![]()
Table of Contents
1946年にアメリカで開発された世界初のコンピュータ。 17,468本もの真空管を使った巨大な電子計算機。
設計したのはペンシルベニア大学のジョン・モークリーとジョン・プレスパー・エッカート マーヴィン・ミンスキー、ジョン・マッカーシー、アレン・ニューウェル、ハーバート・サイモンなど、後に人工知能の研究で重要な役割を果たす著名な研究者たちも参加した。
1956年7月から8月にかけて開催されたジョン・マッカーシーが主催した会議。 史上初めて「人工知能(Artificial Intelligence)」という用語が使われた。
1955年から1956年にかけてアレン・ニューウェル、ハーバート・サイモン、J・C・ショーが開発した世界初の人工知能プログラム。 コンピュータを使って数学の定理が自動的に証明することが実現可能であることを示した。
コンピュータによる知的な情報処理システムを設計、または実現するための研究分野。研究者によって定義は異なる。
人工知能を実現するための手法のうち特に、人間の学習能力、予測能力をコンピュータで実現しようとする技法や手法の総称
ディープニューラルネットワークを用いて学習を行う、機械学習のアルゴリズムの1つ。
特定のタスクでのみ成果を出せる人工知能。弱い人工知能。現在の技術ではこちらしか実現できていない。
人間と同等の知能を持もった人工知能。強い人工知能。
「人工知能搭載X」のような家電など
チェスプログラム、将棋マシーン
人間の知能を目指そうとするもの
表現学習、深層学習
人工知能で何か新しいことを実現したときに、その原理がわかってしまうと、「それは単純な自動化であって知能とは関係ない」と結論づける人間の心理的効果
人間は、相手が高度な知能を持った存在ではなくとも、自分に適切に反応してくれれば、本物の人間と対話しているように錯覚する傾向があること
冷戦下のアメリカで、自然言語処理による機械翻訳の研究に注力されていたことが有名。しかし当時は、実用的な機械翻訳を行うことはきわめて困難であると結論された。
チューリングテスト(1950)
ある機械が人工知能かどうか判定するためのテスト。「機械が知能をもっているか」という問いから、「機械が知能をもっている存在として人間が認知できるか」という問題に置き換えている。
人工知能として最も人間に近いと判定された会話ボットに対して毎年授与される賞。
競技の形式は標準的なチューリングテスト。
自分がもつ知識と知識を組み合わせることで新しい知識を見つけ出す
推論により導き出せる結果を、いかに早くおこなえるかを求めた手法。問題をうまく表現することができれば、効率的に解を見つけ出すことができる
環境・状態・行動をコード化できるとそのタスクは人工知能で解くことができる。推論・探索ではこの3要素を機械が理解できる形に書けないと解くことができない。
迷路やオセロなど、機械にときやすい簡単な問題
1966年に発表された自然言語処理プログラム。人工無脳の起源となった。
1972年に開発された ELIZA と共に有名な初期の会話ボット。ELIZA との最初の会話記録は RFC439 に残されている。
隣接するノードを優先して探索するアルゴリズム
目的のノードが見つかるか子のないノードに行き着くまで、深く探索するアルゴリズム
想定される最大の損害が最小になるように決断を行う戦略
シミュレーションや数値計算を乱数を用いて行う手法の総称。ランダム法とも呼ばれる。
エキスパートシステムにより問題を解く人工知能が台頭。しかし専門家の知識の定式化は難しく(知識獲得のボトルネック)、複雑な問題が解けるようにならなかった。
専門家の知識をそのまま人工知能に移植する事により、さまざまな問題を解決するアイディア
人工知能(AI)を応用したシステム構築を専門とする技術者
1970年代初めに開発された抗生物質を処方するAI
1960年代のエドワード・ファイゲンバウムが開発した未知の有機化合物の特定するエキスパートシステム
if-then 文よって記述できる知識の集まり
知識ベースを用いて推論を行うプログラム
通商産業省(現経済産業省)が1982年に立ち上げた国家プロジェクト。
第五世代コンピュータ・プロジェクト最終評価報告書(平成5年3月30日 電子計算機基礎技術開発推進委員会)
会話ボットやチャットボットなど、主にテキストを用いた会話をシミュレートするコンピュータプログラム
もともと認知心理学における長期記憶の構造モデルとして考案されたもの。 現在は、人工知能においても重要な知識表現の一つ。
「概念」をラベルの付いたノードで表し、概念間の関係をラベルの付いたリンク(矢印)で結んだネットワークで表す。
- is-a 関係
上位概念と下位概念の関係を表す。継承関係(ex. 動物は生物である。哺乳類は動物である。)
- part-of 関係
全体と部分の関係を表す。属性(ex. 目は頭部の一部である。肉球は足の一部である。)
1984年にスタートした、すべての一般常識をコンピュータに取り込むプロジェクト
AI におけるオントロジーとは「概念化の明示的な仕様」(Tom Gruber)であり、共通の概念の体系(語彙とその定義)とそれらの関係のことを指す。
本体は哲学用語で「存在論」という意味だが、人工知能の用語としては、トム・グルーバーによる「概念の明示的な仕様」という定義が広く受け入れられている。
対象世界の知識をどのように記述すべきかを哲学的にしっかり考えて行うもの。
哲学的な考察が必要になるため、人間が関わる傾向が強く、時間とコストがかかる(ex. Cycプロジェクト)
効率を重視し、とにかくコンピュータにデータを読み込ませてできる限り自動的に行うもの。
完全に正しいものでなくても使えるものであればいいという考えから、その構成要素の分類関係の正当性については深く考察は行わない傾向にある。 コンピュータで概念間の関係性を自動でみつける取り組みがある。(ex. ウェブマイニング、データマイニング、ワトソン)
IBM が開発した質問応答システム。
2011年にアメリカのクイズ番組で歴代の人間チャンピオンに勝利した。 ウィキペディアの情報をもとにライトウェイト・オントロジーを生成して、それを解答につかっている。
IBMが開発したチェス専用のスーパーコンピュータ。
1996年、チェスの世界チャンピオンであるガルリ・カスパロフに勝利した。
データをよく表す特徴を数値で示したもの(ex. 「人間」を表す特徴量としては、身長、体重、年齢、性別など)
モデルが認識しやすいような「特徴」をデータから新しく作ること。
たった1つの成分だけが 1、残りの成分が 0 という特徴量(ベクトル)に変換する。この形のことを one-hot-encoding と呼ぶ。
ディープラーニングにより自動的に獲得された特徴量
顧客の購買行動の促進のために、機械学習によってその顧客が好みそうな商品を推定し推薦するシステム。
ユーザーの購買履歴をともにおすすめを提示
アイテムの特徴をもとにおすすめを提示
人工知能 > 機械学習 > ニューラルネットワーク > ディープラーニング
子供のできることほど人工知能には難しい
2010年から始まった ImageNet データセットを用いた画像認識の競技会。
2012年、トロント大学のジェフリー・ヒントン教授のチームが AlexNet と呼ばれる畳み込みニューラルネットワーク(CNN)で2位以下を10%上回る正答率を出す。これがきっかけとなり、ディーブラーニングが脚光を浴びる。
ImageNet は、画像に写っている物体名(クラス名)を付与したデータベース。
ディープラーニングが脚光を浴びるきっかけになった年。
結果: http://image-net.org/challenges/LSVRC/2012/results
畳み込み層とプーリング層を深くしていく構造
層を深くしていくと計算量が非常に大きくなって学習が進まなくなるおちう問題があったが、小さなサイズの畳み込みフィルター(1x1, 3x3)を差し込んで次元(計算量)を削減するという工夫が取られるようになった。
結果: http://image-net.org/challenges/LSVRC/2014/results
2014年のコンペで1位になったアーキテクチャ。
このアーキテクチャは通常の入力層から出力層まで縦一直線な構造ではなく、インセプション構造と呼ばれる横にも層が広がる構成にすることで、並列計算を行いやすくしている。このため、Inceptionモデルとも呼ばれる。
ref: https://arxiv.org/pdf/1409.4842.pdf
2014年のILSVRCで2位になった、オックスフォード大学のVGGチームのネットワーク
結果: http://image-net.org/challenges/LSVRC/2015/results
2015年のILSVRCで優勝したネットワーク。
それまでのネットワークでは層を深くしすぎると性能が落ちるという問題があったが、それを「スキップ構造」によって解決し、152層もの深さ(前年優勝のGoogLeNetでも22層)を実現した。
以下のような理由で学習がうまくいっている。
- 層が深くなっても、層を飛び越える部分は伝播しやすくなる
- 様々な形のネットワークのアンサンブル学習になっている
ref: https://arxiv.org/pdf/1512.03385v1.pdf
レイ・カーツワイル が提唱した、人工知能が人間を超えて文明の主役に取って代わる時点。
カーツワイルは自著「The Singularity Is Near」で「シンギュラリティは2045年に到来する」と述べた。
-
スティーブン・ホーキング
「完全な人工知能を開発できたら、それは人類の終焉を意味するかもしれない」
-
イーロン・マスク
「人工知能はかなり慎重に取り組む必要がある。結果的に悪魔を呼び出すことになるからだ。ペンラグラムと聖水を手にした少年が悪魔に立ち向かう話を皆さんもご存知だろう。少年は必ず悪魔を支配できると思っているが、結局はできはしないのだ」
-
ビル・ゲイツ
「私も人工知能に懸念を抱く側にいる1人だ」
-
オレン・エツィオーニ
シンギュラリティの到来を馬鹿げていると評価した
-
ヴァーナー・ヴィンジ
シンギュラリティは「機械が人間の役に立つふりをしなくなること」と定義した
-
ヒューゴ・デ・ガリス
「シンギュラリティは21世紀の後半に到来し、そのとき人工知能は人間の知能の1兆の1兆倍になる」
まとめ: https://qiita.com/Hiroki1928/items/6d66bf66f44df55a2f4e
ある問題を解決する際に、その問題に関連する、考慮すべき事柄を抽出することが AI には難しいこと
フレーム問題を打破し、人間のようにあらゆる問題に適切に対処できるようになった AI。
哲学者のジョン・サールが1980年に発表した論文の中で提示した区分。
フレーム問題に縛られたままの AI
記号システム内のシンボルがどのようにして実世界の意味と結び付けられるかという問題
機械学習において、正しい特徴量を見つけるのは一般に非常に難しいタスク。 人間が特徴量を見つけるのが難しいのであれば、特徴量を機械学習自身に発見させれば良い。 このアプローチは「特徴表現学習」と呼ばれ、ディープラーニングはこの「特徴表現学習」を行う機械学習アルゴリズムの一つ。
しかし、コンピュータが自動的に特徴量を抽出するため、特徴量が意味することを本当の意味で理解することはできない。(ブラックボックス)
世の中の特定の事象についてデータを解析し、その結果から学習し、判断や予測を行うためのアルゴリズムを使用する手法
機械学習はデータが命。データから答えを探し、データからパターンを見つけ、データからストーリーを語る。 機械学習の中心には「データ」があり、このデータ駆動によるアプローチは、「人」を中心とするアプローチからの脱却とも言える。 重みパラメータの値をデータから自動で計算できる。(ディープラーニング)
機械学習の処理は大きく「学習」と「推論」ステップに分かれる。
事前に与えられたデータからモデルをつくること。 学習が終わったモデルには、学習データの統計的な傾向や規則性が反映されている。
実環境で得られるデータなどを使い、学習済みモデルを使って判定、分類、予測などを行う。
機械学習の予測モデルに入力する情報。
例えば明日の積雪の有無を予測するために、今日の気温(1.0℃)、降水量(0.8mm)、天気(曇り)使うとすると、それぞれを数値化したもののリスト(ex. [1, 0.8, 1]) が「特徴ベクトル」になります。
ここで、「曇り」のような特徴量を「カテゴリカル変数」と呼び、晴れは 0、曇は 1 というような数値データのことを「ダミー変数」と呼ぶ。

機械学習とは?これだけは知っておきたい3つのこと - MATLAB & Simulink
| アルゴリズム | 回帰 | 分類 | クラスタリング |
|---|---|---|---|
| 線形回帰 | o | x | x |
| ロジスティック回帰 | x | o | x |
| サポートベクターマシン | o | o | x |
| ナイーブベイズ | x | o | x |
| 決定木 | o | o | x |
| ランダムフォレスト | o | o | x |
| ニューラルネットワーク | o | o | x |
| kNN | o | o | x |
| k-means | x | x | o |

Choosing the right estimator — scikit-learn 0.23.1 documentation
教師データ(入力とそれに対応する正解ラベルの組)を使って予測値を正解ラベルに近づけることを目標に学習する手法 自然言語処理、スパムメールフィルタリング、手書き文字認識などの応用がある。
教師データを使わずに、データの本質的な構造を浮かび上がらせる手法。 クラスタリングやデータ次元圧縮技術などがこれに含まれる。
ゴールや目標を仮定せず、学習を行う「エージェント」が状態を観察し、環境からの報酬を最大化するように試行錯誤しながら行動を選択することで学習を行う。 ロボット操作などに使われることが多い。
すでにある領域で学習済みのモデルを他の領域に流用する手法。
教師あり学習におけるラベル付けコストを低減するために用いられる手法。 データの一部分にのみ正解ラベルをつける。
正解となる数値を入力データの組み合わせで学習し、未知のデータから連続値を予測する。
統計学において、目的変数と説明変数の関係を明らかにすることで、未知のデータ属性の値を既知のデータ属性から予測できる。 (ex. 家賃の高さを広さ、築年数、駅からの近さの値から計算)
入力データが1つの単回帰分析、複数の入力データの重回帰分析などの種類がある。
正解となる離散的なカテゴリ(クラス)と入力データの組み合わせ出学h数詞、未知のデータからクラスを予測する。
あらかじめ設定したクラスにデータを割り振る(ex. 画像に写っている犬や猫の識別)。 サポートベクターマシン、決定木、ランダムフォレスト、ロジスティック回帰、kNN法などの手法がある。深層学習でも分類を行うことができる。
データを何かしらの基準でグルーピングする。 分類と違い、事前にクラスなどの分類の軸が提供されないため、与えられたデータの特徴などから自動的にクラスタを構成する。
事前学習が不要なため、過去のデータがない場合でもクラスタ化可能だが、クラスに基づく分類とは異なる結果がでる場合がある。 代表的なアルゴリズムに k-means法などがある。
高次元のデータを可視化や計算量削減などのために低次元にマッピングする。
データをモデルに正しく入力できるようにする。 データの大きさをある程度均一にする。
連続した値をある区分にわけること。
値の log(対数)を取る(log に変換する)こと。
正の値をもつ数値データにおいて、長い裾を短く圧縮し、小さい値を拡大することができる。 機械学習では正規分布に近いデータが効果を発揮しやすいため、対数変換は有効な手段の一つ。
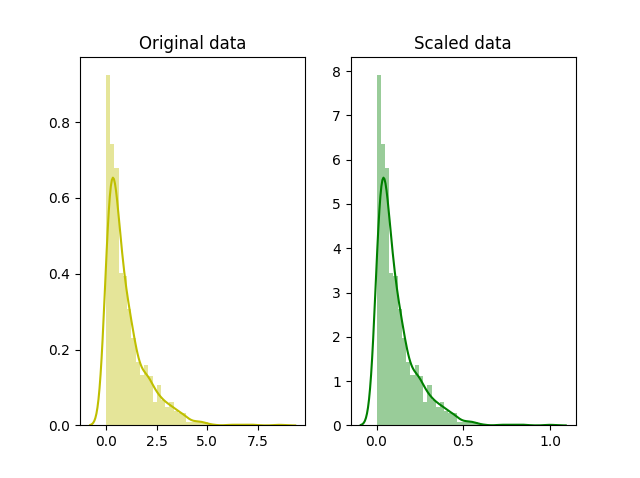
https://kharshit.github.io/blog/2018/03/23/scaling-vs-normalization
データを 0 から 1 に収まるようにスケーリングすること。
代表的なスケーリングの方法に「Min-Maxスケーリング」と「標準化」がある。
-
Min-Maxスケーリング
最小値を 0、最大値を 1 にし、データの範囲を 0 ~ 1 に変換する。
-
標準化
平均を 0、標準偏差(分散)を 1 に変換する。 対数変換をしてから標準化を行う場合もある。
各特徴量を無相関化した上で標準化する手法。 白色化は計算コストが高いので、標準化を用いるのが一般的。
データの傾向を事前に把握する。散布図行列をプロットして傾向を調べる。相関行列を表示し傾向を調べる。
線形回帰式で利用可能な手法。
学習に用いる式に項を追加することによってとりうる重みの値の範囲を制限し、過度に重みが訓練データに対してのみ調整されることを防ぐ。
(回帰)係数を大きくなりすぎないように自動で調整することで、予測結果を安定化させる。
誤差関数にパラメータのノルムによる正則化(LASSOなど)を付け加える。
一部のパラメータの値をゼロにすることで、特徴選択を行うことができる。
線形回帰に対してL1正則化を適応した手法を「ラッソ回帰」という。 ラッソ回帰は、自動的に「特徴量の選択」が行われる性質を持つ。
パラメータの大きさに応じてゼロに近づけることで、汎化されたなめらかなモデルを得ることができる。
線形回帰に対してL2正則化を適応した手法を「リッジ回帰」という。 リッジ回帰は、特徴量選択は行わないが、パタメータのノルムを小さく抑える。
ラッソ回帰とリッジ回帰の両者を組み合わせた手法。
入力ベクトルと学習した重みベクトルを掛け合わせた値を足して、その値が0以上のときはクラス1, 0未満のときはクラス2と分類するという、シンプルなアルゴリズム。
過学習しやすく、線形分離可能な問題のみ解ける。
簡単にいうと「データにもっともフィットする線を引くこと」
1つの説明変数(手がかりとなる変数)から目的変数を予測する。 データと回帰直線との最小二乗法が誤差関数(損失関数)。
※ 説明変数は文脈にとっては特徴量と呼ばれることがある。特徴量の方が少し大きな概念になるが、同じものを指していると考えていい。
複数の説明変数から目的変数を予測する。 多重共線性に注意する必要がある。
相関係数が高い特徴量の組を同時に説明変数に選ぶと、予測がうまくいかなくなる現象。
多重共線性を避けるには、相関の強い説明変数のどちらか一方を除く。 特徴量エンジニアリングにおいては、多重共線性がでないような特徴量を選ぶ必要がある。
特徴量同士の相関の正負と強さを表す指標。-1 <= x <= 1。 1に近いほど強い正の相関、-1に近いほど強い負の相関をもつ。0のときは相関がない。
パーセプトロンを使って解ける問題。2次元のグラフ上で直線を使って分離できる。 論理ゲートでは OR, AND, NAND は線形分離可能だが、XOR のみ線形分離不可能。
データを最も引き離す境界線を引くための手法で、ディープラーニングを使わない機械学習の中では主流の方法。
「マージン最大化」というコンセプトで2つのクラスを線形分離可能にするアルゴリズム。
もともとは2つのクラス分類アルゴリズムとして考案されたが、性能がいいので多クラス分類や回帰分析にも応用されている。
線形分離可能でないデータに対しても、カーネル法を組み合わせることで決定境界を求めることができる。 未学習のデータに対しても高い識別性能があるが、仮説の設定や特徴の選択が必要。
超平面を構成した結果として発生する誤差の程度を測る変数。
推論や予測の枠組みの中で決定されないパラメータ。 SVM においては誤りをどの程度許容するかの度合いをエンジニアが事前に調整する必要がある。
適切だと考えられるパラメータを複数用意し、それらの値の組み合わせを全通り総当たりで行い、最も良いハイパーパラメータを探す方法。
考えられるパラメータの範囲を決め、ランダムにパラメータを組み合わせて学習させ、最も良いハイパーパラメータを探す方法。
過去の試行結果から次に行う範囲を確率分布を用いて計算する手法。
ハイパーパラメータを含め最適化問題とする方法で、近年、効率的なチューニング方法として注目されている。
派閥の境界が非線形になっている場合に用いる手法。
データから新しい特徴量をつくって、線形分離可能になるようにプロットしなおす。
次のアイディアをカーネル関数の計算によって実現するもの。
- データを高次元空間にうまく埋め込む
- 高次元空間で線形分離 (SVM) し、その境界を元の空間に戻す
カーネル関数を使って、計算複雑度の増大を抑えつつ内積にもとづく解析手法を高次元特徴空間へ拡張するアプローチ。 計算量を現実的に抑えつつ、非線形分離を実現する。
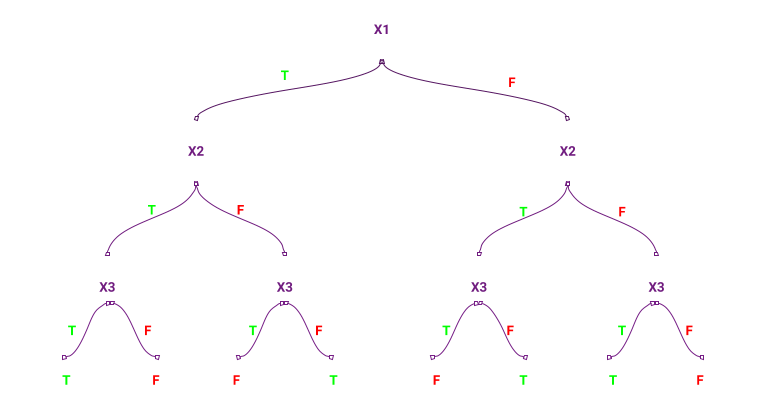
Yes or No で答えられる条件によって予測を行う手法。
人間の思考プロセスに近い方法のため、結果がわかりやすいのが特徴。
性質(ex. 男女)や数値(ex. 購入数5個以上/未満)に基づき、データを木構造に分類する手法。予測にも使える。
人が理解しやすく前処理が少なくてすむ(データのスケールを事前に揃えておく必要がない)が、データに対する条件分岐が複雑になりやすく、過学習を起こしやすい。
- 不純度が最も減少(情報利得が最も増加)するように、条件分岐を作りデータを振り分ける
- それを繰り返す
不純度とは「クラスの混じり具合」を表す指標で、代表的なものにジニ係数やエントロピーがある。
学習器を複数組み合わせて1つの学習モデルを生成する方法。
「三人集まれば文殊の知恵」を機械学習で実現する方法ともいえるかも。
複数の学習モデルを組み合わせて1つの学習モデルを生成する手法。
弱学習器を使って学習を行うため、学習スピードが早く、訓練や予測にかかる時間が少なくて済む。 最終的な予測結果は「多数決」「平均」「加重平均」といった方法で求める。
アンサンブル学習の手法は大きく分けて以下の2つの手法がある。
ブートストラップ法を使って、全データから訓練データを複数組生成し、訓練データ1組1組に対してモデルを用意して並列して学習を行う。 各モデルの結果平均をとって予測結果とする。
以下のフローで各モデルを逐次的に学習させる手法。
- 訓練データ1つ目のモデルに学習させ、予測結果と実際の値を比較する
- 次のモデルを学習する際に、間違えた部分を正解にできるように学習したデータを重視して学習する
ブースティングには以下のようなアルゴリズムがある。
勾配ブースティング法を使ったライブラリ。 確率的な最適化処理をしているため大規模なデータでも高速に処理できる。
ランダムに選んだ学習データを説明変数を用いて決定木群を作成し、その多数決や平均値を結果として出力する。
決定木にバギングを組み合わせていて、以下のような利点があり、非常によく使われている。
- データの前処理が少なくて済む
- 安定して良い精度が出る
- 過学習を起こしにくい
一方で、中身がブラックボックス化するという面もある。
前段階のモデルの予測結果を学習するため、データの偏り(バイアス)とデータの散らばり(バランス)を上手に調整できる。
- バギングと同じように、ブートストラップ法で得たデータを各モデルに学習させ、各モデルの予測結果を出す
- 上記予測結果を入力としてモデルを学習させる
- 以降も同様に前段階の予測結果を入力として学習する
サンプリングしたデータに対して直列的に浅い決定木を学習していく手法。 前モデルの誤差を取ることによって、新しいモデルが古いモデルの欠点を穴埋めをする。
- 決定木を用いて1回目の予測を行う
- 訓練セットの正解データと予測結果の差をとり、誤差を算出する
- この誤差を正解データとして、決定木を使って2回目の予測を行う
- 上記を繰り返す
「回帰」という言葉がついているが、主に分類に使われるアルゴリズム。
Yes / No の確率を計算するさまざまな場面で利用される。
AかBどちらかしか起こらない確率などに、事象がどちらかに分類できるかの確率を計算する。
線形回帰を分類問題に応用したアルゴリズム。(線形分離可能な対象を分離するアルゴリズム)
- 「対数オッズ」を重回帰分析により予測する
- 「対数オッズ」をロジスティック関数(シグモイド関数)で変換することで、クラスiに属する確率piを求める
- 各クラスに属する確率を計算し、最大確率を実現するクラスが、データの所属するクラスと予測する
また、「ロジット変換」を行うことで、出力値が 0 から 1 の間の値に正規化され、確率としての解釈が可能になる。
目的関数には「尤度関数」が用いられる。
ベイズ推定を用いて、不確実性を考慮した予測を行うことができる。
確率の初期状態(事前確率)に対して、得られたデータにより確率(事後確率)を計算(ベイズ更新)して推定を行う。 推定結果(値)がどれだけふさわしいかがわかる。
データを増やすことで精度を向上できるが、学習データで仮定した確率分布以外では未対応。
クラス分類のアルゴリズムの一種。
データから近い順に k 個のデータを見て、それらの多数決によって所属クラスを決定する。 kNN法は柔軟にモデルを作れるが、実用上、以下の条件がないと精度が上がらない弱点がある。
- 各クラスのデータ数に偏りがない
- 各クラスがよく別れている
代表的な手法は、クラスタリングと次元分析。
データ群をいくつかの集まり(クラスタ)に分けることで、データの本質的な構造を浮かび上がらせる手法。 クラスタはデータから自動的に導かれる。
エンジニアが予め設定した「クラス」にデータを適切に分類する(教師データを使う)
多次元のデータに対して正味に効果のあるより少ない成分を抽出(次元の削減)する手法。 データから「主成分」という新たなデータを求める、線形な次元削減の手法。
寄与率を調べることで各成分の重要度を測ることができる。
変数間に相関のないデータに対しては有効でない。
データの情報を失わないようにデータを低い次元に圧縮する手法の総称。(ex. 身長と体重から肥満度を表す BMI を計算する)
異なる性質のものが混ざり合った集団から、互いに似た性質を持つものを集め、クラスターを作る方法の1つ。
あらかじめいくつのクラスターに分けるかを決め、決めた数の塊(排他的部分集合)にサンプルを分割する。 手法が理解しやすく、大規模なデータにも適応可能。
機械学習において重要なことは、データを学習することで未知のデータの予測や分類を行えるようにする(汎化性能)こと。
学習が終わった段階では未知のデータに対する性能が保証されていないので、汎化性能を検証する必要がある。
区別がまぎらわしい少数のデータのラベルを作成して学習したほうが精度があがる。
学習に用いる分の教師データ。
「モデルの評価」で使うチューニング用データ。
このデータを使って、正解ラベルと一致するかをチェックすることで、「対象の機械学習モデルがどのくらいの精度が出せるのか」というパフォーマンス(性能)を評価・検証する。
未知データへの予測性能(汎化性能)を測るための教師データ。
学習済みのモデルが、訓練に対しては高い精度で正解ラベルを予測できる(訓練誤差が小さい)にもかかわらず、未知のデータに対しての予測精度が悪いままになってしまう現象。 機械学習における最大の問題?と呼ばれている。
未知のデータ(テストデータ)とモデルとの間に生じた誤差のこと。
出力データと正答データの間に生じた誤差。
ある層の入力がそれより下層の学習が進むにつれて変化してしまうことがある。これにより学習が止まってしまうこと。
大規模なニューラルネットワークの学習が困難となる原因の一つ。
これを防ぐために出力値の分布の偏りを抑制する「バッチ正規化」が使用される。
データを訓練データとテストデータにある割合で分割して、モデルが過学習を起こしていないか調べるための手法。
モデルを評価するためのデータ
-
テストデータ
やがて手に入るであろう、正解ラベルがあるとは限らないデータ。
-
検証データ
あらかじめ手元にあり、正解ラベルがあることが約束されているデータ。
テストデータに用いるブロックを順に移動しながらホールドアウト法による検証を行う。
計算量が多くなるなど欠点があるが、データ数が少ない場合にもホールドアウト法と比較して信頼できる精度が増えるなどの理由で、精度検証において最もよく用いられる。
回帰モデルの性能は基本的に、出力と正答の数値の差分である「予測誤差」によって評価できる。
回帰モデルの評価指標の違いは、予測誤差をどのように集計するかの違い。
予測誤差を正規化することで得られる指標。 まったく予測できていない場合を 0、すべて予測できている場合を 1 として大きいほど性能が良いことを示す。
予測誤差を二乗して平均したあとに集計する指標。 小さいほど性能が良いこと示す。 正規分布の誤差に対して正確な評価ができるため、多くのケースで使われている。
予測誤差の絶対値を平均したあとに集計する指標。 小さいほど性能が良いことを示す。 RMSE と比較して外れ値に強いため、多くの外れ値が存在するデータセットで評価する場合に利用される。
| 正解が「o」 | 正解が「x」 | |
|---|---|---|
| 「o」と予想 | TP | FP |
| 「x」と予想 | FN | TN |
(TP + TN) / (TP + TF + FN + TN)
全体のデータのうち正しく分類できたデータの数の割合。
TP / (TP + FN)
実際に正であるものの中で、正だと予測できたデータの割合。
出力した結果が実際の正解全体のうち、どのくらいの割合をカバーしていたかを表す指標。
「絶対にミスをしてはいけない」などのケースでは重視される指標。(ex. 医療検診)
TP / (TP + FP)
予測が正の中で、実際に正だったデータの割合。
適合率は精度とも呼ばれ、出力した結果がどの程度正解していたかを表す指標。
見逃しが多くてもより正確な予測をしたい場合は、適合率を重視する。 (重要なメールがスパムと誤判定されるよりは、たまにスパムがすり抜けても構わない)
「顧客の好みでない商品を提案したくない」などのケースでは重視される指標。(ex. WEBマーケティング)
(2 x Recall x Precision) / (Recall + Precision)
適合率と再現率の調和平均。 適合率のみあるいは再現率のみで判断すると、予測が偏っているときも値が高くなってしまうので、F値を用いることも多い。
適合率と再現率のバランスが見れる。機械学習モデルの評価の際に、正解率と並んで最も使われる指標。
横軸を再現率(Recall)、縦軸を適合率/精度(Precision)として、データをプロットしたグラフを表したもの。
PR曲線には適合率と再現率が一致する点があり、この点を「ブレークイーブンポイント(BEP)」と呼ぶ。 この点では、適合率と再現率の関係をバランスよく保ったまま、コストと利益を最適化できるので、ビジネスにおいては重要な点となる。BEPが右上に遷移するほど良いモデルが構築できたと言える。
一つの学習済みモデルで様々用途に対応できるわけではないこと数学的に証明した定理。
1969年に情報理論学者・理論物理学者の渡辺慧が提唱した定理。
対象がもつ特徴をすべて同等に評価すると識別が困難になること。 機械学習で行われる「特徴選択」や「次元削減」といった処理が人間の主観的な特徴選択と同様であり、識別にとって本質的であることも示している。
ディープニューラルネットワークを用いた機械学習の手法。 2010年代に脚光を浴びたが、アルゴリズム自体は1960年代にはすでに考案されていた。
ニューラルネットワークを3層より多層にしても学習精度が上がらない壁にぶつかったが、自己符号化器の研究などを足場にして、層を深くしても学習することが可能となった。
人工知能の大家マービン・ミンスキーによって、特定の条件下の単純パーセプトロンでは直線で分離できるような単純な問題しか解けないということが指摘されたが、バックプロパゲーション(誤差逆伝播法)で克服できることが示された。
「深い関数を使った最小二乗法」
「シグモイド関数など活性化関数を使って非線形性を入れ、多層に構成した関数を使った、損失関数の最小化」
パーセプトロン
パーセプトロンの性能と限界に関する論文 (冬の時代が始まる)
バックプロパゲーション(誤差逆伝播法) (第二次 AI ブーム)
自己符号化器 (第3次 AI プームのきかっけ)
ILSVRC でトロント大学の SuperVision が優勝
AlphaGo が人間のプロ囲碁棋士を破る
人間の神経回路(ニューロン)の構造をモデル化したネットワーク。
単純な数値予測ができ予測器。ニューラルネットワークの最小単位。 重みが乗算された入力を受け取り、それらを総和して出力する。
ニューロンをたくさんつなげててきる予測器。入力が行わる層を「入力層」、出力される層を「出力層」、それ以外の層を「中間層」または「隠れ層」と呼ぶ。
また、入力層の各ノードが隠れ層のすべてのノードと結合しているような層を「全結合層」と呼ぶ。 人間の脳を模倣したモデルではなく、「人間の脳の仕組みの一部」を模倣している。
1982年に福島邦彦氏によって発表された、畳み込みニューラルネットワークの発想の基となったネットワークモデル。
「ランダムに初期化された密なニューラルネットワークは、たまたまうまく学習ができるように初期化されたサブネットワークが含まれており、このサブネットは、学習が進むにつれて他のサブネットよりも優れているので早く学習が進み、他の劣るサブネットの活性が抑制される」という仮説。
この仮説を提唱した論文「The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks」は、2019年5月にはディープラーニングのカンファレンス ICLR 2019で Best Paper Award に選ばれた。
ニューラルネットワークの設定(ハイパーパラメータ)を変えることによる出力結果の変化を直感的に確かめることができるサイト。

ニューラルネットワークの出力と正答データとの差(誤差)が後ろ(逆)のノードへと伝播するように計算を行い、その重みを調整する手法。 損失関数が小さくなるように各ノードの重みを調整する。
出力と正答データの誤差の和
- 教師データを用いて予測計算をする。その際の予測値を正解ラベルと比較して誤差を計算する。
- 予測値は左から右へと順番に伝わる(順伝播)
- 上記をいくつかの教師データについて繰り返し、誤差を足し合わせる
- 累計された誤差が小さくなるように、勾配降下法を用いて各枝の重みを更新する。 枝の重みは右から左へと順番に更新される(誤差逆伝播法)
- 上記を繰り返す
1回の学習ですべてのデータを読み込んで学習する。 メモリの大きさが増加するが、すべてのデータを均等に扱える。 また、計算時間は長くなるので、モデルの更新に時間がかかる。
1回の学習で「バッチサイズ」として設定した数のデータを読み込んで学習する。 学習結果は最後に読み込んだデータに引っ張られるため、学習順序によって性能が変わるケースがある。
1回の学習で1つのデータを読み込んで学習する。 学習サイクルが速く、新しいデータが入るとすぐそのデータが学習されたモデルが手に入る。
ミニバッチ学習と同様に、学習結果は最後に読み込んだデータに引っ張られるため、学習順序によって性能が変わるケースがある。
機械学習では、対象領域の知識に基づいて適切に手法を選択する必要があるが、ディーブラーニングでは、表現力の高い「深い関数」を用いるため、データと計算量されあれば精度が上がる。
ディーブラーニングに適した学習データは、正規化されているものよりも、画像や音声そのもの、膨大なテキストなど。 どうやてデータを集めるか、どうやってアノテーション(ラベルやメダデータを与えて学習データを整備)するかが課題となる。
2006年に発表され、今日のディーブラーニング隆盛のきっかけともなった技術。 3層ニューラルネットにおいて、入力層と出力層に同じデータを用いて教師なし学習させたもの。
次元数を減らしたニューロン層を重ねていくことで特徴の圧縮を行うエンコーダと逆の構造を持つデコーダーを接続したもの。 砂時計型の構造をもつニューラルネットワークで、入力側から半分をエンコーダ、残り半分をデコーダーと呼ぶ。
入力層と出力層のノード数が等しく、中間層のノード数が入出力層よりが少ない。 入力情報と同じ出力情報を再現するこを目指す(「正解ラベル」として「入力自身」を用いる)。
オートエンコーダにおいて、隠れ層で特徴的な情報だけに次元を圧縮すること。
オートエンコーダを順番に学習させ、それを積み重ねる手法。
ディープニューラルネットワークのように一気にすべての層を学習するのではなく、入力層に近い層から順番に学習されるという、逐次的な方法をとった。(層ごとの貪欲法) 事前学習とファインチューニングの工程で構成される。
オートエンコーダを順番に学習していく手法。
最後にロジスティック回帰層(シグモイド関数あるいはソフトマックス関数による出力層)を足すことで、教師学習を実現する。
これにより、ネットワーク全体は隠れ層が複数あるディープニューラルネットワークになる。
事前学習を終え、ロジスティック回帰層を足したら、最後の仕上げとしてディープニューラルネットワーク全体で学習を行い重みを調整する。
入力信号の総和を出力信号に変換する関数。
出力層で使用する活性化関数は、回帰問題では恒等関数、分類問題ではソフトマックス関数を一般的に利用する。
パーセプトロンとニューラルネットワークの主な違いは、活性化関数。 パーセプトロンではステップ関数、ニューラルネットワークではシグモイド関数など非線形関数を用いる。

微分できないのでニューラルネットワークの学習で実際に使われることはない。

入力を 0 ~ 1の間に値に変換する性質を持つ関数。 ステップ関数と形が似ていて、なめらかなので微分できる関数として考案された。
最大勾配が 0.25 で勾配消失が起こりやすいため、通常は ReLU 関数などを使うのが主流。


正則化機能を持たいない活性化関数で、勾配消失問題が起きにくく、最近の主流。 入力が 0 を超えていればその入力をそのまま出力し、0 以下ならば 0 を出力する。
出力の総和を 1 に正規化して、確率として解釈する際に用いされる活性化関数。 分類問題の出力層付近で用いられることが一般的。

ニューラルネットワークの最適化は、損失関数の値が小さくなるような重みを探し出すこと。
モデルの最適化によく利用されるのが「勾配降下法」で、SGD(確率的勾配降下法)など様々な最適化アルゴリズムがある。 学習する際には「誤差逆伝播法」を用いるが、その際には「勾配消失問題」に注意する。
どのくらいの幅でパラメータを修正するかを決めるハイパーパラメータ。
学習率が大きい値だと速く収束するかもしれないが、谷を行き過ぎて最適な解に収束しない場合もある。 学習率が小さい場合は、収束するまでに必要な繰り返し回数が増えるため、学習時間が長くなる。
ニューラルネットワークでは、学習率を動的に変化させるさまざまな工夫が提案されている。
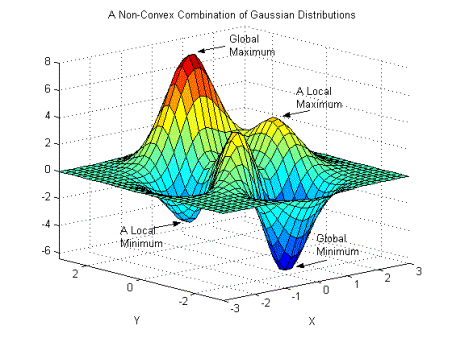
https://en.wikipedia.org/wiki/File:Non-Convex_Objective_Function.gif
重みを少しずつ更新して勾配が最小になる点を探索するアルゴリズム。
ディープニューラルネットワークの学習では、「局所最適解が求められればそれなりに誤差の値は小さくなるだろうから、それで妥協しよう」というスタンスに立つ。
-
局所最適解
園周辺では誤差の値は小さいが、最小値を実現するわけではない解 -
大局的最適解
誤差の値を最も小さくする解
-
停留点
局所最適解でも大局的最適解でもないが、勾配が 0 になる点
-
鞍点(あんてん)
停留点のうち、ある方向から見ると極小値だが、別の方向から見ると極大値になる点
1エポックとは、学習において訓練データをすべて使い切ったときの回数に対応する。 (訓練データを何度学習に用いたか)
重みを何度更新したか
ミニバッチに含まれるすべてのデータについて誤差の総和を計算し、その総和を小さくするように重みを1回更新する。
ミニバッチは、いくつかの訓練データからランダムにサンプリングした小さなデータの集まり。
訓練データすべての誤差を計算し、重みを1回更新する(イテレーションとエポックが等しい)。
大きいネットワークの入出力を小さいネットワークに再学習される手法。
誤差の勾配を逆伝播する過程において、勾配の値が消出し入力層付近での学習が進まなくなるディープニューラルネットワーク特有の現象。層が深いほど起こりやすい。
活性化関数が何度も作用することで、勾配が小さくなりすぎてしまうことが原因とされる。
1回のパラメータ更新でデータ全部を使っているため、一気にパラメータを更新できますが、計算量が大きくかつ最適解ではない極小値に陥ってしまった場合抜け出せない、という欠点がある。
まとめ記事。 https://postd.cc/optimizing-gradient-descent/
無作為に選びだしたデータ(ミニバッチ)に対して行う勾配降下法。
最急降下法の欠点を克服するために、ランダム性を含んだ最急降下法。
訓練データ1つに対して、重みを1回更新する(データ1つごとにイテレーションが増える) 関数の形状が等方向的でないと非効率な経路で探索することが欠点。
ボールが地面を転がるように、損失関数上での今までの動きを考慮することで SGD の振動を抑える手法。
勾配降下法の学習率に関する手法。 パラメータの要素ごとに適応的に学習係数を調整しながら学習を行う手法。
Adagradの発展形で、急速かつ単調な学習率の低下を防ぐ手段を探る手法。
AdaGrad は学習を進めれば進めるほど、更新度合いは小さくなり、無限に学習すると、更新量は 0 になる。この問題を改善した手法が、RMSPop。
過去のすべての勾配を均一に加算していくのではなく、過去の勾配を徐々に忘れて新しい勾配の情報が大きく反映されるように加算する手法。
2015年に提案された、直感的には、Momentum と AdaGrad を融合した手法。
先の2つの手法の利点を組み合わせることで、効率的にパラメータ空間を探索することが期待できる。 ハイパーパラメータの補正が行われていることも特徴。
重み更新の際(エポックごと)に一定の割合でランダムに枝を無効化する手法。単純だが効果が高い。 アンサンブル学習と近い関係にある。
訓練データにオーバーフィッティングする前に学習を早めに打ち切る手法。
誤差関数が「予測値と正解tの誤差」であり、訓練データをもちいて最小化するアプローチしか取れない以上、同区数しても(訓練データ)にオーバーフィッティングしてしまうのは避けられない。
ディープニューラルネットワークでは活性化関数がかかっているので、正規化したデータが層を伝播するにつれて分布が徐々に崩れてしまう。
そのため乱数にネットワークの大きさに合わせた係数をかけることで、データの分布が崩れにくい初期値がいくつか考えられた。
シグモイド関数に対しては Xavier の初期値、ReLU関数に対しては He の初期値が良いとされている。
各層において活性化関数をかける前に伝搬してきたデータを正規化する処理を加える。 無理やりデータを変形しているので、それをどのように調整すればいいのかをネットワークが学習する。
学習がうまく行きやすくなるという利点以外にも、オーバーフィッティング(過学習)しにくくなることも知られている。

特に画像認識に応答するために改良されたディープニューラルネットワーク。 自動運転技術など、非常に広く応用されている。
従来のシグモイド関数のような活性化関数では、層が深くなるにつれ勾配が小さくなってくのでうまく学習ができないので、勾配消失問題を解決した ReLU関数を用いる。
- 畳み込み層
フィルタを用いて積和演算 + 活性化関数の作用を行う層。 元の画像の特徴が抽出された小さな画像である「特徴マップ」に変換される。
出力画像のサイズを調整するために元の画像の周りを固定の値で埋める「パディング」を行う。
- プーリング層
畳み込み層から「特徴マップ」を受け取り、平均値、最大値を用いてサブサンプリングを行う層。 平均プーリング、最大プーリングによって更に小さな画像に変換される。
- 全結合層
プーリング層から出力された画像データを、縦横に並んだ2次元データから、一列に並べたフラットな1次元データに変換する出力層。
1998年にヤン・ルカンらによって提案された、手書き数字認識を行うネットワーク。
シグモイド関数を使用して、サンプリングによって中間データのサイズ縮小を行っている。 初めての CNN。
畳み込みフィルタと呼ばれる、画像中の特定の形状に反応するフィルタを画像に掛けけあわせる処理が行われる。 これらのフィルタは、学習によってラベルの判別に有効な形状になっている。
画像内に畳み込みフィルタを一致するような部分があれば、その部分が強調されて移されて、「特徴マップ」と呼ばれる画像を生成する。
あるサイズのウィンドウを画像のすべての部分にあてはめ、そのウィンドウの中から1つだけ値を抽出して新しい画像に写す操舵をする。
ウィンドウの中でもっとも大きい値を抽出する。配列が小さくなるので、データ量を削減できる。
多くの CNN モデルで利用されている。
ウィンドウの中の値の平均値を抽出する。
畳み込み層、プーリング層の処理で得られた特徴マップを読み込み、これらに含まれる特徴量を抽出する。 最終的には、出力層に予測や分類の結果を出力する。
畳み込み処理と同様に、何層にも積み重ねることでより複雑かつ有効な特徴量を利用した処理が可能。
通常のニューラルネットワークと同じ構造を取る。
様々なパターンを網羅したデータを収集する代わりに、手元のデータから擬似的に別のデータを生成する手法。データの水増しとも言われる。
手元にあるデータそれぞれに対して、ランダムにいくつかの処理を施して新しいデータを作り出す。
- 上下左右にずらす
- 上下左右を反転する
- 拡大・縮小する
- 回転する
- 斜めに歪める
- 一部を切り取る
- コントラストを変える
2012年の ILSVRC でトロント大学のジェフリー・ヒントン率いるチームが用いた手法。
- 活性化関数に ReLU を使用
- LRN (Local Response Noralization) という、局所的正規化を行う層を用いる
- ドロップアウトを使用する
畳み込み層とプーリング層から構成される基本的な CNN。画像の分類タスクで用いられる。
重みのある層を全部で16層まで重ねてディープにしている。 3x3 の小さなフィルターによる畳み込み層を連続して行っている点が特徴。
基本的には CNN と同じ構成で、ネットワークが縦方向の深さだけでなく、横方向にも深さ(広がり)を持っているのが特徴。 横方向の幅は「インセプション構造」と呼ばえる。
層を飛び越えた結合
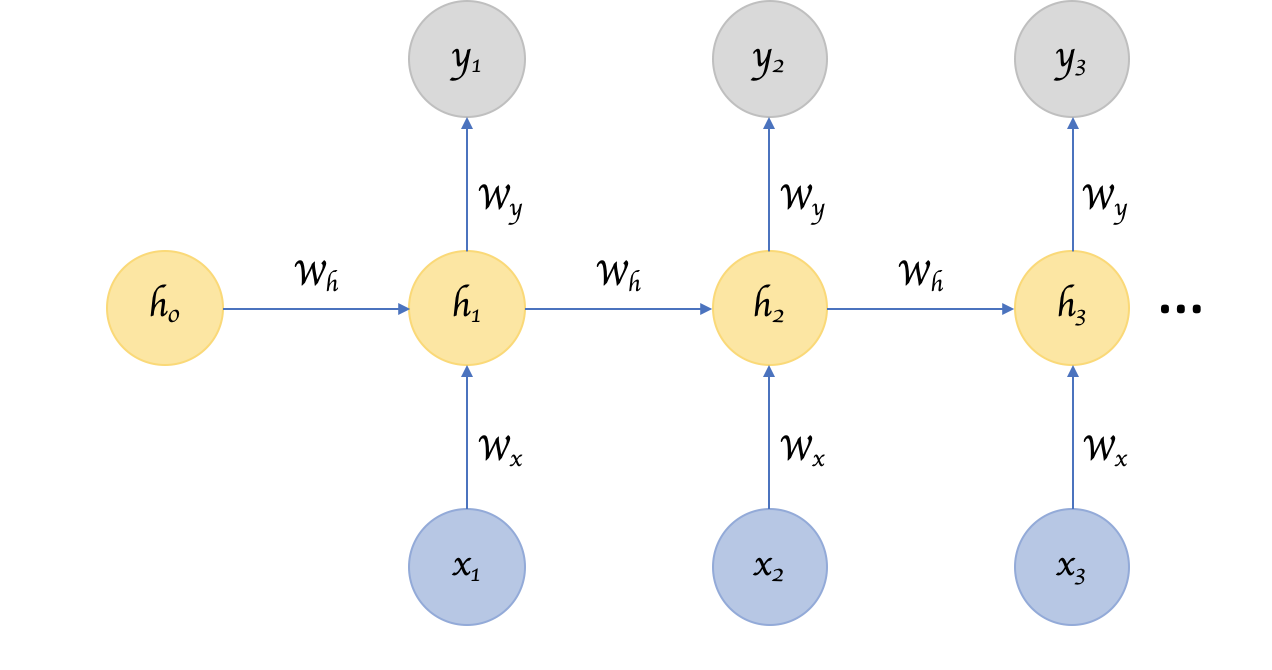
時系列データにおいて、ある時間的に近接した要素同士は影響を与え合う可能性が高いが、時間的に遠く離れた要素が影響を与えることは少ない。 この性質を使えば、パラメータの数を減らすことができる。これが RNN である。
時系列データを入力して、データから時間依存性を学習できるモデル。 内部に閉路(行って戻ってくる経路)を持つニューラルネットワーク。 RNN は過去の情報を保持できるため、過去の入力を参考に「時系列データの次の時点での値」を予測する。 自然言語処理への応用が盛んで、機械翻訳技術などに応用されている。
RNN を順伝播型ネットワークに置き換えて誤差逆伝播法を適用する手法。
入出力間で系列長が違う場合のニューラルネットワークを用いた分類法。
遠い過去の入力を現在の出力に反映する手法。
従来の RNN の欠点であった「短期的な情報しか保持できない」という点を改良し、長期的な情報を考慮して予測計算を行えるようにしたもの。
時系列データを入力・処理し、時系列データを出力するモデル。
代表的な応用として入力と出力を異なる言語列とする翻訳が実現できる。 これは NMT(ニューラル機械翻訳)と呼ばれ、従来の SMT(統計的機械翻訳)よりも大幅に性能が向上している。
LSTM を2つ(未来と過去)組み合わせることで、未来から過去方向も含めて学習できるモデル。
入力が時系列なら出力も時系列で予測する。自然言語処理を中心に研究されている分野。
2つの LSTM を組み合わせて、時系列を入力して時系列を出力する手法。(Sequence-to-Sequence)
モデルは大きく「エンコーダ」と「デコーダ」の2つの LSTM に分かれており、エンコーダが入力データを、デコーダが出力データをそれぞれ処理する。
過去の時点それぞれの重みを学習することで、時間の重みをネットワークに組み込む。
学習済みのネットワークを利用して新しいタスクの識別に利用する手法。
ディープニューラルネットワークの最後の層では、分類に有効な特徴量が伝わっていると考えられるため、最後の層を切り取って、代わりに SVM などの従来の機械学習分類器をつなげても、うまく分類できる。
学習済みのモデルを使い、最後の方の層だけをタスクに合わせて学習し直す(微調整する)手法。
最初の方の層で捉えられる特徴はタスクによって変わることはないが、最後の層で捉えられる特徴はタスクによって変わるため、学習をやり直す必要がある。
ドメインを変えて転移学習を行う手法。 (ex. 新聞記事を分析するように学習したモデルを初期値にして、ツイートを分析するモデルを作成する)
通常出力する値の他に、入力したデータのドメインも出力することで、モデルが特定の領域に特化しないようにする手法。
転移元と転移先のタスクがそれほど似ていないので、通常の学習よりも性能の悪いモデルが作られてしまうこと。
複数のタスクについて同時に学習させること。通常の転移学習は一度に特定のタスクについてモデルを学習させる。
あるラベルについての訓練データが一つ(あるいは少数)しかなくても正しい出力ができる手法。 「一を聞いて十を知る」学習方法。
特定のラベルがついた訓練データが存在しない場合にそのラベルを出力するような、「Zero-shot 学習」と呼ばれる手法も研究されている。
強化学習は、システムが「状態」を定義し、試行錯誤を重ねながら、自動的に報酬を最大化する「方策」を見つけることができる。 しかし、こうした問題はかなり厄介で、1990年代には活発に研究が行われたものの、2000年代に入るとその勢いも衰えてしまいました。
ディープラーニングの登場でその状況が打開されつつあり、さらに探索による先読みを組み合わせることで、AlphaGo(碁)の躍進につながった。
行動を学習する仕組み。
ある環境で、目的とする報酬(スコア)を最大化するためにはどのような行動をとっていけばいいかを学習していく。 機械学習では、想定する「状態」の数が非常に多くなったり、人による「状態」の想定に限界があったりした。
強化学習のアルゴリズムは、「モデルベース」と「モデルフリー」に大別される。
価値ベースの方法で、「ある状態においてある行動をとることがどれくらい良いか」という行動の価値を行動していく。
強化学習の改善手法としては、以下の3種類に基づいている。
上記3つのモデルを入れた手法。
カリフォルニア大学バークレー校が開発している、ディーブラーニングと強化学習を組み合わせたロボット。
報酬の設定を変更すれば、異なる動作を学習することができる。 一旦学習した内容はコピーして、同じタイプのロボットであれば同じように動かすことができる。
DeepMind社が開発した碁のプログラム。
どのような手を打つべきかの探索にはモンテカルロ木探索が用いられている。
2017年10月に発表された、棋譜を全く必要としない、完全に自己対局のみで学習していく碁のプログラム。 従来の AlphaGo を超える強さとなった。
DeepMind が考案した、Q学習の行動価値関数を、深い構造を持ったニューラルネットワークで置き換えたモデル。
アタリ社のゲームを学習された例では、49ゲームのうち29ゲームで、人間並、あるいはそれ以上のスコアを出した。
強化学習のシュミレーション用プラットフォーム。
公式ドキュメントでさまざまなチュートリアルが用意されているので、実際に動かして強化学習の面白さを体験できる。

ディーブラーニング技術は、識別や回帰だけでなく、これまで存在していなかったデータ、例えば架空の画像の生成にも利用できる。
一般に「生成モデル」と呼ばれるモデルを使うことで、AI 技術による「創作」が可能となる。 ディープニューラルネットワークを使った生成モデルは「深層生成モデル」と呼ばれる。
オートエンコーダの中間層の圧縮された特徴表現の数値を確率分布に従うように変更し、さらにエンコーダの出力とデコーダーの入力をこれにあわせて変更したのもの。
確率分布に従うことで、圧縮された特徴表現の数値を変動させ、デコーダーの所期の性能(いろいろな猫の画像の生成)を達成できる。
2014年にイアン・グッドフェローらによって発表された、生成ネットワークと識別ネットワークからなる教師なし学習法。
ヤン・ルカンが GAN について、「機械学習において、この10年間で最もおもしろいアイディア」であると形容した。
トレーニングに利用したデータに類似した出力を生成できるため、希少データの水増しや、作風をまねた絵画や楽曲の生成など、様々な応用が進められている。
-
生成ネットワーク
ランダムノイズベクトルから入力データのレプリカを作ろうとする 訓練データと同じようなデータを生成する
-
識別ネットワーク
そのデータが訓練データから来たものか、生成ネットワークから来たものかを識別する
グラフ構造(データ間のつながりを持った構造)のデータを入力とするニューラルネットワーク。
GNN やオートエンコーダ、RNN を構築することができるため、広範囲の応用が可能。 分子構造の予測や自然言語処理などへの応用がある。
2006年にジェフリー・ヒントンが提唱した、教師なし学習(オートエンコーダに相当する層)に制限付きボルツマンマシンという手法を用いている。
1985年にジェフリー・ヒントンとテリー・セジュノスキーによって開発された、確率的回帰結合型ニューラルネットワークの一種。
「あらゆる問題に対して万能なアルゴリズムは存在しない」という定理。
1958年にアメリカの心理学者フランク・ローゼンブラットが提案したニューラルネットワークの元祖のモデル。
物事の本質的な特徴を決定づける要素はわずかであるという性質。この性質を利用した「スパースモデリング」という手法もある
成分のほとんどが 0 である行列のことを「スパース行列」とも言う
Googleが開発した深層分散学習のフレームワーク。
分散並列処理技術で高速な処理が可能となっている。
こちらのドキュメントに機械学習で利用可能なデータセットがまとまっている。
https://github.com/arXivTimes/arXivTimes/tree/master/datasets
手書き文字認識学習用データ。
手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセット。 さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセット。
URL: http://yann.lecun.com/exdb/mnist/
スタンフォード大学がインターネット上から画像を集め分類したデータセット。
一般画像認識用に用いられる。ImageNetを利用して画像検出・識別精度を競うThe ImageNet Large Scale Visual Recognition Challenge(ILSVRC)などコンテストも開かれている。
URL: http://www.image-net.org/
2012年、ILSVRC で従来の SVM に替わりディープラーニングに基づくモデルで初めて優勝した。
筆頭開発者であるアレックス・クリジェフスキーの名前から、「アレックスネット」と呼ばれている。
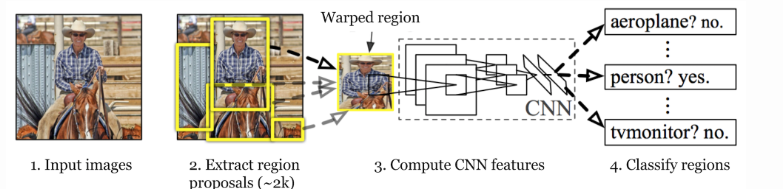
空間認識にすぐれている CNN を分割された領域ごとに適用するディープニューラルネットワーク。
関心領域(ROI)の切り出しには、HOG など CNN ではない従来の手法を用いる。ROI の画像切り出しの後に領域ごとに個別に CNN を呼びだす二段階のモデルのため、時間がかかっていた。
画像上の矩形領域(長方形)、バウンディングボックスで、領域を切り出す。
領域の切り出しと切り出した領域の物体認識を同時に行うモデル。
fast RCNN を更に改良したモデル。 ほぼ実時間(1秒あたり16フレーム)で入力画像から関心領域の切り出しと認識がきるようになった。
領域の切り出しと認識を同時に行う CNN。
領域の切り出しと認識を同時に行う CNN。
R-CNN のような矩形領域を切り出すのではなく、より詳細な領域分割を得るモデル。 各画素がどのカテゴリーに属するかを求める手法。
同じカテゴリーに属する複数の物体が同一ラベルとして扱われる。
個々の物体ごとにカテゴリーを認識させる。
セマンティックセグメンテーションを実現するネットワークモデル。
FCN とは文字通りすべての層が畳み込み層であるモデル。
入力画像の画素数だけ出力層が必要、つまり出力層には、縦画素数 x 横画素数 x カテゴリー数の出力ニューロンが用意される。
最終出力層で入力層と同じ解像度を得るために、下位層のプーリング層の情報を用いて詳細な解像度を得る手法。
CNN では畳み込み演算によって畳み込みのカーネル幅(受容野)だけ近傍の入力刺激を加えて計算することになるため、上位層では下位層にくらべて受容野が大きくなり、その影響で画像サイズは小さくなる。
- 形態素解析を用いて、文章を単語などの最小単位(形態素)に切り分ける
- データのクレンジングにより、不要な文字列を取り除く
- BoW(Bag-of-Words)などを用いて、形態素解析をおこなったデータをベクトル形式に変換する
- TF-ID などを用いて、各単語の重要度を評価する
文章中の単語は、記号の集まりとして表現できる。この記号をベクトルとして表現することで、ベクトル間の距離や関係として単語の意味を表現するモデル。
Googleのトマス・ミコロフ率いる研究者チームによって2013年に作成された。
単語の意味をベクトル空間の中に表現したと考えられるため、「単語埋め込みモデル(word embedding models)」とも呼ばれる。
word2vec には以下の2つの手法がある。
ある単語を与えて周辺の単語を予測するモデル。
周辺の単語を与えてある単語を予測するモデル。
情報リソースに意味を付与することで、コンピュータで高度な意味処理を実現する
単語同士の意味関係をネットワークによって表現する
言語処理に確率的あるいは統計的手法を用いる技術
自然言語処理などにおいて、文の品詞や統語構造、単語と単語、文書と文書などの関係性について定式化したもの。
2013年に word2vec を提案したトマス・ミコロフらによって開発されたモデル。
word2vec との変更点は、単語の表現に文字情報も含めること。文字データを援用することで訓練データには存在しない単語(Out Of Vocabulary: OOV)を表現することを可能にした。
アレンインスティチュート によって開発された文章表現を得るモデル。
2層の双方向リカレントネットワーク言語モデルの内部状態から計算される。fastText と同じく OOV であっても意味表現を得ることが可能。
1対多のマルチタスク学習により、複数課題間に共通の普遍的な文章埋め込み表現を学習するモデル。
文書内に出現する単語について,以下の2つの情報から,その単語の重要度を算出する手法である.
- 単語の出現頻度 (TF値)
- 単語の逆文書頻度 (IDF値)
画像認識をする CNN と言語モデルとしてのリカレントニューラルネットワークを組み合わせて、画像に脚注をつける手法。
チーリングマシンをニューラルネットワークで実現する試み。
2016年に Google DeepMind 社により開発された、音声合成と音声認識の両者を行うことができるモデル。
サンプリングされた系列点としての音声をそのまま DNN を用いて処理することにより、近似や調整などという作業が不要になった。 自然な発音が実現されたため、音声合成のブレイクスルーとして注目されている。
与えられた文やデータから人が話す音声を合成する技術。
近年劇的に発達し、人間が話しているものとほぼ同等に自然な音声を生成することが可能なレベルに達した。
DeepMind が考案した、Q学習の行動価値関数を、深い構造を持ったニューラルネットワークで置き換えたモデル。
モンテカルロ法を使った木の探索。
ヒューリスティクス(途中で不要な探索をやめ、ある程度の高確率で良い手を導ける)な探索アルゴリズムである。
2017年10月に発表された、棋譜を全く必要としない、完全に自己対局(セルフプレイ)のみで学習していく碁のプログラム。 従来の AlphaGo を超える強さとなった。
行列の計算問題を NumPy で解く例。
Anaconda の Docker image でローカル環境を構築します。
Docker Hub: https://hub.docker.com/r/continuumio/anaconda3
# Download Docker image
docker pull continuumio/anaconda3
# Start a Jupyter Notebook server and interact with Anaconda via your browser
docker run -i -t -p 8888:8888 continuumio/anaconda3 /bin/bash -c "/opt/conda/bin/conda install jupyter -y --quiet && mkdir /opt/notebooks && /opt/conda/bin/jupyter notebook --notebook-dir=/opt/notebooks --ip='*' --port=8888 --no-browser --allow-root"Numpy: https://numpy.org/
import numpy as npa = np.matrix([-1, 2])
b = np.matrix([0, 5])
a + b
matrix([[-1, 7]])
a - b
matrix([[-1, -3]])
a + b * 2
matrix([[-1, 12]])a = np.matrix([
[1, -1, 1],
[0, 1, 1]
])
b = np.matrix([
[1, 1],
[-1, 1],
[1, 1]
])
a * b
matrix([[3, 1],
[0, 2]])a = np.matrix([
[1, 2],
[2, 1]
])
b = np.matrix([
[1, 2],
[3, -4]
])
a * b
matrix([[ 7, -6],
[ 5, 0]])
b * a
matrix([[ 5, 4],
[-5, 2]])プライバシー侵害の予防を指向し、仕様段階から検討するプロセス。
最近はセキュリティに配慮した「セキュリティ・バイ・デザイン」や価値全般に配慮した「バリュー・バイ・デザイン」などの用語を見かけることも多くなった。
2016年に学術団体である IEEE が出したレポート。
自律システムの透明性やデータプライバシー処理などの標準規格(P7000)を目指している。
資料: https://confit.atlas.jp/guide/event-img/jsai2018/3H1-OS-25a-05/public/pdf?type=in
- 著作権法
- 不正競争防止法
- 個人情報保護法
- 個別の契約
- その他の理由により、データの利用に制約がかかっている場合
AIの公平性、説明可能性、透明性
欧州経済領域(EEA)内の個人データの保護を規定する法律であり、データ管理者及びデータ処理者に対し、個人データの取り扱いや移転に係る義務を定めている。 2016年4月に制定され、2018年5月に施行された。
Google Photos がアフリカ系の女性に「ゴリラ」とラベル付をしてしまった事件
危機管理対応
2016年9月に、Amazon、Google、DeepMind(Google)、Facebook、IBM、Microsoft が設立した、将来のAI研究と開発のための非営利団体。
人類の存続の危機を回避することを目的とする組織、Future of Life Institute(FLI) が、2017年2月にアメリカのアシロマで発表した、人工知能(AI)の研究課題、倫理と価値、長期的な課題を23にまとめたガイドライン。
2018年5月に内閣府のCSTIの下に設置された会議。 AIに関する倫理や中長期的な研究開発・利活用などについて、産学民官のマルチステークホルダーによる幅広い視野からの調査・検討が行われ、2019年3月に「人間中心のAI社会原則」が決定された。
ディーブラーニングを使う機械学習では、特徴抽出も自動化されているため、与えられたデータに対する推論過程そのものが「見えない」状態となる。 しかし、自動運転や医療診断など、推論結果が重大な問題を引き起こす可能性があるものに関しては、原因究明が要請される。
各国とその国の経済成長戦略の組み合わせ。
| 国 | 政策 |
|---|---|
| 日本 | 新産業構造ビジョン |
| 英国 | RAS 2020 戦略 |
| ドイツ | デジタル戦略2025 |
| ** | インターネットプラスAI3年行動実施法案 |
2016年にホワイトハウスが出した人工知能に関する報告書。 AIの現状; AIの現在及び将来の潜在的な用途; AIの進展が引き起こす社会政策・公共政策上の問題を取り上げているほか、連邦省庁等が取るべき具体的な取組みについて提言を行っている。
概要: https://nedodcweb.org/reports/report2016/2016-10-24/
上記報告書とともにホワイトハウスが公表した報告書。
判断結果の理由をユーザーに説明できる AI プログラムを開発することが必要であることを主張した。
概要: https://nedodcweb.org/report/AI%20Research%20Development%20Plan.pdf
2016年12月にホワイトハウスが公開したAI(人工知能)と経済に関するレポート。
AI の普及が最大で 300 万件越えの雇用に影響を与える可能性があることを説いている。
ニュース記事: https://japan.zdnet.com/article/35094155/
経済産業省が定めた先端 IT 人材がどのような人材需給状況にあるかの推定によると,2020 年には需給ギャップが広がり人材の不足は4.8万人に及ぶと言われている。
資料: https://www.meti.go.jp/committee/kenkyukai/shoujo/daiyoji_sangyo_skill/pdf/001_06_00.pdf
収集・生成したデータや学習済みのモデルは、一定の条件を満たせば、知的財産として保護される。 関連する法令として、特許権法、著作権法、不正競争防止法などがある。
個人情報を取り扱う際には、利用目的をできる限り特定しなければならない(個人情報保護法15条1項)
当初予定されていなかった個人情報の取扱をするのであれば、原則として事前に本人の同意が必要になる(同16条1項) 加えて、その利用目的を本人に通知し、または公表しなければならない(同18条1項)
著作権法47条の7によって、著作者にモダンで記録や翻案をしても適法となっている。2018年の著作権法改正によって、学習データを第三者と共有したり、一般に販売したり、ネット上で公開するとことも、一定の条件下で適法となっている(改正著作権法30条4)
「情報解析を行うために著作物を複製すること」が、営利・非営利を問わず適法とされていて(47条7)、世界的に見ても先進的な規定を言われている。
論文や写真など著作物にあたるデータを利用したい場合は、著作権者から許諾を得ることが原則。ただし、学習用データの作成については一定の要件のもと自由に行える例外規定もある(著作権法第47条7、改正著作権法第30条4)
もっとも、著作権法による制約をクリアした場合でも、著作権とは別の観点からデータ利用に制約がかかることがある。
- 営業秘密にあたるデータ(不正競争防止法2条6)
- 限定利用データ(改正不正競争防止法2条7)
- 購買履歴や位置情報などのパーソナルデータ
- ライセンス契約で利用条件が指定されているデータ
- 「通信の秘密」にあたるメールの内容(憲法21条2、電気通信事業法4条)
2018年に経済産業省が公表した、民間事業者等が、データの利用等に関する契約やAI技術を利用するソフトウェアの開発・利用に関する契約を締結するガイドライン。
概要: https://www.meti.go.jp/press/2018/06/20180615001/20180615001.html
2018年5月に運用が開始された。
データ主体の権利・利益を強化した規則になっている、
日本に対しても域外適用されるため、EU向けにもサービスを提供する日本企業も法的規制を受ける場合がある。
- BRETT: Deep-learning robot
- AlphaGo
- Google DeepMind's Deep Q-learning playing Atari
- 分身ロボットカフェ DAWN
- Facenet
- Google が開発した顔認識システム
- Tay
- Microsoft が開発したチャットボット。間違った方向に学習が進み不適切な発言をするようになった
画像処理に必要な大規模な並列演算処理を行う。
GPU(GPGPU)の開発をリードしているのは NVIDIA。
GPU を画像以外の目的での利用に最適化したもの。
Google が開発したテンソル計算処理に最適化された GPU。
誤った学習を引き起こすように意図的に入力に小さな摂動を加えて、アルゴリズムを騙す攻撃。
自動運転技術を搭載した「自動運転車」は、運転手と車(システム)のどちらが運転動作の主体となるか、また走行可能エリアはどうなるか、によってレベル0~5の6段階に分かれている。
このレベル分けはアメリカの非営利団体SAEインターナショナルが発表したもので、現在 日本はもちろんのこと、世界においても共通の基準と認識されている。
| 自動運転レベル | 名称 | 主体者 | 走行可能エリア | ルール | | --- | --- | --- | --- | --- | --- | | 0 | 運転自動化なし | 運転者 | – | 運転者が全てのタスクを担当 (つまり従来の運転状態) | | 1 | 運転支援 | 運転者 | 限定的 | 速度かハンドルを運転手が対応 走行エリアの限定あり | | 2 | 部分運転自動化 | 運転者 | 限定的 | 常時 運転手がシステムを監督 走行エリアの限定あり | | 3 | 条件付き運転自動化 | 車(システム) | 限定的 | 緊急時は運転手が対応 走行エリアの限定あり | | 4 | 高度運転自動化 | 車(システム) | 限定的 | 運転手なしでの走行OK 走行エリアの限定あり | | 5 | 完全運転自動化 | 車(システム) | 限定なし | 運転手なしでの走行OK 走行エリアの限定なし |
Alphabet傘下の自動運転車開発企業。 2016年12月13日にGoogleの自動運転車開発部門が分社化して誕生した
まとめ
- 空港/国の重要施設/原子力事業所等の周辺、私有地上空
- 150m以上の上空
- 人家の集中地域
- 日中での飛行に限る(夜間は禁止)
- 目視の範囲内(見えなくなる場所に飛ばすのは禁止)
- 距離の確保(対人、対物への距離をとる)
- イベント場所での飛行禁止
- 危険物輸送/物件投下の禁止
人工知能などにより、完全に自律し、かつ強力な殺傷能力を持つ兵器。
現段階では存在していないが、将来、完全な自律型致死性兵器が開発された場合、民間人・味方を攻撃しかねないという倫理的な理由から、専門家の間で議論が続いている。
過剰な傷害または無差別の効果を発生させると認定される通常兵器の使用を禁止または制限する多国間条約。 近年は LAWS に関する政府専門家会合がくり返し開催され、活発な議論が続けられている。
Python でもっとも利用されている機械学習ライブラリ。 教師あり学習、教師なし学習、次元削減のさまざまなアルゴリズムを備えている。
多次元配列を扱うためのさまざまな機能がパッケージされたライブラリ。
配列操作の中でもデータ分析に特化したライブラリ。 表形式のデータに対するさまざまな処理をサポートしている。
日本語の形態素解析ライブラリ。
英語の形態素解析ライブラリ。
コンピュータで画像や動画を処理するためのさまざまな処理を実装できるライブラリ。
画像のぼかしや二値化、グレースケールに拡大縮小、回転などの基本操作から、エッジ検出やヒストグラムの計算など、機械学習アルゴリズムに入力するために必要な前処理を網羅している。
折れ線グラフや棒グラフなどの基本的なグラフから、ヒストグラムなどの統計用グラフや3D散布図など、多様な表示形式を利用できる。
Google の開発するディープラーニングのフレームワーク。
TensorBoard という可視化ソフトフェアが付属しており、計算グラフを表示できるほか、学習がどのように進んでいったかわかりやすく可視化できる。
Facebook が開発している TensorFlow と双璧をなすフレームワーク。
デフォルトで Define-by-Run アプローチが取られ、動的に計算グラフを生成していくため、柔軟な計算ができる。
非常に簡単なコードでモデルを組み込み学習を行うことができる。 学習自体は裏で TensorFlow が行っている。 Keras は TensorFlow のラッパー。
Preferred Network によって開発されたフレームワーク。
Define-by-Run という形式を採用している。 開発の終了が発表されており、今はメンテナンスフェーズになっている。
- ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 仕事ではじめる機械学習
- 図解即戦力 機械学習・ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書
-
- 最終回: 脳神経科学と汎用人工知能 (福島邦彦)