92.28515703140629%
label_cost = 0.22368000000000002
total time:58.81265616416931s
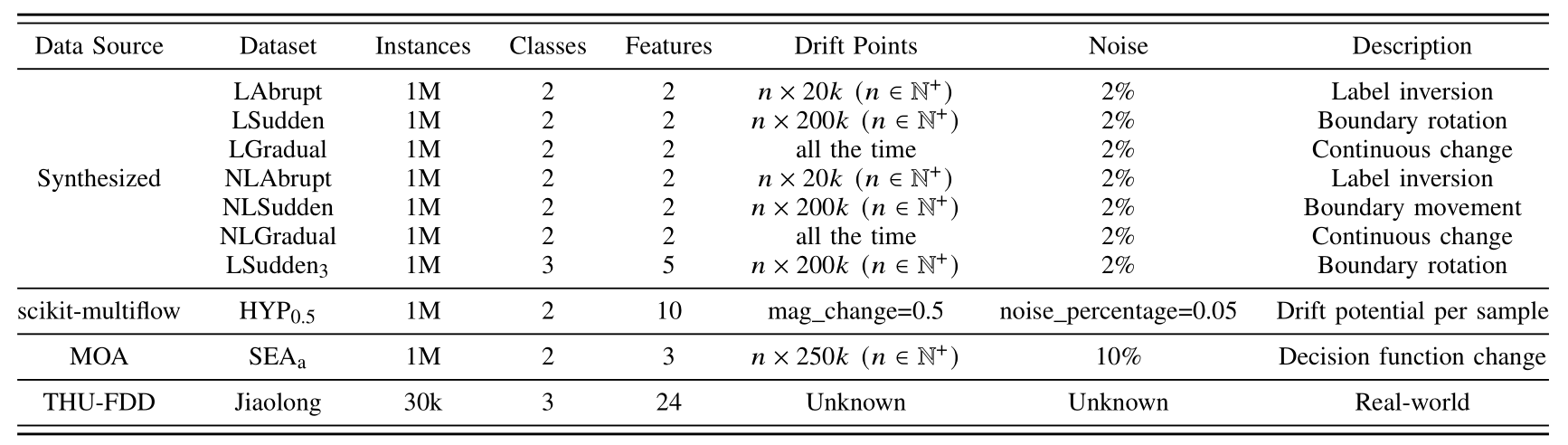
- Data distribution display:
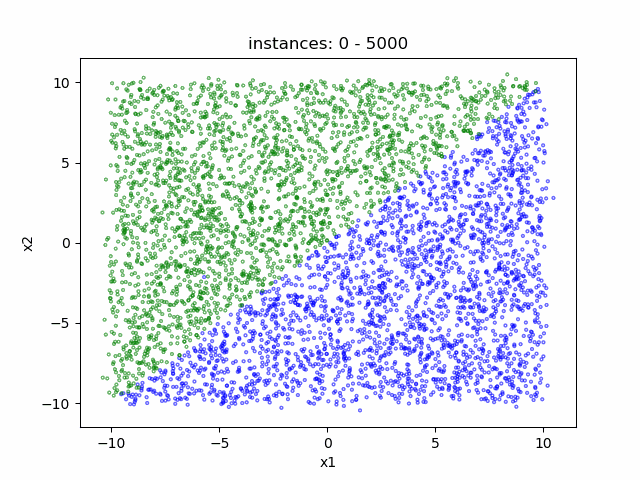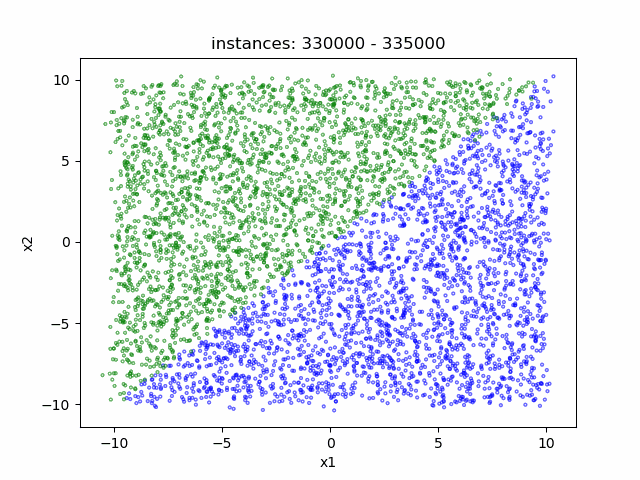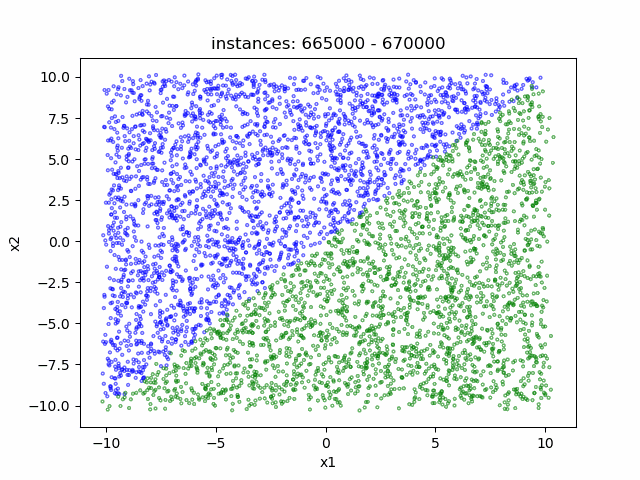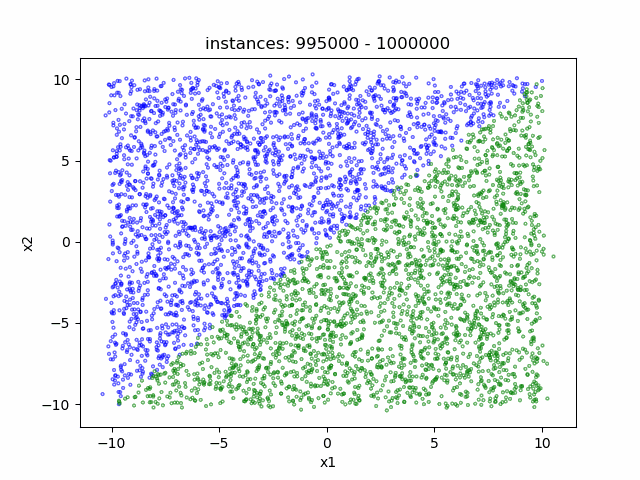


(a) LAbrupt (b) LSudden_3 (c) LGradual



(a) NLAbrupt (b) NLSudden (c) NLGradual
- HYP_05 (from scikit-multiflow):
import csv
from skmultiflow.data import HyperplaneGenerator
import numpy as np
stream = HyperplaneGenerator(mag_change=0.5)
X, y = stream.next_sample(1000000)
with open('HYP_05.csv', 'w', newline='') as fp:
writer = csv.writer(fp)
writer.writerows(np.column_stack((X, y)))
- SEA_a (from MOA):
WriteStreamToARFFFile -s (ConceptDriftStream -s generators.SEAGenerator -d (ConceptDriftStream -s (generators.SEAGenerator -f 2) -d (ConceptDriftStream -s generators.SEAGenerator -d (generators.SEAGenerator -f 4) -p 250000 -w 50) -p 250000 -w 50) -p 250000 -w 50) -f (SEA_a.arff) -m 1000000
Please refer to
https://github.com/THUFDD/JiaolongDSMS_datasets

@ARTICLE{10458267,
author={Hu, Songqiao and Liu, Zeyi and Li, Minyue and He, Xiao},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={CADM $+$: Confusion-Based Learning Framework With Drift Detection and Adaptation for Real-Time Safety Assessment},
year={2024},
volume={},
number={},
pages={1-14},
doi={10.1109/TNNLS.2024.3369315}}
Welcome to communicate with us: hsq23@mails.tsinghua.edu.cn
We extend our sincere gratitude to our THUFDD Group, led by Prof. Xiao He and Prof. Donghua Zhou, for the invaluable support and contributions to the development of this scheme.
Disclaimer: This scheme is provided as-is without any warranty. Use at your own risk.