SGLang is a fast serving framework for large language models and vision language models. It makes your interaction with models faster and more controllable by co-designing the backend runtime and frontend language.
The core features include:
- Fast Backend Runtime: Efficient serving with RadixAttention for prefix caching, jump-forward constrained decoding, continuous batching, token attention (paged attention), tensor parallelism, flashinfer kernels, and quantization (AWQ/FP8/GPTQ/Marlin).
- Flexible Frontend Language: Enables easy programming of LLM applications with chained generation calls, advanced prompting, control flow, multiple modalities, parallelism, and external interactions.
- [2024/04] 🔥 SGLang is used by the official LLaVA-NeXT (video) release (blog).
- [2024/02] 🔥 SGLang enables 3x faster JSON decoding with compressed finite state machine (blog).
- [2024/01] SGLang provides up to 5x faster inference with RadixAttention (blog).
More
- [2024/01] SGLang powers the serving of the official LLaVA v1.6 release demo (usage).
- Install
- Backend: SGLang Runtime (SRT)
- Frontend: Structured Generation Language (SGLang)
- Benchmark And Performance
- Roadmap
- Citation And Acknowledgment
pip install --upgrade pip
pip install "sglang[all]"
# Install FlashInfer CUDA kernels
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.3/
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install --upgrade pip
pip install -e "python[all]"
# Install FlashInfer CUDA kernels
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.3/
The docker images are available on Docker Hub as lmsysorg/sglang.
docker run --gpus all \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B --host 0.0.0.0 --port 30000- If you see errors from the Triton compiler, please install the Triton Nightly by
pip uninstall -y triton triton-nightly
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly
- If you cannot install FlashInfer, check out its installation page. If you still cannot install it, you can use the slower Triton kernels by adding
--disable-flashinferwhen launching the server. - If you only need to use the OpenAI backend, you can avoid installing other dependencies by using
pip install "sglang[openai]".
The SGLang Runtime (SRT) is an efficient serving engine.
Launch a server
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000
Send a request
curl http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "Once upon a time,",
"sampling_params": {
"max_new_tokens": 16,
"temperature": 0
}
}'
Learn more about the argument format here.
In addition, the server supports OpenAI-compatible APIs.
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# Text completion
response = client.completions.create(
model="default",
prompt="The capital of France is",
temperature=0,
max_tokens=32,
)
print(response)
# Chat completion
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."},
],
temperature=0,
max_tokens=64,
)
print(response)It supports streaming, vision, and most features of the Chat/Completions/Models endpoints specified by the OpenAI API Reference.
- Add
--tp 2to enable tensor parallelism. If it indicatespeer access is not supported between these two devices, add--enable-p2p-checkoption.
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000 --tp 2
- Add
--dp 2to enable data parallelism. It can also be used together with tp. Data parallelism is better for throughput if there is enough memory.
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000 --dp 2 --tp 2
- If you see out-of-memory errors during serving, please try to reduce the memory usage of the KV cache pool by setting a smaller value of
--mem-fraction-static. The default value is0.9
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000 --mem-fraction-static 0.7
- See hyperparameter_tuning.md on tuning hyperparameters for better performance.
- Add
--nnodes 2to run tensor parallelism on multiple nodes. If you have two nodes with two GPUs on each node and want to run TP=4, letsgl-dev-0be the hostname of the first node and50000be an available port.
# Node 0
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --tp 4 --nccl-init sgl-dev-0:50000 --nnodes 2 --node-rank 0
# Node 1
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --tp 4 --nccl-init sgl-dev-0:50000 --nnodes 2 --node-rank 1
- If the model does not have a template in the Hugging Face tokenizer, you can specify a custom chat template.
- To enable fp8 quantization, you can add
--quantization fp8on a fp16 checkpoint or directly load a fp8 checkpoint without specifying any arguments.
- Llama / Llama 2 / Llama 3
- Mistral / Mixtral
- Gemma / Gemma 2
- Qwen / Qwen 2 / Qwen 2 MoE
- LLaVA 1.5 / 1.6
python -m sglang.launch_server --model-path liuhaotian/llava-v1.5-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --chat-template vicuna_v1.1 --port 30000python -m sglang.launch_server --model-path liuhaotian/llava-v1.6-vicuna-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --chat-template vicuna_v1.1 --port 30000python -m sglang.launch_server --model-path liuhaotian/llava-v1.6-34b --tokenizer-path liuhaotian/llava-v1.6-34b-tokenizer --port 30000
- LLaVA-NeXT-Video
- Yi-VL
- see srt_example_yi_vl.py.
- StableLM
- Command-R
- DBRX
- Grok
- ChatGLM
- InternLM 2
- Mistral NeMo
Instructions for supporting a new model are here.
- Benchmark a single static batch. Run the following command without launching a server. The arguments are the same as those for
launch_server.py.python -m sglang.bench_latency --model-path meta-llama/Meta-Llama-3-8B-Instruct --batch 32 --input-len 256 --output-len 32 - Benchmark online serving. Launch a server first and run the following command.
python3 -m sglang.bench_serving --backend sglang --num-prompt 10
The frontend language can be used with local models or API models.
The example below shows how to use sglang to answer a mulit-turn question.
First, launch a server with
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000
Then, connect to the server and answer a multi-turn question.
from sglang import function, system, user, assistant, gen, set_default_backend, RuntimeEndpoint
@function
def multi_turn_question(s, question_1, question_2):
s += system("You are a helpful assistant.")
s += user(question_1)
s += assistant(gen("answer_1", max_tokens=256))
s += user(question_2)
s += assistant(gen("answer_2", max_tokens=256))
set_default_backend(RuntimeEndpoint("http://localhost:30000"))
state = multi_turn_question.run(
question_1="What is the capital of the United States?",
question_2="List two local attractions.",
)
for m in state.messages():
print(m["role"], ":", m["content"])
print(state["answer_1"])Set the OpenAI API Key
export OPENAI_API_KEY=sk-******
Then, answer a multi-turn question.
from sglang import function, system, user, assistant, gen, set_default_backend, OpenAI
@function
def multi_turn_question(s, question_1, question_2):
s += system("You are a helpful assistant.")
s += user(question_1)
s += assistant(gen("answer_1", max_tokens=256))
s += user(question_2)
s += assistant(gen("answer_2", max_tokens=256))
set_default_backend(OpenAI("gpt-3.5-turbo"))
state = multi_turn_question.run(
question_1="What is the capital of the United States?",
question_2="List two local attractions.",
)
for m in state.messages():
print(m["role"], ":", m["content"])
print(state["answer_1"])Anthropic and VertexAI (Gemini) models are also supported. You can find more examples at examples/quick_start.
To begin with, import sglang.
import sglang as sglsglang provides some simple primitives such as gen, select, fork, image.
You can implement your prompt flow in a function decorated by sgl.function.
You can then invoke the function with run or run_batch.
The system will manage the state, chat template, parallelism and batching for you.
The complete code for the examples below can be found at readme_examples.py
You can use any Python code within the function body, including control flow, nested function calls, and external libraries.
@sgl.function
def tool_use(s, question):
s += "To answer this question: " + question + ". "
s += "I need to use a " + sgl.gen("tool", choices=["calculator", "search engine"]) + ". "
if s["tool"] == "calculator":
s += "The math expression is" + sgl.gen("expression")
elif s["tool"] == "search engine":
s += "The key word to search is" + sgl.gen("word")Use fork to launch parallel prompts.
Because sgl.gen is non-blocking, the for loop below issues two generation calls in parallel.
@sgl.function
def tip_suggestion(s):
s += (
"Here are two tips for staying healthy: "
"1. Balanced Diet. 2. Regular Exercise.\n\n"
)
forks = s.fork(2)
for i, f in enumerate(forks):
f += f"Now, expand tip {i+1} into a paragraph:\n"
f += sgl.gen(f"detailed_tip", max_tokens=256, stop="\n\n")
s += "Tip 1:" + forks[0]["detailed_tip"] + "\n"
s += "Tip 2:" + forks[1]["detailed_tip"] + "\n"
s += "In summary" + sgl.gen("summary")Use sgl.image to pass an image as input.
@sgl.function
def image_qa(s, image_file, question):
s += sgl.user(sgl.image(image_file) + question)
s += sgl.assistant(sgl.gen("answer", max_tokens=256)See also srt_example_llava.py.
Use regex to specify a regular expression as a decoding constraint.
This is only supported for local models.
@sgl.function
def regular_expression_gen(s):
s += "Q: What is the IP address of the Google DNS servers?\n"
s += "A: " + sgl.gen(
"answer",
temperature=0,
regex=r"((25[0-5]|2[0-4]\d|[01]?\d\d?).){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)",
)Use regex to specify a JSON schema with a regular expression.
character_regex = (
r"""\{\n"""
+ r""" "name": "[\w\d\s]{1,16}",\n"""
+ r""" "house": "(Gryffindor|Slytherin|Ravenclaw|Hufflepuff)",\n"""
+ r""" "blood status": "(Pure-blood|Half-blood|Muggle-born)",\n"""
+ r""" "occupation": "(student|teacher|auror|ministry of magic|death eater|order of the phoenix)",\n"""
+ r""" "wand": \{\n"""
+ r""" "wood": "[\w\d\s]{1,16}",\n"""
+ r""" "core": "[\w\d\s]{1,16}",\n"""
+ r""" "length": [0-9]{1,2}\.[0-9]{0,2}\n"""
+ r""" \},\n"""
+ r""" "alive": "(Alive|Deceased)",\n"""
+ r""" "patronus": "[\w\d\s]{1,16}",\n"""
+ r""" "bogart": "[\w\d\s]{1,16}"\n"""
+ r"""\}"""
)
@sgl.function
def character_gen(s, name):
s += name + " is a character in Harry Potter. Please fill in the following information about this character.\n"
s += sgl.gen("json_output", max_tokens=256, regex=character_regex)See also json_decode.py for an additional example on specifying formats with Pydantic models.
Use run_batch to run a batch of requests with continuous batching.
@sgl.function
def text_qa(s, question):
s += "Q: " + question + "\n"
s += "A:" + sgl.gen("answer", stop="\n")
states = text_qa.run_batch(
[
{"question": "What is the capital of the United Kingdom?"},
{"question": "What is the capital of France?"},
{"question": "What is the capital of Japan?"},
],
progress_bar=True
)Add stream=True to enable streaming.
@sgl.function
def text_qa(s, question):
s += "Q: " + question + "\n"
s += "A:" + sgl.gen("answer", stop="\n")
state = text_qa.run(
question="What is the capital of France?",
temperature=0.1,
stream=True
)
for out in state.text_iter():
print(out, end="", flush=True)- The
choicesargument insgl.genis implemented by computing the token-length normalized log probabilities of all choices and selecting the one with the highest probability. - The
regexargument insgl.genis implemented through autoregressive decoding with logit bias masking, according to the constraints set by the regex. It is compatible withtemperature=0andtemperature != 0.
-
Llama-7B on NVIDIA A10G, FP16, Tensor Parallelism=1
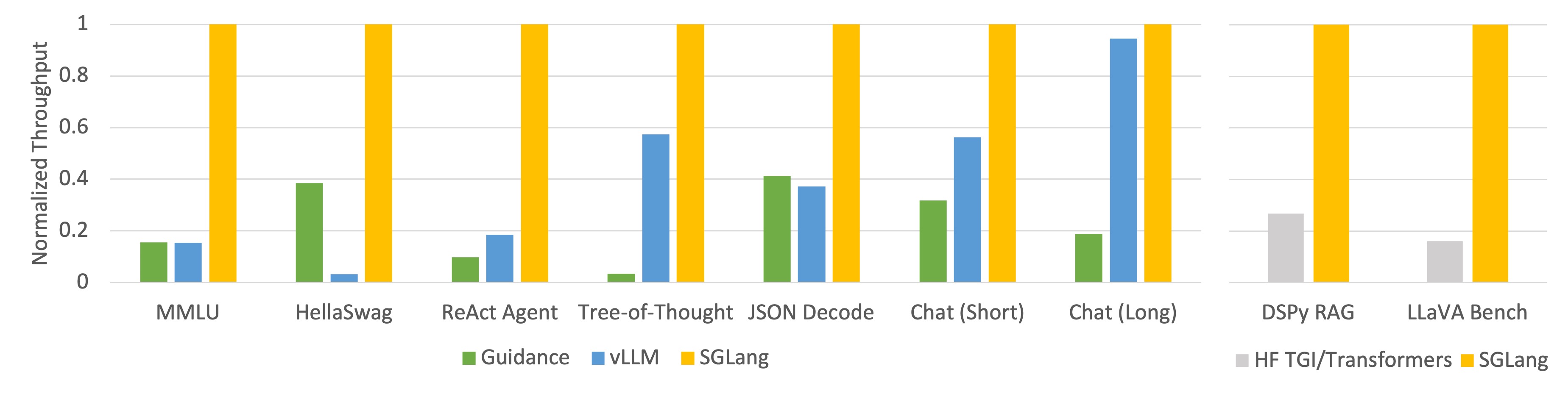
-
Mixtral-8x7B on NVIDIA A10G, FP16, Tensor Parallelism=8
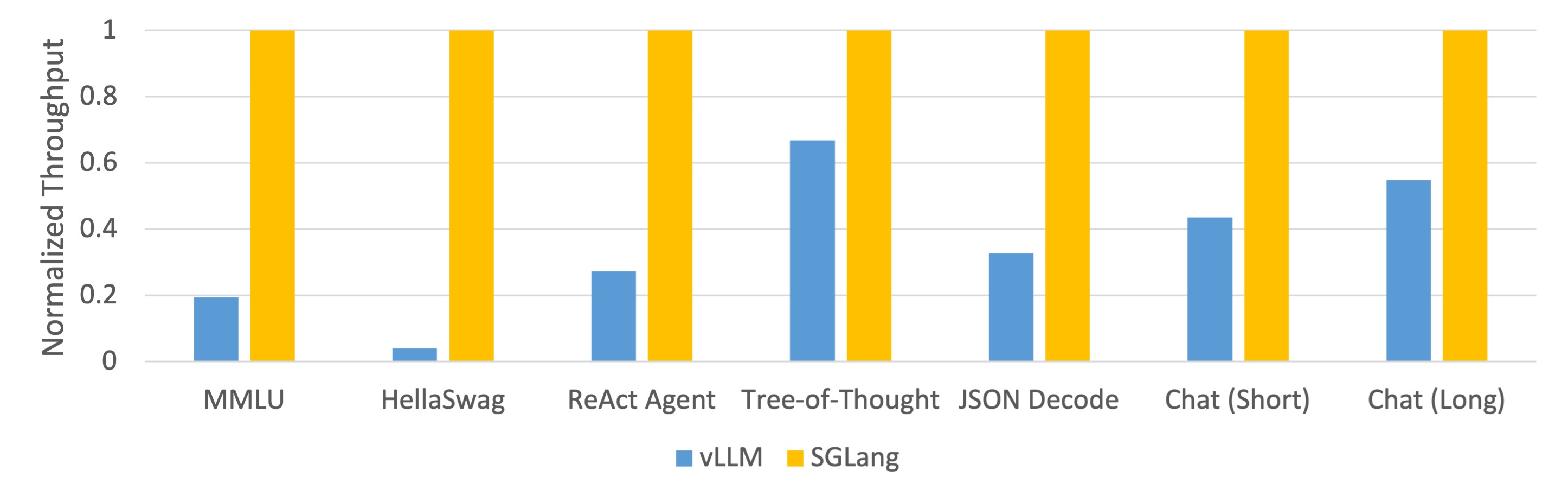
-
Learn more about the above results.
-
Synthetic latency and throughput benchmark scripts.


Please cite our paper, SGLang: Efficient Execution of Structured Language Model Programs, if you find the project useful. We also learned from the design and reused code from the following projects: Guidance, vLLM, LightLLM, FlashInfer, Outlines, and LMQL.