- All souce codes stored in this repository is just a part of all for now (3/12/2019).
- So now you can not execute the benchmark or example in this repository.
- I will update this repository so that everyone can execute all sample scripts.
- Please wait for my returning to Japan after BDCAT '19 🙇♂️
- This is a reference implementation of this paper [1].
- This is an iterator implementation for Chainer
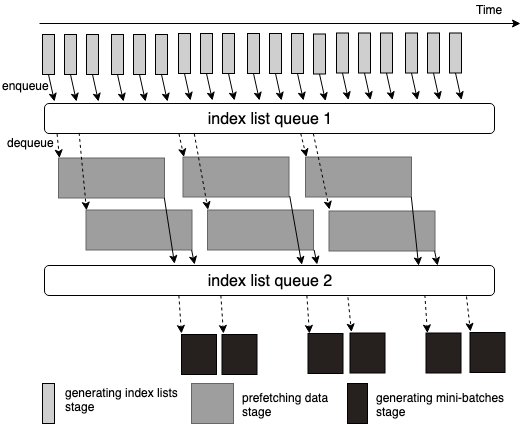
- This iterator executes prefetching from slow storage (such like network connected parallel file systems, e.g., Lustre) into fast storage (such like local SSD), and generating mini-batches in same time.
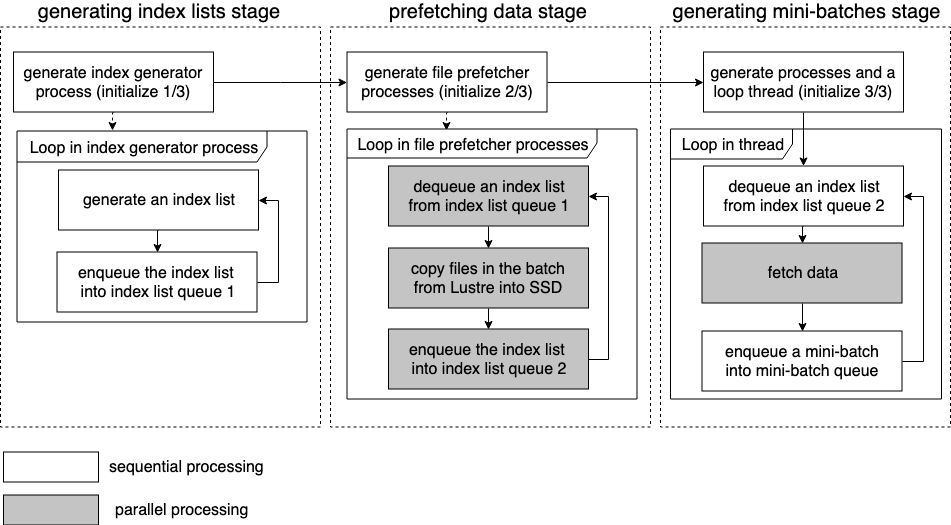
- This implementation is designed as a pipeline which consists of three stages.
- Python >= 3.6
- Chainer >= 6.4
[1] Kazuhiro Serizawa and Osamu Tatebe. 2019. Accelerating Machine Learning I/O by Overlapping Data Staging and Mini-batch Generations. In Proceedings of the 6th IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT '19). ACM, New York, NY, USA, 31-34. DOI: https://doi.org/10.1145/3365109.3368768