Hands on deep learing 动手学深度学习笔记
每节课分为两部分,一部分记录部分知识点和探索的问题,另一部分记录代码和代码相关的笔记
代码来自于伯禹教育平台的ElitesAI·动手学深度学习PyTorch版
笔记总结于自己课程中的思考,课程讨论区,神经网络与深度学习
线性回归
-
定义:基于特征和标签之间的线性函数关系约束,线性回归通过建立单层神经网络,将神经网络中每一个神经元当成是函数关系中的一个参数,通过利用初始输出和目标输出建立损失,并优化损失最小的方式使得神经元的数值和真实函数参数数值最相近,从而通过网络训练得到最符合数据分布的函数关系。
-
实施步骤:
- 初始通过随机化线性函数的参数,通过输入的x,会得到一系列y_h
- 输出的y_h和真实值y之间因为神经元参数不正确产生差距,为了y_h和y能尽量地逼近,我们通过平方误差损失函数(MSE Loss)来描述这种误差。
- 类似于通过求导得到损失函数最优解的方式,我们通过梯度下降法将这种误差传递到参数,通过调整参数使误差达到最小
- 通过几轮的训练,我们得到的最小的损失值对应的神经元数值,就是描述输入输出的线性关系的最好的参数。
- 要点:
- 确定输入输出之间一定满足线性关系,这一点可以通过对x,y画图看出,只有线性关系才能使用线性回归训练得到
- 由于线性关系唯一由神经元个数决定,不同的参数个数唯一决定了这种线性关系,因此需要选择适合的特征用于线性回归
这一节中出现的有用的函数
- 使用plt绘制散点图
from matplotlib import pyplot as plt
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1)- 自行制作dataLoader: dataloader 为输入dataset可以随机获取dataset中batch size 个样本
通过使用打乱的indices,每次yield batch size个样本,生成的生成器可以用for调用
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # random read 10 samples
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)])
# the last time may be not enough for a whole batch
yield features.index_select(0, j), labels.index_select(0, j)- 参数初始化:自行初始化网络中的参数,使用init模块
from torch.nn import init
init.normal_(net[0].weight, mean=0.0, std=0.01)
init.constant_(net[0].bias, val=0.0)重要的问题:
1.构建一个深度学习网络并训练需要哪些步骤?
深度学习网络的主要组成部分就是数据,网络和训练,因此可以根据这三部分展开为下面几个步骤:
0. 数据部分
- 生成数据集/找到现有数据集
- 根据数据集构建Dataset 并用之构建dataloader
- (可选)调用构建的Dataloader,得到数据并可视化,检查实现的正确性,并对数据有一定了解
1. 网络部分
- 定义模型,初始化模型参数
- 定义损失函数,如本节的MSE loss
- 定义优化函数,SGD,Adam... 及其参数:学习率,动量,weight_decay...
2. 训练部分
- 使用循环的方式,每个循环训练一遍所有数据
- 将数据输入网络,根据损失函数和网络输出建立损失
- 梯度清零,损失回传,优化器更新损失
- 记录损失,可视化结果,往复训练
2.什么时候该用parameter.data?
下面是课程中使用的优化器的代码,可以发现,参数的更新使用了param.data
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track根据我的理解,这是由于反向传播机制在需要更新的参数进行运算时会构建动态运算图,如果直接使用这个param进行更新,就会在动态图中计入这一部分,从而反向传播时也会将这一步运算的梯度加入。而我们实际希望的则是损失函数对参数进行求导,而不希望再此参数上“节外生枝”。因此,在网络前向传播和损失函数计算之外的参数运算,应当使用param.data进行更新
分类模型和softmax
定义:softmax是用于将向量输出统一为有概率性质的一个函数,基于其指数的性质,它可以拉大大数和小数之间的差距,并且越大的数,为了达到和较小的数的差距只需要更小的差距,有助于筛选出一组向量中的最大值,并使其和其他数更加明显区分。
性质: softmax函数的常数不变性,即 softmax(x)=softmax(x+c):对需要进行softmax变换的向量,同时减去一个较大的数不会对结果产生影响,推导如下:

优势:1. 通过softmax,输入向量每个元素的大小一目了然,不需要关心输出的具体数值,也不会存在输出相差较大时,不好比较的问题 2. 使用softmax的输出进行交叉熵函数的比较相当于统一了量纲,平衡了不同输出结果的重要程度
分类模型
定义:分类模型用于将输入的图片/信号进行分类,本单元讲到的分类模型是对输入进行一次线性变换,最后将分类结果利用softmax进行区分,示例如下图:

交叉熵函数:上节的回归问题,我们用到了MSE,因为我们希望线性模型的参数和真实的完全一致,但是在分类模型中,我们只希望真实类别对应的概率越大越好,其他概率的具体数值对损失并没有过多含义。因此,这里使用了交叉熵函数,通过将标签化为one-hot编码,使得损失函数只关注正确类别对应的概率大小,其函数表达和实例操作如下:

如果标签为one-hot编码且只有一个正确类别,那么最小化交叉熵损失就是最大化正确类别对应输出概率的log形式,从另一个角度来看,最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率
多层感知机
定义:多层感知机是采用多个神经网络层,并在其中添加了非线性单元,从而使得网络可以得到从输入到输出的非线性映射,从而将线性模型转化为非线性模型,在此基础上,增加网络的深度可以进一步增加网络的复杂度。
激活函数:
定义:拥有非线性部分的函数,即函数的导数并非处处一致,常见的激活函数有Relu,Leaky-relu,tanh,sigmoid等
实例:

重要的问题:
1. 不同的激活函数应当如何选择?
在考虑不同激活函数的区别和优势时,我们主要考虑激活函数对神经元输出的影响和神经元的数值更新的能力。(即神经元的存在以及学习能力)
神经元的存在问题:当一个神经元更新到无论什么参数输入,其输出均为零时,其就失活了。这个主要是因为某些激活函数的截断作用,当大量神经元失活,网络的复杂度就会受到严重影响
神经元参数的更新:其取决于反向传播到该神经元的梯度值,这个梯度值是累乘的,其会乘上激活函数的梯度。因此,如果激活函数的梯度过小,那么就会导致这个神经元学习缓慢/无法学习
-
Relu:由于其计算效率和不容易梯度消失,从而大多数情况下使用;但是,由于其输出范围不确定,因此只能在隐藏层中使用;同时Relu函数因为在小于0的部分为0,因此容易在学习率大时使神经元失活
-
Sigmoid函数:用于分类器时,通常效果更好,但是存在由于梯度消失。
-
Tanh 函数: 和sigmoid 相似,但是其导数输出在(0,1),相比sigmoid更容易激活神经元;也存在梯度消失的问题
模型选择(过拟合欠拟合的出现和解决)
我们在训练深度学习模型时,期望使用训练数据训练的这个模型能在测试数据上也能得到很好的表现,这个就是期望泛化误差减小。(泛化误差: 模型在任意测试数据上的输出结果和真实结果的差距的期望,通常使用测试集上的误差来代表)
为了得到这样一个模型,其中的主要影响因素是模型复杂度,输入数据量,训练时间,训练方法等。但是由于我们没有确切的方式定义这些因素是如何影响的,因此,我们需要各种各样的方法来选择模型。
模型选择的方法
选择模型时,我们主要参考两个指标。一个是训练误差,一个是验证误差,这里不能使用泛化误差是因为这样会导致泛化误差有偏,不能反映真实的泛化误差。 训练误差和验证误差分别是模型在训练数据集和验证数据集上的误差,这个误差可以用交叉熵损失函数,MSE损失函数等多种损失函数计算得出
- 验证数据集进行验证: 验证集通过在整体数据中抽出一定比例数据组成,其不参与模型的训练过程,在模型使用训练数据训练完成后,我们通过其在验证集上的精度进行模型的选择。
- k折验证法:
有时,我们的数据不是非常充足,因此为了减少验证集对数据的浪费,我们采用K折验证法:
- 我们将整个数据分成k份,其中(K-1)份代表训练集,1份代表验证集,同时我们要遍历所有的组合方式,也就生成K份不同的数据集
- 模型分别基于K份数据集中的训练集进行训练,对应的验证集进行验证,获得的验证精度进行平均即获得这个模型的精度。
训练模型的过拟合和欠拟合
训练出来的模型一般存在两类问题,导致最终的验证结果不是最理想,因此我们需要尽量避免。

欠拟合:训练误差无法达到较小,说明此时在训练数据上模型都不能正确拟合。 过拟合:当训练误差已经较小,但是验证误差和训练误差相差较大,说明模型仅仅拟合到训练数据,该模型并不能泛化。
影响欠拟合和过拟合的因素: 影响模型有没有拟合/过拟合的因素是多方面的,包括模型模型复杂度,数据量,训练时间,训练方法等。
- 模型复杂度:模型复杂度可以受到参数量,网络的广度深度的影响,其最终等效为这个模型能描述的所有的函数的集合。一个过大的模型在一定时间的训练下很容易过度拟合
- 数据量: 数据量不仅仅是数据的多少,其还应该具有足够代表性和多样化。
- 训练时间&训练方法:合适的训练方法和恰当的训练时间可以避免模型过拟合/欠拟合
过拟合和欠拟合的解决方法
为了解决过拟合/欠拟合,我们需要对模型的复杂度进行限制/增加更多的数据,下面提出两种解决过拟合的方法
-
权重衰减和正则化: 在使用SGD优化方法时,正则化和权重衰减具有一致性。其中L2正则化是在模型的损失上添加一个权重的二范数作为惩罚项,从而限制参数的大小。 具体表达式以线性回归模型的损失函数为例:
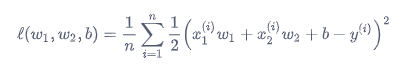
正则项则是参数的二范数:
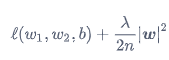
最终,根据SGD的参数更新方式,我们可以得到如下更新公式:
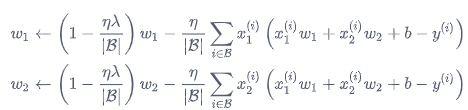
可以发现,添加了L2正则项的损失函数促使更新公式在权重项之前乘以了一个小于1的系数,也就是等效于权重衰减设置为lr*lambda
-
inverted dropout 丢弃法:
dropout的**是在前向传播的时候,设置一概率p,使得每个神经元有p的概率输出为0,很明显,这样的方式可以达到网络稀疏化的效果,从而削弱了网络的表达能力,即复杂度。从而是一种有效的防止过拟合的方式,下面我们看看其具体是怎么运行的:
-
在前向传播的时候,设置一个存在权重n,其有p的概率为0,1-p的概率为1,从而一个神经元输出为:
这里我们发现其输出的期望还是等于自身:
也就是增加了dropout的网络的输出平均值与没有增加dropout一致,而我们又知道dropout每次代表不同的网络结构,因此对增加了dropout的网络输出求平均即为对不同网络结构求平均,这样我们实现了一个网络结构和一次训练,但是求出的平均值等效于同时训练多个网络得到的平均值。这一种方法也有效地减少了过拟合。
-
在训练过程中我们不断使用不同的数据重复上述步骤
-
我们在测试是去除缩放因子,并对网络进行测试,由于第一步我们知道添加dropout与否的网络的平均值相同,那么我们在测试时去除缩放因子就保证了和训练的平均值相同。即我们测试了我们训练的网络。
那么dropout在网络结构层次上又是怎么影响的呢? 其作者认为,在训练神经网络时,过拟合现象起源于神经元之间的co-adpatation 相互适应,也就是某个神经元在给定某些固定特征时,其强行根据一些不正确的特征组合出最终的正确答案,因此dropout就打破了特征和输出的固定联系,从而促使网络根据一个更加general的场景做决定。
-



数值稳定性与模型初始化
通常我们希望我们的模型在训练过程中能快速地学习并在学习之后收敛到一个较好的结果。因此网络的数值稳定性就格外重要,我们希望网络中的神经元能每次更新适当大小的梯度作为优化方向。而梯度消失和梯度爆炸则会导致上述训练停滞或不能收敛。
深度模型有关数值稳定性的典型问题是衰减和爆炸。当神经网络的层数较多时,模型的数值稳定性容易变差。
梯度消失:其指的是传递到很多神经元的梯度几乎为0,从而导致网络的学习停滞
梯度爆炸:对应于梯度消失,梯度爆炸则代表神经元的梯度过大,使得其一下更新到一个不合适的位置,从而网络不能收敛
导致梯度消失和梯度爆炸的原因:
- 神经网络没有很好地初始化:当我们假设神经网络没有激活层时,传递到某一个神经元的梯度就是其后方连接上所有神经元参数的连乘积。那么,在较深的网络中如果我们将神经元均初始化较大(>1)的数值会导致梯度爆炸,较小(<1)则会导致梯度消失 那么有激活函数的场景怎么样呢,有激活函数时,不同的损失函数的情况有所不同,对于Sigmoid激活函数,当参数初始化较小的值,神经元的输入会较小,此时激活函数对应的梯度也较小,由此影响到神经元的梯度也较小,从而造成了梯度消失。
- 没有选择恰当的激活函数:如第一点所述,不同的激活函数会对梯度消失和梯度爆炸产生影响,因此需要根据数据选择合理的激活函数
- 输入没有合理地归一化:影响激活函数梯度的除了其自身之外,还有其输入,即便神经元初始正常,没有归一化的输入也会导致神经元输出过大/小,从而激活函数梯度过小
神经元初始化的方法
根据上述阐述,我们知道神经元的权重应当初始化到一个1附近的数值/0附近(对于Sigmoid等激活函数来说),因此有各种各样的初始化方法,在pytorch里面可以通过torch.init调用 Xavier初始化:将权重参数初始化到:

根据均匀分布的均值和方差公式,我们可以知道其初始化后,均值为0,方差为2/(a+b)
卷积神经网络
上面我们介绍的线性回归和多层感知机等均为全连接网络,但是全连接网络的两个缺点却对图片一类的数据很不友好:
- 参数量过大: 全连接层在处理输入(h1,w1,c1)输出(h2,w2,c2)时, 需要的参数量为h1*w1*c1*h2*w2*c2, 对于200*200*3大小的图片,单层的参数量就达到了14400000000。
- 没有办法识别空间局部特征,图片往往有空间相对信息,因此上下左右相邻的像素组合比展平的元素更有意义,同时缩放,平移,旋转不会改变这个区域的特征,但是全连接层则需要单独检测。
为了解决上述问题,同时基于生物感受野的**,卷积神经网络横空出世。 在卷积神经网络中,影响输出元素 x 的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做 x 的感受野(receptive field)
通过局部连接,权重共享,汇聚的结构,卷积神经网络解决了上述两个问题并不断发展,下面我们来讲述一下卷积神经网络的组成和技术细节。
卷积神经网络组成
卷积神经网络主要有卷积层,池化层,归一化层,全连接层组成。
卷积层
首先卷积层中最重要的就是卷积,但是实际上卷积层是做的互相关运算,而不是卷积运算。基于二者是旋转180度的关系,同时卷积层的参数是可学习的,因此我们可以直接使用互相关运算等效替代卷积运算并减少计算量。
卷积运算公式:


在对图像做完卷积之后,我们还需要增加一个偏置b到最后的运算结果上,从而和之前的全连接层保持一致,记录与特征无关的平移,如下所示:


卷积中的可选操作
在卷积层中除了进行卷积的操作,还可以进行一些其他的操作保证更好地利用原图/特征图上的信息。
- padding:为了保证原图/特征图的边缘也能多次参与和卷积核的运算并保证输入输出大小的不变性,人们采取将周边铺上0元素的方法,我们记单边增加了p列0元素。
- 步长:是指卷积核在滑动时的时间间隔。有时图片的尺寸较大,而我们为了减少计算量,并尽可能多覆盖相同多的特征,就会采用带步长的卷积,我们记步长为s
- 输入输出尺寸对应:设输入单边长度为lin,那么对应的输出单边长度为lout,而卷积核的单边长度为k

除此之外,还有空洞卷积,可变形卷积等其他卷积的变种可以用来进行卷积的操作。
Pooling层
汇聚层的作用是进行特征选择,降低特征数量,从而减少参数数量,同时可以对一些小的局部形态改变保持不变性,并拥有更大的感受野。但是过大的汇聚层会造成信息的损失。
汇聚层的反向传播:和卷积层的反向传播不同,汇聚层的输入和输出不一致,因此,我们反向传播时需要考虑怎样将误差值从输出传播到输入。
如果下采样是最大汇聚,误差项 𝛿(𝑙+1,𝑝) 中每个值会直接传递到上一层对应区域中的最大值所对应的神经元,该区域中其他神经元的误差项都设为0.如果下采样是平均汇聚,误差项𝛿(𝑙+1,𝑝) 中每个值会被平均分配到上一层对应区域中的所有神经元上

卷积神经网络的整体结构
通过组合卷积层,汇聚层,全连接层,卷积层用来识别图像里的空间模式,之后池化层用来降低卷积层对位置的敏感性,最后全连接层对物体进行分类。我们就可以获得以下一般的卷积神经网络结构:

不过网络结构并不是一成不变的,而是根据需要不断去修改其中卷积的操作,层级的安排等等。我们现在已经越来越少见到卷积神经网络中的全连接层了,汇聚层的比例也在不断减少。
经典的卷积神经网络
通过学习一些经典的神经网络,我们可以学习到其中设计网络的**
Lenet
Lenet的网络结构也遵循了我们之前提到的(卷积+激活+池化)*N+全连接的公式。
- 卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用 5×5 的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
- 全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。

Alexnet
相较于Lenet,Alexnet是一个更加现代的卷积神经网络,其使用更深的网络来提升网络的参数/表征空间,并用一些技巧来控制模型的复杂度。主要有以下特征:
- 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
- 将sigmoid激活函数改成了更加简单的ReLU激活函数。
- 用Dropout来控制全连接层的模型复杂度。
- 引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。

除此之外,Alexnet还使用全卷积的方式来减少显存的占用,以往,我们每生成一张输出特征图就需要使用和输入相同channels的卷积核进行卷积,在群卷积中,每次只需要使用输入channels/K的卷积核进行运算,并把最后结果concate起来,就能获得和原来相同大小的输出。 群卷积有助于减小参数的数量,但是其限制了每个卷积核对于通道的访问,从而限制了特征的组合。下图阐述了群卷积的运行:

VGG
使用多个重复的模块进行叠加的网络结构。
- Block:数个相同的填充为1、窗口形状为 3×3 的卷积层,接上一个步幅为2、窗口形状为 2×2 的最大池化层。
- 卷积层保持输入的高和宽不变,而池化层则对其减半。

网络中的网络
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。

1×1卷积核作用
1.放缩通道数:通过控制卷积核的数量达到通道数的放缩。
2.增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
3.计算参数少