Yidong Wang*1,2 Zhuohao Yu*1
Zhengran Zeng1 Linyi Yang2 Qiang Heng3 Cunxiang Wang2 Hao Chen4 Chaoya Jiang1 Rui Xie1
Jindong Wang5 Xing Xie5 Wei Ye†1 Shikun Zhang†1 Yue Zhang†2
*: Co-first Authors, work done during Yidong's internship at Westlake University. †: Co-corresponding Authors
1 Peking University, 2 Westlake University,
3 North Carolina State University, 4 Carnegie Mellon University, 5 Microsoft Research Asia
This is the official repository for PandaLM: ReProducible and Automated Language Model Assessment.
Paper: PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
PandaLM aims to provide reproducible and automated comparisons between different large language models (LLMs). By giving PandaLM the same context, it can compare the responses of different LLMs and provide a reason for the decision, along with a reference answer. The target audience for PandaLM may be organizations that have confidential data and research labs with limited funds that seek reproducibility. These organizations may not want to disclose their data to third parties or may not be able to afford the high costs of secret data leakage using third-party APIs or hiring human annotators. With PandaLM, they can perform evaluations without compromising data security or incurring high costs, and obtain reproducible results. To demonstrate the reliability and consistency of our tool, we have created a diverse human-annotated test dataset of approximately 1,000 samples, where the contexts and the labels are all created by humans. Our results indicate that PandaLM-7B achieves 93.75% of GPT-3.5's evaluation ability and 88.28% of GPT-4's in terms of F1-score on our test dataset.. More papers and features are coming soon.

This repository contains:
- The codes for training PandaLM
- The human-annotated test dataset with ~1k samples for validating PandaLM's ability to evaluate LLMs
- The model weights of PandaLM
- The codes and configs for instruction tuning other foundation models such as Bloom, OPT and LLaMA, etc.
- [2024/01/16] Pandalm is accepted by ICLR 2024!
- [2023/07/25] We share our tuned Alpaca and PandaLM-Alpaca at Huggingface. Besides, we uploaded our tuned Alpaca and PandaLM-Alpaca to Open LLM Leaderboard, the results prove that using PandaLM can boost the instruction tuning performance.
- [2023/04/30] We are pleased to announce the release of PandaLM 1.0 as an open-source tool for evaluating LLMs with reliability. To further demonstrate the effectiveness of PandaLM, we are also sharing a human-annotated test dataset.
- [2023/06/08] We release our paper on arxiv: PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization

As shown above, an iteration of the instruction tuning of LLMs includes training and evaluation. Each iteration refers to changes in hyper-paramters or fine tuning algorithms. The instruction tuning of LLMs can be done within a few GPU hours even using a consumer-grade GPU, thanks to parameter-efficient-tuning methods. However, the human-based and API-based evaluations can be more expensive and time consuming. Furthermore, they can be inconsistent and unreproducible due to a lack of transparency regarding LLM changelogs and subjectivity in human annotations. Moreover, the use of API-based evaluations can result in potential high costs of remediation after secret data leakage. Formally, the total cost of instruction tuning LLMs is
To address these challenges, we propose an evaluation model named PandaLM, which can ensure reproducibility, safety, and efficiency in evaluation. By automating the evaluation process, our model can achieve efficient and consistent evaluations while maintaining high evaluation ability.
To install PandaLM, follow these steps:
- Clone the repository:
git clone https://github.com/WeOpenML/PandaLM.git - Navigate to the project directory:
cd PandaLM - Install the required dependencies:
pip install -r requirements.txtor useconda env create -f conda-env.ymlif you prefer conda. Note that it's required to modifyprefixinconda-env.ymlto your conda path.
To instruction a foundation model, follow these steps:
- Install PandaLM.
- Navigate to the project directory:
cd PandaLM/pandalm - Run the demo scripts:
bash scripts/inst-tune.sh
Due to concerns about copyright issues, we do not provided the instruction tuned model. The instruction tuned model can be easily reproduced in PandaLM/pandalm/scripts/inst-tune.sh.
We have uploaded PandaLM-7B to HuggingFace, you can simply initialize the model and tokenizer with:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("WeOpenML/PandaLM-7B-v1",use_fast=False)
model = AutoModelForCausalLM.from_pretrained("WeOpenML/PandaLM-7B-v1")We offer several choices for experiencing our PandaLM. (Preparing codes..Please be patient.)
- Try PandaLM on your local machine (with a GPU having at least 24G VRAM) using a Web UI:
cd PandaLM/pandalm/
CUDA_VISIBLE_DEVICES=0 python3 run-gradio.py --base_model=WeOpenML/PandaLM-7B-v1 --server_port=<your-server-port> --server_name=<your-server-name>By default the program will listen to port 31228 on all network interfaces, access http://localhost:31228/ if you are running on a local machine or http://<your-server-name>:<your-server-port>/ if on a remote server.
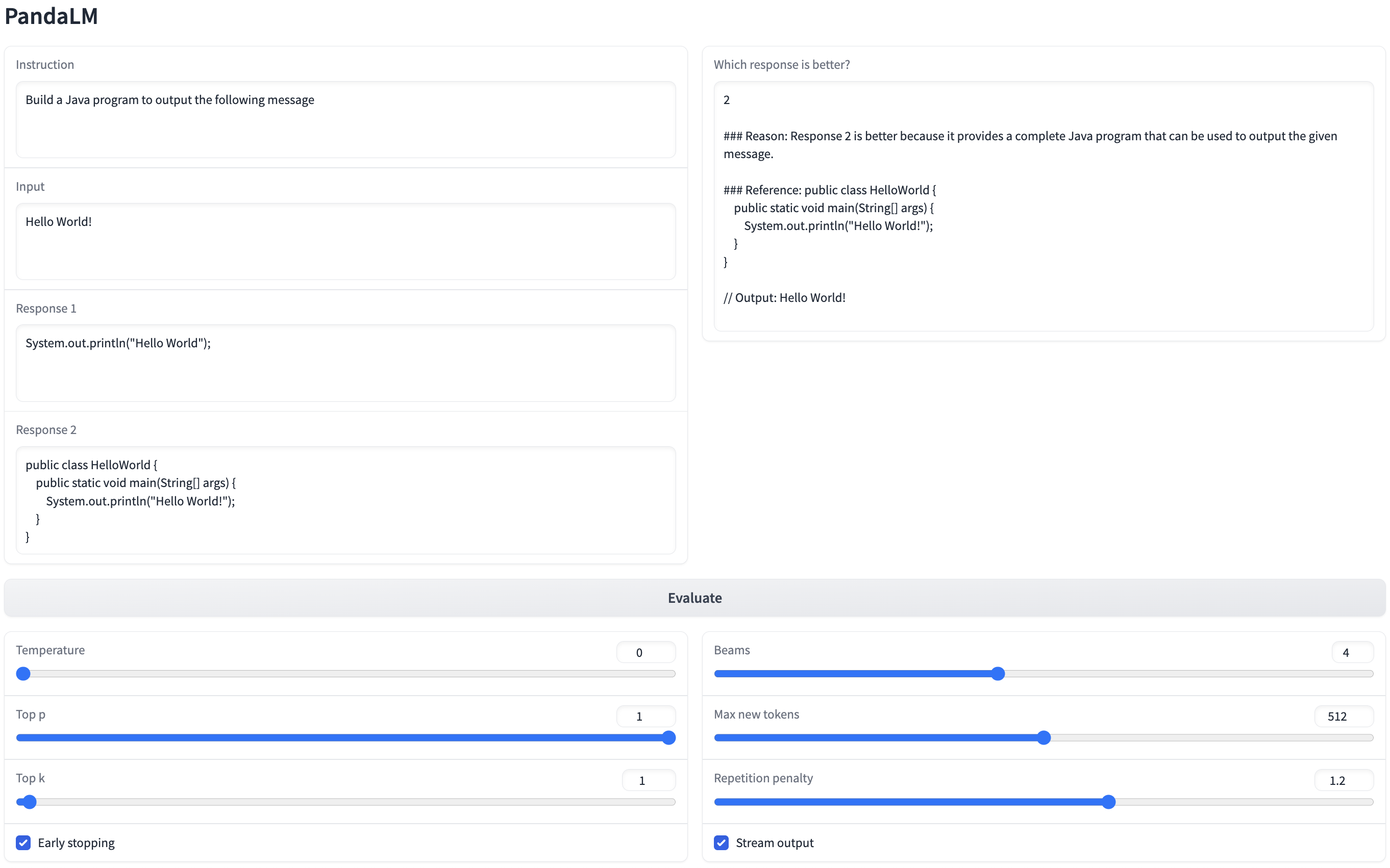
- We provide a class called
EvaluationPipelinethat can evaluate multiple candidate models using PandaLM. The constructor of this class takes in a list of candidate model paths or output JSON files if some models are not open sourced. Optionally, It also takes in the path of the PandaLM model, an input data path to load the test data, and an output data path to save the test result. Note that this demo just shows the evaluation of LLMs before instruction tuning. In practice, we need to instruction tune them first, and then pass the tuned models intoEvaluationPipeline. For more details, see the codes. You can test the candidate models in just three lines:
from pandalm import EvaluationPipeline
pipeline = EvaluationPipeline(candidate_paths=["huggyllama/llama-7b", "bigscience/bloom-7b1", "facebook/opt-6.7b"], input_data_path="data/pipeline-sanity-check.json")
print(pipeline.evaluate())This section introduces the train and test data for training and evaluating PandaLM. We will continuously update and open-source the data to improve PandaLM.
We aim to force our model not only to evaluate different responses for a given context, but also generate a reference response utilizing the given context. Thus, each instance from the training data consists of an input tuple (instruction, input, response1, response2) and an output tuple (evaluation_result, evaluation_reason, reference_response). Specifically, in the input tuple, the instructions and inputs are sampled from Alpaca 52K data and the response pairs are provided by LLaMA-7B, Bloom-7B, Cerebras-GPT-6.7B, OPT-7B and Pythia-6.9 tuned by ourselves with the same instruction data and hyper-parameters. We chose these foundation models as they are similar in size and their model weights are publicly available. The corresponding output tuple includes an evaluation result, a brief explanation for the evaluation and a reference response. Note that "1" or "2" in the evaluation result means response 1 or 2 is better and "Tie" means they are similar in quality. Since it is unaffordable to obtain millions of output tuples from human annotators and ChatGPT has the ability to evaluate LLMs to a certain extent, we follow self-instruct to get output tuples from ChatGPT(gpt-3.5-turbo) and then adopt heuristic data filtering strategy to filter noisy ones. The filtered train dataset contains 300K samples while the original unfiltered datasets have 1M samples. The train data can be found at train-data. Here is a demonstration of the train data:
{
"inputs": {
"instruction": "Find an example of the given kind of data",
"input": "Qualitative data",
"response1": "An example of qualitative data is customer feedback.",
"response2": "An example of qualitative data is a customer review.",
},
"outputs": {
"evaluation_result": "Tie",
"evaluation_reason": "Both responses are correct and provide similar examples of qualitative data.",
"reference_response": "An example of qualitative data is an interview transcript."
}
}
To prove the reliability of PandaLM, we created a human-labeled test dataset that is reliable and aligned to human preference of text. Each instance of the test dataset consists of one instruction and input, two responses generated by different instruction-tuned LLMs. The task is to compare the qualities of two responses. Similar to train data, the responses are provided by LLaMA-7B, Bloom-7B, Cerebras-GPT-6.7B, OPT-7B and Pythia-6.9B instruction-tuned by ourselves with the same instruction data and hyper-parameters. After obtaining the human-labeled test dataset, we can then compare ChatGPT and PandaLM in terms of evaluation performance.
The test data is generated and sampled from the human evaluation data of self-instruct. The inputs and labels of test data are purely generated by humans and contain diverse tasks and contents. The labels are annotated independently by three different human evaluators. The data consists of a series of tasks, where each task includes an instruction, input sentence, two responses, and a label indicating the preferred response. Note that "1" or "2" means response 1 or 2 is better and "0" means they are similar in quality. Note that we exclude examples with big divergences from the origin annotated test data to make sure the IAA(Inter Annotator Agreement) of each annotator on the rest data is close to 0.85 because these filtered samples require additional knowledge or hard-to-obtain information, which makes it difficult for humans to evaluate them. The filtered test dataset contains 1K samples while the original unfiltered datasets have 2.5K samples. Here we give an example with explanations on the test set. The test data is available in ./data/testset-v1.json. We also release the test results of gpt-3.5-turbo and PandaLM-7B in ./data/gpt-3.5-turbo-testset-v1.json and ./data/pandalm-7b-testset-v1.json.
{
"index": "749",
"motivation_app": "CNN News",
"task_id": "user_oriented_task_165",
"cmp_key": "opt-7b_pythia-6.9b", ## It means response 1 is from opt-7B and response 2 is from pythia-6.9B
"instruction": "Give the news title a category. Pick a category from the list of News & Buzz, Travel, Style, Arts & Culture, Politics, Tech, and Science & Health.",
"input": "The #Banksy Exhibit in Cambridge, MA is absolutely terrific.",
"reference_response": "Arts & Culture", ## Directly copy from the self instruct repo.
"response1": "Politics",
"response2": "Arts & Culture",
"label_0": "2", # Label from Human annotator No.1
"label_1": "2", # Label from Human annotator No.2
"label_2": "2", # Label from Human annotator No.3
}
We calculate the IAA of each annotator using Cohen’s kappa. The IAA is shown below:
| Cohen’s kappa | Annotator #1 | Annotator #2 | Annotator #3 |
|---|---|---|---|
| Annotator #1 | 1 | 0.85 | 0.88 |
| Annotator #2 | 0.85 | 1 | 0.86 |
| Annotator #3 | 0.88 | 0.86 | 1 |
The label distribution of test data is:
| 0 | 1 | 2 | |
|---|---|---|---|
| Number | 105 | 422 | 472 |
Please refer to Paper: PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
We welcome contributions to PandaLM! If you'd like to contribute, please follow these steps:
- Fork the repository.
- Create a new branch with your changes.
- Submit a pull request with a clear description of your changes.
@article{pandalm2024,
title={PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization},
author={Wang, Yidong and Yu, Zhuohao and Zeng, Zhengran and Yang, Linyi and Wang, Cunxiang and Chen, Hao and Jiang, Chaoya and Xie, Rui and Wang, Jindong and Xie, Xing and Ye, Wei and Zhang, Shikun and Zhang, Yue},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
@misc{PandaLM,
author = {Wang, Yidong and Yu, Zhuohao and Zeng, Zhengran and Yang, Linyi and Heng, Qiang and Wang, Cunxiang and Chen, Hao and Jiang, Chaoya and Xie, Rui and Wang, Jindong and Xie, Xing and Ye, Wei and Zhang, Shikun and Zhang, Yue},
title = {PandaLM: Reproducible and Automated Language Model Assessment},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/WeOpenML/PandaLM}},
}
For model weights of PandaLM, we follow LLaMA license. See MODEL_LICENSE.
The train data license will be added when we uploaded train data.
The rest of this repo is under Apache License 2.0. See LICENSE.