An uncertainty-based random sampling algorithm for data augmentation
Overview
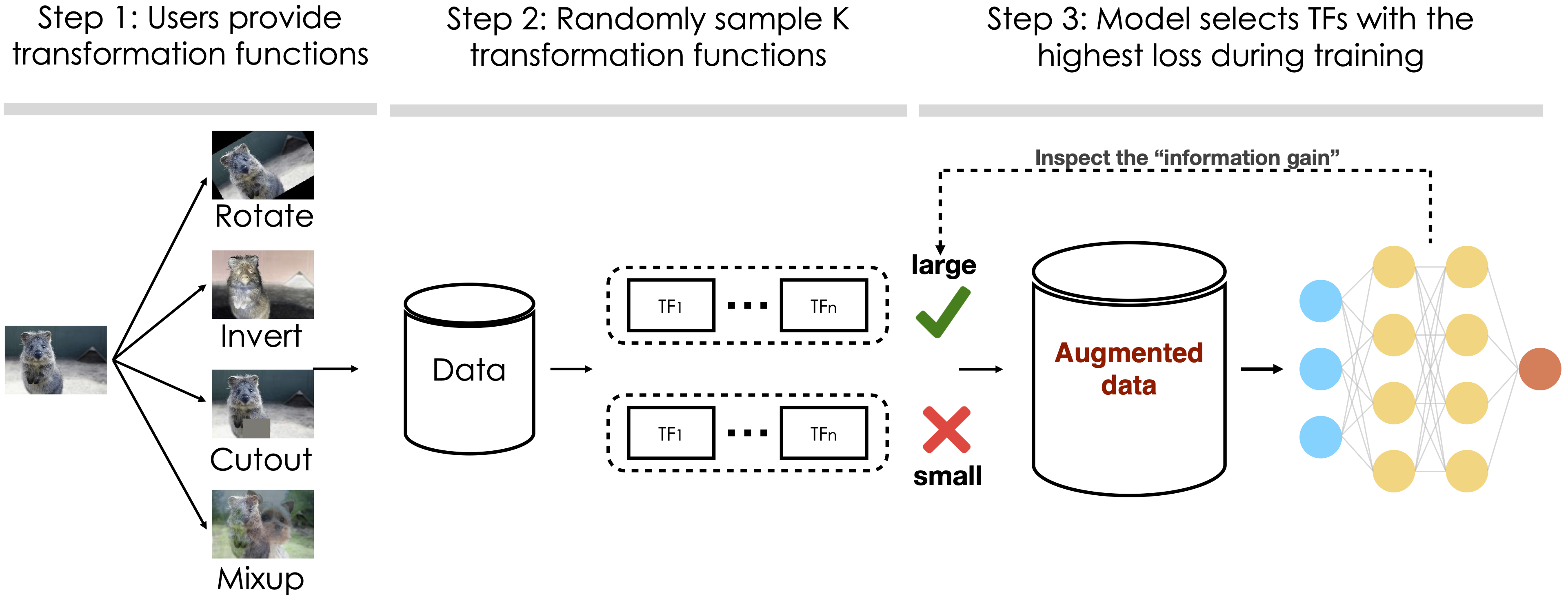
Data augmentation is a powerful technique to improve performance in applications such as vision and text classification tasks. Because the space of transformations can be quite large, choosing which transformations to apply during training can be quite expensive. In a paper that is published in ICML'20, we propose an uncertainty-based random sampling scheme which, among the transformed image samples, picks those with the largest losses. Our intuition is that these transformed samples that have the largest losses should also provide the most information. We show that our algorithm achieves state-of-the-art results on a wide variety of image classification benchmarks and model architectures.
Our algorithm involves the following three steps. In the first step, the users can provide a list of transformation functions such as rotation and mixup for the input. In the second step, we generate K random transformation sequences to produce K augmented training samples. In the third step, we select those transformed samples that have the highest losses, which is our surrogate for how much gain this transformed sample can provide to the model. If the loss of a transformed sample is large, then we perform a backprop using the sample. If it’s small, we discard it. As a remark, our idea is conceptually similar to Adversarial Autoaugment by Zhang et al. at ICLR'20. There, the authors propose an interesting adversarial network that generates augmented samples with large losses. By contrast, our algorithm does not require training such an adversarial network.
Experimental Results
CIFAR-10
| Model | Baseline | AutoAugment | Fast AutoAugment | PBA | RandAugment | Adv. AutoAugment | Ours | Link |
| Wide-ResNet-28-10 | 96.13 | 97.32 | 97.30 | 97.42 | 97.30 | 98.10 | 97.89 | Download |
| Shake-Shake (26 2x96d) | 97.14 | 98.01 | 98.00 | 97.97 | 98.00 | 98.15 | 98.27 | Download |
| PyramidNet+ShakeDrop | 97.33 | 98.52 | 98.30 | 98.54 | 98.50 | 98.64 | 98.66 | Download |
CIFAR-100
| Model | Baseline | AutoAugment | Fast AutoAugment | PBA | RandAugment | Adv. AutoAugment | Ours | Link |
| Wide-ResNet-28-10 | 81.20 | 82.91 | 82.70 | 83.27 | 83.30 | 84.51 | 84.54 | Download |
ImageNet
| Model | Baseline | AutoAugment | Fast AutoAugment | RandAugment | Adv. AutoAugment | Ours | Link |
| ResNet-50 | 76.31 | 77.63 | 77.60 | 77.60 | 79.40 | 79.14 | Coming soon |
IMDb
| Mixed VAT (Prev. SOTA) | BERT Large | UDA (BERT Large) | Ours | Link |
| 95.68 | 95.49 | 95.22 | 95.96 | Download |
Enlarging the number of augmented data points per training sample.
| Dataset | Model | Adv. AutoAugment | Ours | Link |
| CIFAR-10 | Wide-ResNet-28-10 | 98.10 | 98.16 | Download |
| CIFAR-100 | Wide-ResNet-28-10 | 84.51 | 85.02 | Download |
Getting started
To use our uncertainty-based random sampling scheme you will need to install the package, Dauphin, and any other Python dependencies by running the following command under Python 3.6 or above:
make devImage classification experiments
To run image classification, we provide a simple run_image.sh in the script folder and you just run the following command.
bash scripts/run_image.shThe default augment_policy is uncertainty_sampling which concatenates the composition of 2 randomly selected transformations and default transformations (i.e. randomly cropping, horizontal flipping, cutout, and mixup). We also provide a command-line interface for each parameter. For more detailed options, run image -h to see a list of all possible options.
Text classification experiments
To run text classification, we also provide a simple run_text.sh in the script folder and you just run the following command.
bash scripts/run_text.shThe default augment_policy is uncertainty_sampling which randomly selected one transformation (i.e. switchout, word replace, and back-translation). We also provide a command-line interface for each parameter. For more detailed options, run text -h to see a list of all possible options.
Using pre-trained models
To run our pretrained checkpoint, you only need to add another two arguments in the script and make sure you set the task and model properly.
--model_path [THE PATH TO THE MODEL FILE]
--train 0 # No training, only do inferenceSpecify your image augmentation [Optional]
We provide several transformations in Dauphin, here are some examples:
AutoContrast
Brightness
Color
Contrast
Cutout
Equalize
Invert
Mixup
Posterize
Rotate
Sharpness
ShearX
ShearY
Solarize
TranslateX
TranslateYFor each transformation, you can set the probability and magnitude of applying the transformation (i.e. AutoContrast_P{PROBABILITY}_L{MAGNITUDE}), otherwise they are all random. You can also composite different transformation by concatenating them with @ (i.e. AutoContrast@Color).
Reference
If you use this repository, please cite our paper titled as
On the Generalization Effects of Linear Transformations in Data Augmentation (blog):
@inproceedings{wu2020augmentation,
title={On the Generalization Effects of Linear Transformations in Data Augmentation},
author={Wu, Sen and Zhang, Hongyang R and Valiant, Gregory and R{\'e}, Christopher},
journal={International Conference on Machine Learning},
year={2020}
}
Acknowledgments
- Our framework is built on a multi-task learning package Emmental.
- Our code for image transformations is adapted from Fast AutoAugment and our code for text transformations is adapted from UDA. We thank the authors for providing their code online.