The goal of this repo is to provide an easy (click-and-go) way to deploy H2O Sparkling Water clusters on Microsoft Azure.
There are three kind of templates offered on this repo.
- Basic:
 - Everything in Basic template plus:
- Connection to additional data source (Linked Storage Account) - pre-requisite
- Connection to external Hive/Oozie Metastore (SQL Database) - pre-requisite
3. Advanced:
- Everything in Intermediate template plus:
- Connection to Azure Data Lake Store - pre-requisite
- Everything in Basic template plus:
- Connection to additional data source (Linked Storage Account) - pre-requisite
- Connection to external Hive/Oozie Metastore (SQL Database) - pre-requisite
3. Advanced:
- Everything in Intermediate template plus:
- Connection to Azure Data Lake Store - pre-requisite
It takes about 20 minutes to create the cluster.
NOTE: Passwords need to be between 12-72 characters long, it must contain at least 1 digit, 1 uppercase letter and 1 lowercase letter. Otherwise the deployment will fail!
Once your cluster is created, Open your browser and go to:
https://CLUSTERNAME.azurehdinsight.net/jupyter
Insert the username (hdiadmin by default) and password you set during cluster creation.
In Jupyter home, you will see a folder called "H2O-PySparkling-Examples" with a couple of notebooks you can run. Make sure that you set the right configuration on the first cell of the notebooks based on the VM sizes of your cluster nodes.

Azure HDInsight Spark Clusters (Spark on YARN) come with:
Head node (2), Worker node (1+), Zookeeper node (3) (Free for A1 Zookeepers VM size)
Defaults:
Number of Worker nodes: 3
Size of Head Nodes: D12 (28G RAM, 4 cores)
Size of Worker Nodes: D13 (56G RAM, 8 cores)
For a complete list of VM sizes go here
Hadoop supports a notion of the default file system. The default file system implies a default scheme and authority. It can also be used to resolve relative paths. During the HDInsight creation process, an Azure Storage account and a specific Azure Blob storage container from that account is designated as the default file system.
For the files on the default file system, you can use a relative path or an absolute path. For example, the hadoop-mapreduce-examples.jar file that comes with HDInsight clusters can be referred to by using one of the following:
wasbs://mycontainer@myaccount.blob.core.windows.net/example/jars/hadoop-mapreduce-examples.jar
wasbs:///example/jars/hadoop-mapreduce-examples.jar
/example/jars/hadoop-mapreduce-examples.jar
In addition to this storage account, you can add additional storage accounts (Intermediate and Advanced Templates) from the same Azure subscription or different Azure subscriptions during the creation process or after a cluster has been created. Note that the additional storage account must be in the same region than the HDI cluster. Normally this is where your big data resides and/or where you want to store your HIVE tables for future persistance (more on this later). The syntax is:
wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>
HDInsight provides also access to the distributed file system that is locally attached to the compute nodes (disks on the cluster nodes). You can use this as a local cache. Remember that this file system is gone once you delete the cluster. This file system can be accessed by using the fully qualified URI, for example:
hdfs://<namenodehost>/<path>
Most HDFS commands (for example, ls, copyFromLocal and mkdir) still work as expected. Only the commands that are specific to the native HDFS implementation (which is referred to as DFS), such as fschk and dfsadmin, will show different behavior in Azure Blob storage.
The cluster can also access any Blob storage containers that are configured with full public read access or public read access for blobs only.
Only the data on the linked storage account and the external hive meta-store (Azure SQL Database) will persist after the cluster is deleted.
The metastore contains Hive metadata, such as Hive table definitions, partitions, schemas, and columns. The metastore helps you to retain your Hive and Oozie metadata. If you are familiar with Databricks and their concept of Tables, then a custom Hive Metastore is the same thing: a persistent database to store Hive tables metadata. It is important to understand that the actual tables data is NOT in the SQL DB, but instead on the path defined in the variable hive.metastore.warehouse.dir which by default points to the default storage account/container under the path /hive/warehouse.
On the Basic Tamplate:
By default, Hive uses an embedded Azure SQL database to store this information. The embedded database can't preserve the metadata when the cluster is deleted. The Hive metastore that comes by default when HDInsight is deployed is transient. When the cluster is deleted, Hive metastore gets deleted as well.
On the Intermediate and Advanced Templates:
An external Azure SQL DB is linked to store the Hive metastore so that it persists even when the cluster is blown away. For example, if you create Hive tables in a cluster created with an external Hive metastore, you can see those tables if you delete and re-create the cluster with the same Hive metastore. IMPORTANT: make sure that you set the location of those tables on your external/linked storage account, you can do this by calling the EXTERNAL and LOCATION clauses on your SQL CREATE statement , for example:
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
STORED AS PARQUET
LOCATION 'wasb://<containername>@<accountname>.blob.core.windows.net/<path>'
On the above example, the table is stored NOT on the default storage account, but instead on the Linked storaged account. Both, the Hive Metastore, on a external SQL DB, and the query with EXTERNAL and LOCATION, are necessary in order to make the tables to persist after the cluster is deleted.
For more information on HIVE Data Definition Language, click here
When you're creating a custom metastore, do not use a database name that contains dashes or hyphens because this can cause the cluster creation process to fail.

All templates will automatically download the latest version of Sparkling Water compatible with Spark 1.6. It will also copy the sparkling water folder on the default storage under /H2O-Sparkling-Water/ folder.
H2O can be installed as a standalone cluster, on top of YARN, and on top of Spark on top of YARN. All three templates introduced in this repo install H2O on top of Spark on top of YARN => Sparkling Water on YARN.
Note that all spark applications deployed using a Jupyter Notebook will have "yarn-cluster" deploy-mode. This means that the spark driver node will be allocated on any worker node of the cluster, NOT on the head nodes.
Another very important note: Memory and Cores allocation in YARN.
The process of smart RAM and CPU allocation in Spark over YARN is truly an art. By default, the notebook examples in this repo allocate 70%-80% of the workers node RAM and 1 executor per worker node, every time you run the notebook.
This means:
- You cannot run more than one application (notebook) in the cluster at a time. Why? the notebook is fixing all cluster resources to that application.
- If you want to run multiple notebooks/applications in the cluster at the same time, it is highly recommended to turn on dynamic allocation (spark.dynamicAllocation.enabled), and remove the fixed parameters at the spark conf cell.
- Wrong memory/executor/cores configuration will cause YARN to: kill the application or allocate less executors to Sparkling Water (Spark application)
For a good read about spark parameter tuning, please check this link: http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
All three templates have to be manually tweeked in the azure portal in order to allow http access to the VM where the spark driver falls (the only VM that provides the FLOW portal). Note: the spark driver can change to any worker node each time you open/run a notebook (submit application).
This is what you need to do:
In the notebook, once you create the h2o context, you will see an output like this:

-
Write down or memorize the IP address and port of the "H2O connection URL".
-
Now open the azure portal -> open the resource group of the cluster you created -> click on the VNET and memorize what worker node has the IP on step 1.
-
Now go back to the resource group list of resources and select the "ClusterFlowIP" resource -> Click on "Associate".
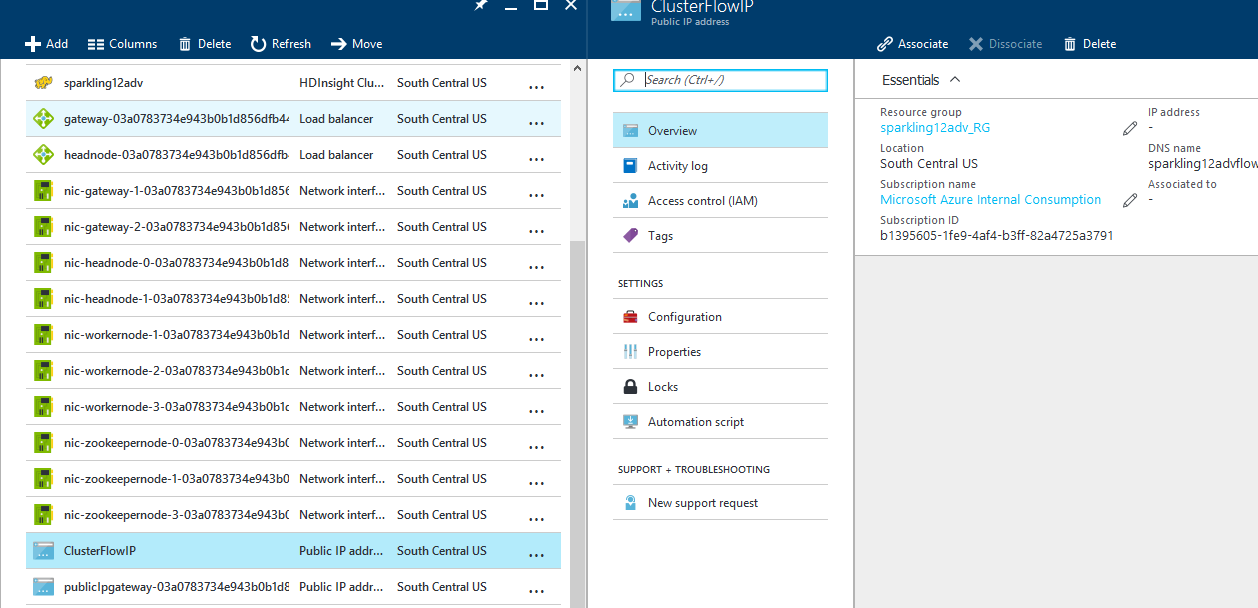
-
On the "Associate" blade select Resource type: Network Interface -> then select from the list the NIC of the worker node on step 2 -> click OK.
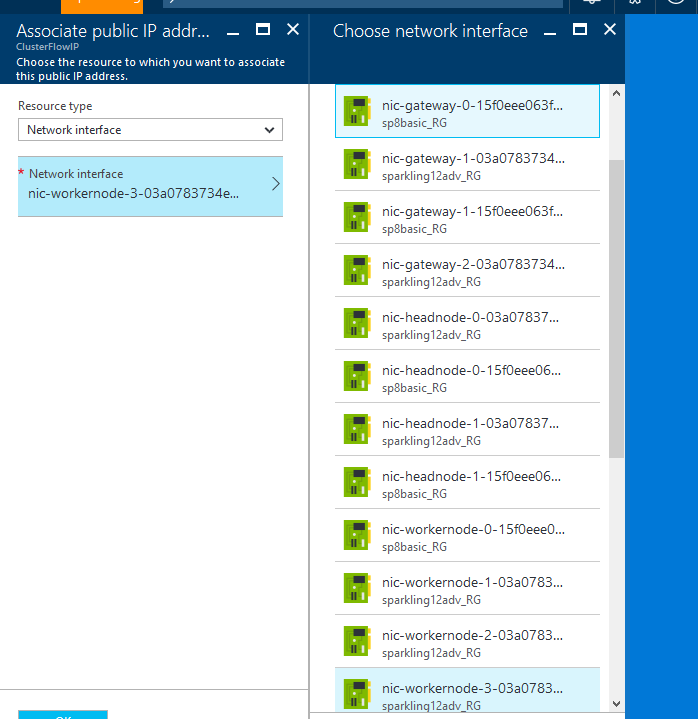
-
Refresh the "ClusterFlowIP" resource blade and copy the IP address under "Essentials".
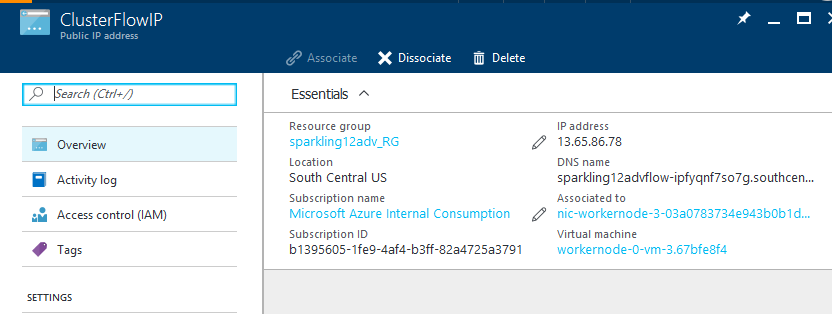
-
On your browser open: http://[publicIP]:port and you will see the FLOW UI



HDInsight Spark clusters provide two kernels that you can use with the Jupyter notebook. These are:
- PySpark (for applications written in Python)
- Spark (for applications written in Scala)
Couple of key benefits of using the PySpark kernel are:
- You do not need to set the contexts for Spark and Hive. These are automatically set for you.
- You can use cell magics, such as
%%sql, to directly run your SQL or Hive queries, without any preceding code snippets. - The output for the SQL or Hive queries is automatically visualized.
-
From the Azure Portal, from the startboard, click the tile for your Spark cluster (if you pinned it to the startboard). You can also navigate to your cluster under Browse All > HDInsight Clusters.
-
From the Spark cluster blade, click Quick Links, and then from the Cluster Dashboard blade, click Jupyter Notebook. If prompted, enter the admin credentials for the cluster.
you may also reach the Jupyter Notebook for your cluster by opening the following URL in your browser. Replace CLUSTERNAME with the name of your cluster:
https://CLUSTERNAME.azurehdinsight.net/jupyter
Jupyter notebooks are saved to the storage account associated with the cluster under the /HdiNotebooks folder. Notebooks, text files, and folders that you create from within Jupyter will be accessible from WASB. For example, if you use Jupyter to create a folder myfolder and a notebook myfolder/mynotebook.ipynb, you can access that notebook at wasbs:///HdiNotebooks/myfolder/mynotebook.ipynb. The reverse is also true, that is, if you upload a notebook directly to your storage account at /HdiNotebooks/mynotebook1.ipynb, the notebook will be visible from Jupyter as well.
The way notebooks are saved to the storage account is compatible with HDFS. So, if you SSH into the cluster you can use file management commands like the following:
hdfs dfs -ls /HdiNotebooks # List everything at the root directory – everything in this directory is visible to Jupyter from the home page
hdfs dfs –copyToLocal /HdiNotebooks # Download the contents of the HdiNotebooks folder
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks # Upload a notebook example.ipynb to the root folder so it’s visible from Jupyter
To delete the Sparkling Water Cluster, go to the Azure portal and delete the Resource Group.

Spark in HDInsight includes the following components that are available on the clusters by default.
- Spark Core. Includes Spark Core, Spark SQL, Spark streaming APIs, GraphX, and MLlib.
- Anaconda
- Livy
- Jupyter Notebook
Spark in HDInsight also provides an ODBC driver for connectivity to Spark clusters in HDInsight from BI tools such as Microsoft Power BI and Tableau.