English | 中文
If your computer has a decent configuration and Docker is installed, you can run docker-compose-init.yml, and the database and Redis will be initialized later.
Note that the mysql8.0/data folder must be empty for the initialization of inventory data.
Reset inventory-related operations can be found in the SQL folder.
When a customer places an order, it is desired to lock the inventory in the inventory detail table for the products. The simplified inventory detail table is shown below:
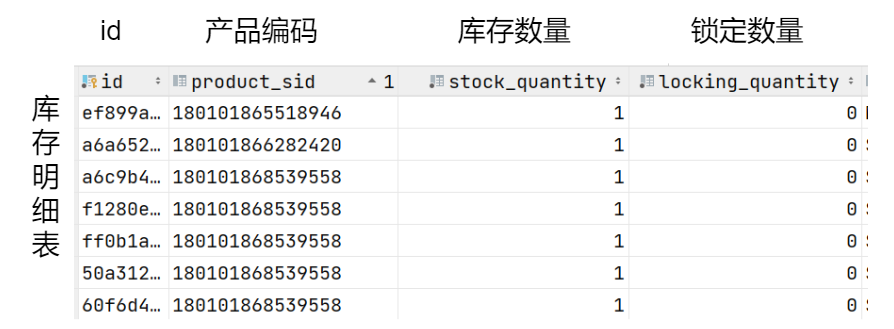
As can be seen, a single product code may have multiple inventory details. A customer's order will roughly lock several dozen inventory rows, with the following requirements:
- As fast as possible, with high concurrency, and support for multiple nodes
- To maintain data consistency, it's better not to use the Redis deduction scheme
- When locking the inventory, insert lock records in the inventory lock log table at the same time
By analyzing the existing system solution, it was found that the time spent on locking inventory operations is mainly wasted on updating the locked quantity of inventory details. In order to prevent overselling, inventory verification must be added to each update (as shown below). If it fails, it must be rolled back. Moreover, MySQL does not provide a native batch update method, so each inventory row has to execute one SQL statement, resulting in a longer lock time.
WHERE (stock_quantity - locking_quantity) > 0The first step in optimization is to improve the speed of batch locking. Is there any way to simulate batch updates in MySQL?
The answer is to use the SQL WHEN statement, and assemble the following SQL in the program:
UPDATE p_stock_instance a
SET a.locking_quantity = CASE a.id
WHEN '027dbba9c04a4ef0baab3983c64bc0b31123' THEN 3
WHEN '025d4574cd934b69993703e7e99e8ca43' THEN 6
WHEN '027dbba9c04a4ef0baab3983c64bc0b313' THEN 2 END,
a.update_date = now()
WHERE CASE a.id
WHEN '027dbba9c04a4ef0baab3983c64bc0b31123' THEN (a.stock_quantity - a.locking_quantity) >= 3
WHEN '025d4574cd934b69993703e7e99e8ca43' THEN (a.stock_quantity - a.locking_quantity) >= 6
WHEN '027dbba9c04a4ef0baab3983c64bc0b313' THEN (a.stock_quantity - a.locking_quantity) >= 2
ELSE 0 END;After the SQL execution is completed, the number of updated rows will be returned. By comparing the number of updated rows with the expected number in the program, you can determine whether the update is successful. Here's a schematic of the program:
Integer num = pStockInstanceDao.operationStockSmallData(operationMapping);
if (num != operationMapping.size()) {
throw new RuntimeException("操作失败");
}This method updates very quickly. In my tests, updating 20,000 inventory records took about 17 seconds. But there is an even faster way.
Using the temporary table to update inventory method performs much better than the WHEN statement when dealing with large amounts of data. In test conditions, updating 20,000 inventory records took about 1 second.
Temporary tables are a special kind of table in MySQL with the following characteristics:
- Temporary tables are visible within the thread, and other threads cannot see temporary tables created by different threads.
- Temporary tables are destroyed when the thread exits.
- When a temporary table has the same name as a regular table, MySQL prioritizes the temporary table for operations.
The statement to create a temporary table in this case is as follows:
create temporary table temp_stock_operation
(
stock_instance_id varchar(64) unique not null comment '库存实例ID',
op_num int not null comment '操作数量',
success tinyint(1) default 0 not null comment '是否成功'
);stock_instance_id corresponds to the id in the inventory detail table.
When updating inventory::
- Create a temporary table
- First, insert the inventory quantity to be locked for each inventory detail row into the temporary table
- Then use the
UPDATE JOINstatement to batch update the inventory, and save the information about whether the update was successful in thesuccessfield of the temporary table - Count the
successfield to determine whether to roll back - Delete the temporary table
The UPDATE statement used is as follows:
update temp_stock_operation o inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;Check if it was successful, the return value of this statement is 0 or 1.
select count(*) = 0 as success
from temp_stock_operation
where success = 0;Finally, delete the temporary table:
drop temporary table temp_stock_operation;Although the temporary table solution is very fast when updating large amounts of data, when using this method to update a few dozen inventory rows, the speed will slow down again. In my tests, updating about 30-40 rows took almost the same time as updating 20,000 rows.
That is, the performance of this update statement will decrease when the number of rows is small.
update temp_stock_operation o inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;Analyzing its execution plan, it was found that when the number of updated rows is less than 45, the JOIN operation does not use the index but performs a full table scan, resulting in reduced performance. Even using the following SQL statement to force the index is useless.
update temp_stock_operation o force index for join (stock_instance_id)
inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;So we need to combine these two methods to achieve the best performance.
if (operationMapping.size() < 45) {
// WHEN 语句方案
Integer num = pStockInstanceDao.operationStockSmallData(operationMapping);
if (num != operationMapping.size()) {
throw new RuntimeException("操作失败");
}
} else {
// 临时表方案
Boolean success = pStockInstanceDao.operationStockBigData(operationMapping);
if (!success) {
throw new RuntimeException("操作失败");
}
}Due to the race condition between multiple threads during concurrency, inventory deduction may fail. As mentioned earlier, a single product may correspond to multiple inventory details in the inventory detail table. That is, if concurrency causes a failure in deducting one inventory detail, this product may still have inventory in other inventory details. Also, regardless of whether the update is successful, the thread will hold the write lock on the database row, which requires us to quickly release the lock when the update fails. This can lead to false reports of insufficient inventory.
One solution is as follows:
- Before querying the inventory quantity, the thread obtains a distributed lock for each product code in the order. The inventory query operation is performed only when all product code locks have been obtained.
- After updating the inventory, the thread releases the product code locks it holds.
RLock[] locks = productSids.seream()
.distinct()
.map(key -> "ced:pStockInstance:" + key)
.sorted()
.map(key -> redissonClient.getLock(key))
.toArray(RLock[]::new);
RLock skuLock = redissonClient.getMultiLock(locks);
// 加锁
skuLock.lock();
// 解锁
skuLock.unlockAsync();This method will cause the program to degrade into serial execution and slow efficiency when all orders lock the same product.
Since we have already optimized the inventory update method to be fast enough, to efficiently solve the race condition problem, we can merge the parameters of various requests in the application and then use a single thread to batch deduct, thereby avoiding conflicts between threads during deduction.
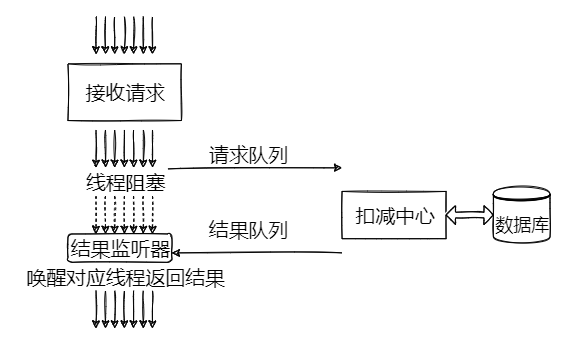
The key code for making threads block and wake up is as follows:
public class GuardedObject<T, K> {
//受保护的对象
T obj;
final Lock lock = new ReentrantLock();
final Condition done = lock.newCondition();
final int timeout = 60;
//保存所有GuardedObject
final static Map<Object, GuardedObject> gos = new ConcurrentHashMap<>();
public GuardedObject(K key) {
this.key = key;
}
K key;
// 1. 被请求线程通过唯一 key 获得阻塞对象,然后将 key 存入消息,发送到扣减中心
public static <K> GuardedObject create(K key) {
GuardedObject go = new GuardedObject(key.toString());
gos.put(key, go);
return go;
}
// 2. 被请求线程稍后调用阻塞对象的该方法,阻塞,等待被唤醒
public Optional<T> get(Predicate<T> p) {
lock.lock();
Long start = System.currentTimeMillis();
try {
while (!p.test(obj)) {
done.await(timeout, TimeUnit.SECONDS);
if (System.currentTimeMillis() - start >= timeout * 1000) {
gos.remove(key);
break;
}
}
return Optional.ofNullable(obj);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
// 3. 结果监听器根据结果消息中的 key 找到对应阻塞对象,传入结果并唤醒对应线程
public static <K, T> void fireEvent(K key, T obj) {
GuardedObject go = gos.remove(key);
if (go != null) {
go.onChanged(obj);
}
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
}In order to obtain the worst-case performance in the experimental environment, 25,000 identical items were stored in the inventory details, and the inventory quantity of each item was set to 1.
I started two services on my computer to receive requests and launched several threads to deduct the inventory of this product. The results are as follows:
| Number of Request Threads | Total Locked Rows | Total Processing Time |
|---|---|---|
| 100 | 1000 | 1 S |
| 500 | 5000 | 3 S |
| 1000 | 10000 | 4 S |
| 2000 | 20000 | 8 S |
| 3000 | 25000 | 12 S |
Here are some points to note that I discovered while writing the code:
When creating a temporary table, create a unique index for stock_instance_id, as this field will serve as the condition for the JOIN statement. In practice, the performance will be poor without a unique index.
create temporary table temp_stock_operation
(
stock_instance_id varchar(64) unique not null comment '库存实例ID', The inventory deduction thread in the deduction center reads messages directly from the message queue, which is less efficient. In this case, you can create a new local queue and use other threads to transfer messages from the message queue to the local queue. This allows the deduction thread to operate on the local queue instead of the message queue, greatly improving deduction efficiency.