feapder 是一款简单、快速、轻量级的爬虫框架。起名源于 fast、easy、air、pro、spider的缩写,以开发快速、抓取快速、使用简单、功能强大为宗旨,历时4年倾心打造。支持轻量爬虫、分布式爬虫、批次爬虫、爬虫集成,以及完善的爬虫报警机制。
之前一直在公司内部使用,已使用本框架采集100+数据源,日采千万数据。现在开源,供大家学习交流!
读音: [ˈfiːpdə]
官方文档:http://boris.org.cn/feapder/
- Python 3.6.0+
- Works on Linux, Windows, macOS
From PyPi:
pip3 install feapder
From Git:
pip3 install git+https://github.com/Boris-code/feapder.git
若安装出错,请参考安装问题
创建爬虫
feapder create -s first_spider
创建后的爬虫代码如下:
import feapder
class FirstSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
FirstSpider().start()
直接运行,打印如下:
Thread-2|2021-02-09 14:55:11,373|request.py|get_response|line:283|DEBUG|
-------------- FirstSpider.parser request for ----------------
url = https://www.baidu.com
method = GET
body = {'timeout': 22, 'stream': True, 'verify': False, 'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'}}
<Response [200]>
Thread-2|2021-02-09 14:55:11,610|parser_control.py|run|line:415|INFO| parser 等待任务 ...
FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|DEBUG| 无任务,爬虫结束
代码解释如下:
- start_requests: 生产任务
- parser: 解析数据
scrapy给我的印象:
- 重,框架中的许多东西都用不到,如CrawlSpider、XMLFeedSpider
- 中间件不灵活
- 不支持从数据库中取任务作为种子抓取
- 数据入库不支持批量,需要自己写批量逻辑
- 启动方式需要用scrapy命令行,打断点调试不方便
本文以某东的商品爬虫为例,假如我们有1亿个商品,需要每7天全量更新一次,如何做呢?
首先需要个种子任务表来存储这些商品id,设计表如下:

CREATE TABLE `jd_item_task` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`item_id` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '商品id',
`state` int(11) DEFAULT '0' COMMENT '任务状态 0 待抓取 1 抓取成功 2 抓取中 -1 抓取失败',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;然后将这1亿个商品id录入进来,作为种子任务

CREATE TABLE `jd_item` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`batch_date` date DEFAULT NULL COMMENT '批次时间',
`crawl_time` datetime DEFAULT NULL COMMENT '采集时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;需求是每7天全量更新一次,即数据要以7天为维度划分,因此设置个batch_date字段,表示每条数据所属的批次。
这里只是演示,因此只采集标题字段
若使用scrapy,需要手动将这些种子任务分批取出来发给爬虫,还需要维护种子任务的状态,以及上面提及的批次信息batch_date。并且为了保证数据的时效性,需要对采集进度进行监控,写个爬虫十分繁琐。
而feapder内置了批次爬虫,可以很方便的应对这个需求。完整的爬虫写法如下:
import feapder
from feapder import Item
from feapder.utils import tools
class JdSpider(feapder.BatchSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379",
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
)
def start_requests(self, task):
task_id, item_id = task
url = "https://item.jd.com/{}.html".format(item_id)
yield feapder.Request(url, task_id=task_id) # 携带task_id字段
def parse(self, request, response):
title = response.xpath("string(//div[@class='sku-name'])").extract_first(default="").strip()
item = Item()
item.table_name = "jd_item" # 指定入库的表名
item.title = title
item.batch_date = self.batch_date # 获取批次信息,批次信息框架自己维护
item.crawl_time = tools.get_current_date() # 获取当前时间
yield item # 自动批量入库
yield self.update_task_batch(request.task_id, 1) # 更新任务状态
if __name__ == "__main__":
spider = JdSpider(
redis_key="feapder:jd_item", # redis中存放任务等信息key前缀
task_table="jd_item_task", # mysql中的任务表
task_keys=["id", "item_id"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="jd_item_batch_record", # mysql中的批次记录表,自动生成
batch_name="京东商品爬虫(周度全量)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
# 下面两个启动函数 相当于 master、worker。需要分开运行
spider.start_monitor_task() # maser: 下发及监控任务
# spider.start() # worker: 采集我们分别运行spider.start_monitor_task()与spider.start(),待爬虫结束后,观察数据库
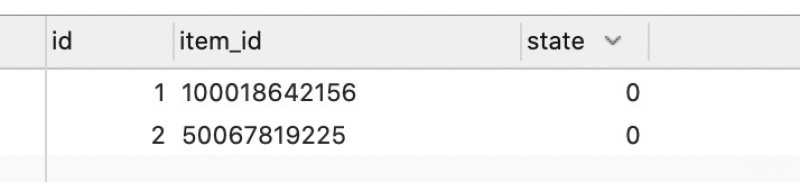
任务表:jd_item_task

任务均已完成了,框架有任务丢失重发机制,直到所有任务均已做完
数据表:jd_item:

数据里携带了批次时间信息,我们可以根据这个时间来对数据进行划分。当前批次为3月9号,若7天一批次,则下一批次为3月18号。
批次表:jd_item_batch_record

启动参数中指定,自动生成。批次表里详细记录了每个批次的抓取状态,如任务总量、已做量、失败量、是否已完成等信息
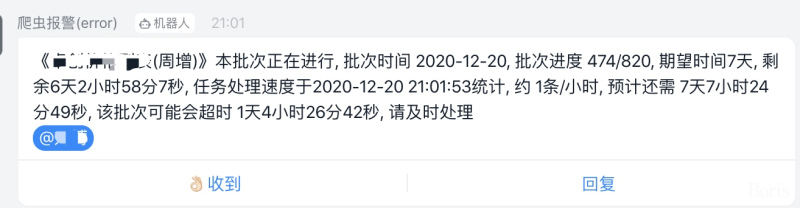
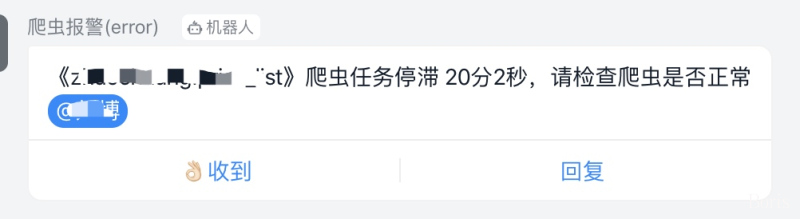
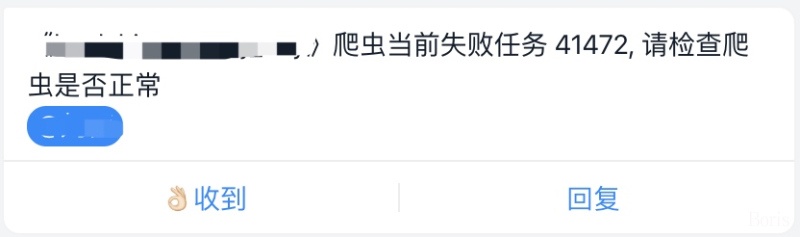
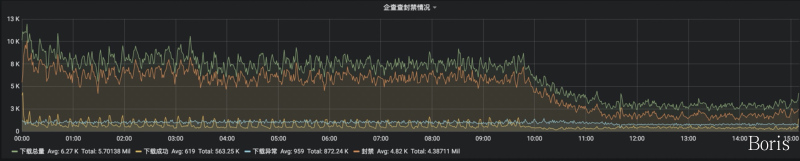
feapder会自动维护任务状态,每个批次(采集周期)的进度,并且内置丰富的报警,保证我们的数据时效性,如:
-
实时计算爬虫抓取速度,估算剩余时间,在指定的抓取周期内预判是否会超时
-
爬虫卡死报警
-
爬虫任务失败数过多报警,可能是由于网站模板改动或封堵导致
-
下载情况监控
知识星球:

星球会不定时分享爬虫技术干货,涉及的领域包括但不限于js逆向技巧、爬虫框架刨析、爬虫技术分享等