This project implements a facial expression recognition system using Convolutional Neural Networks (CNN) and Visual Transformers (Multi-Head Attention). The FER2013 dataset is augmented using various image processing techniques to improve the model's performance. The final model is exported as an ONNX file for deployment.
This facial expression recognition system combines the strengths of Convolutional Neural Networks (CNN) and Visual Transformers (Multi-Head Attention). The FER2013 dataset is used as the basis for training and testing, with multiple augmentation techniques applied to improve the model's generalization capabilities.

The live deployment takes the ONNX file and applies it to a live video stream. Faces are detected using Haar cascades, resized to match the model's input dimensions, and then passed through the model. The output is the class (emotion) with the highest probability.

A C++ version of the project compiles everything into a 4 MB executable. It generates a graph of the detected emotions and saves it in JSON format.



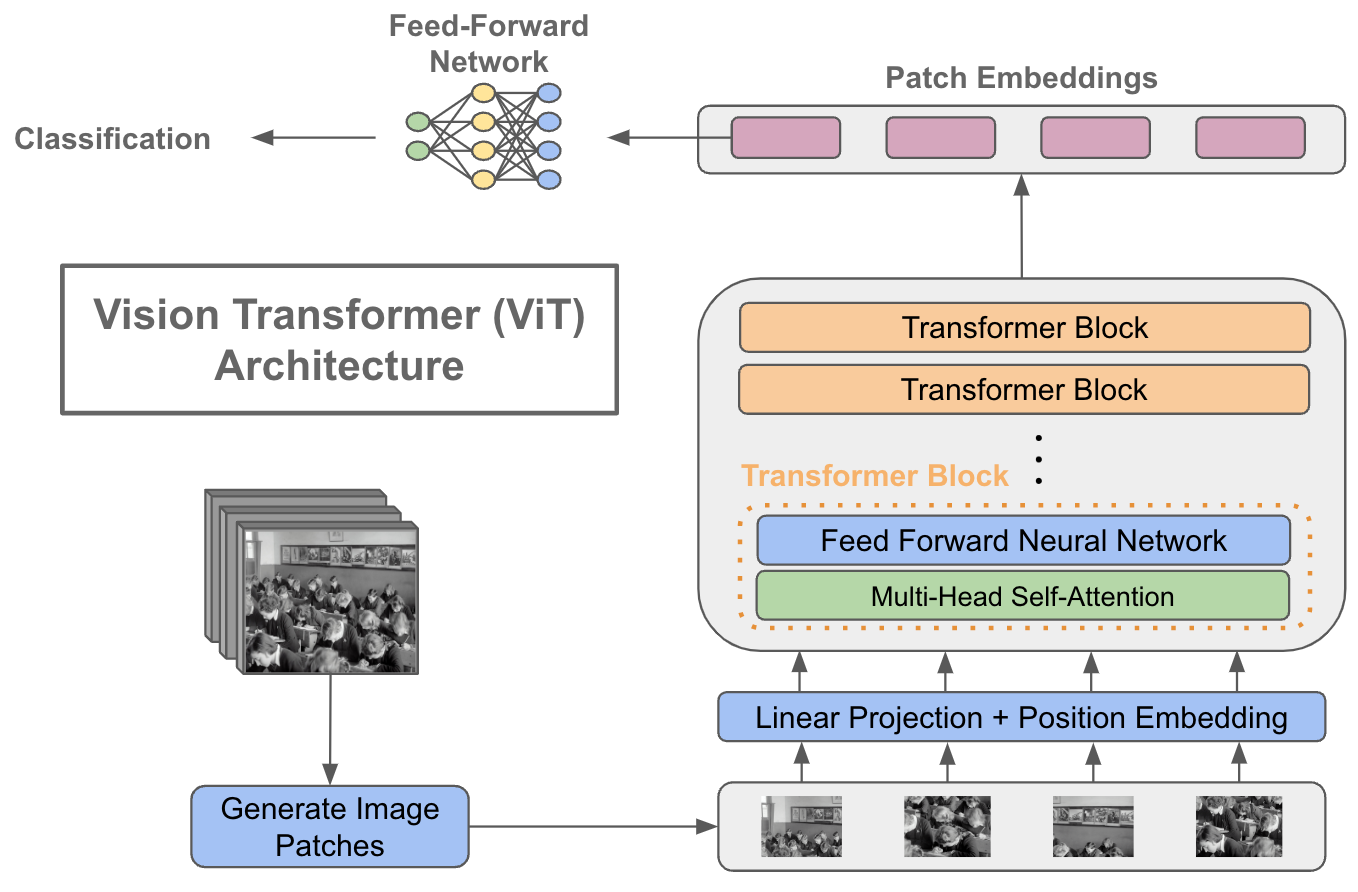
Multi-head attention is a technique that allows a neural network to attend to different parts of the input sequence simultaneously, enabling it to capture complex relationships between different parts of the input. In the context of CNNs used for facial expression detection, multi-head attention can be applied to the sequential layer, allowing the network to focus on different parts of the face at the same time. This can improve the network's ability to capture subtle changes in facial expressions that may be indicative of different emotions. Overall, the combination of CNNs and multi-head attention can be a powerful tool for accurately detecting facial expressions.


Commercial Use Must Contact - Sertan Avdan
sertan.avdan@outlook.com