Visualize EPICS Archiver Appliance on Grafana.
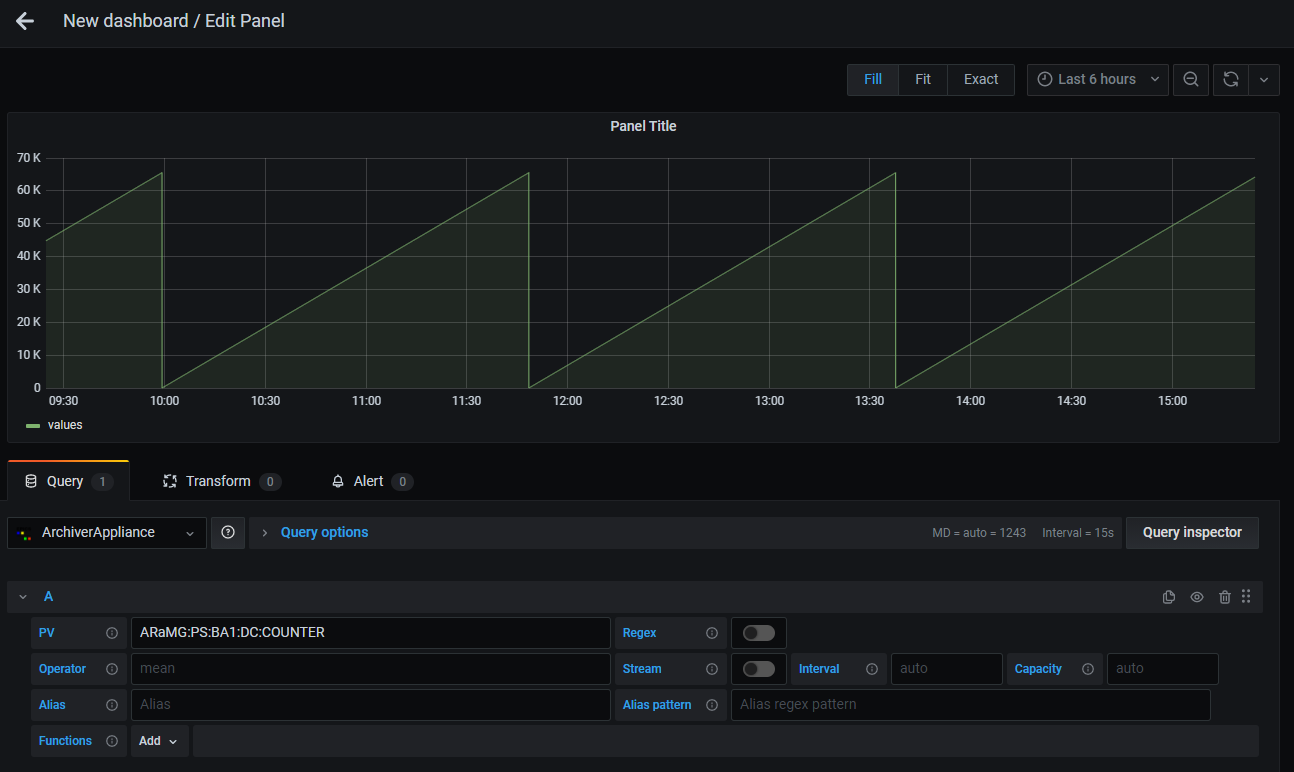
See Archiver Appliance site for more information about Archiver Appliance.
- Select multiple PVs by using Regex (Only supports wildcard pattern like
PV.*and alternation pattern likePV(1|2)) - Legend alias with regular expression pattern
- Data retrieval with data processing (See Archiver Appliance User Guide for processing of data)
- Using PV names for Grafana variables
- Transform your data with processing functions
- Live update with stream feature
- Find and notify problems with alerting feature
- Install the plugin with Grafana CLI. Execute Grafana CLI as following:
# Install latest version. You can also use this command to update the plugin to the latest version.
grafana-cli --pluginUrl https://github.com/sasaki77/archiverappliance-datasource/releases/latest/download/archiverappliance-datasource.zip plugins install sasaki77-archiverappliance-datasource
# Install particular version. This example will install v1.4.2.
grafana-cli --pluginUrl https://github.com/sasaki77/archiverappliance-datasource/releases/download/1.4.2/archiverappliance-datasource.zip plugins install sasaki77-archiverappliance-datasource
# Install nightly builds.
grafana-cli --pluginUrl https://github.com/sasaki77/archiverappliance-datasource/releases/download/nightly/archiverappliance-datasource.zip plugins install sasaki77-archiverappliance-datasource- This plugin is unsigned. It must be specially listed by name in the Grafana
grafana.inifile to allow Grafana to use it. Addsasaki77-archiverappliance-datasourceto theallow_loading_unsigned_pluginsparameter in the[plugins]section. See Configure Grafana | Grafana documentation for more detail ongrafana.ini.
To update the plugin, execute Grafana CLI again.
Clone this plugin into grafana plugins directory; the default is /var/lib/grafana/plugins.
Please consult [https://sasaki77.github.io/archiverappliance-datasource/configuration.html] for instructions to configure the plugin following installation.
Documentation is available at https://sasaki77.github.io/archiverappliance-datasource.
This section lists the available configuration options for the Archiver Appliance data source.
| Configuration | Description |
|---|---|
| PV | Set PV name to be visualized. It is allowed to set multiple PVs by using Regular Expressoins alternation pattern (e.g. (PV:1|PV:2)). |
| Regex | Enable/disable Regex mode. Refer Select Multiple PVs by Regex. |
| Operator | Controls processing of data during data retrieval (Default: mean). Refer Archiver Appliance User Guide about processing of data. Special operator raw and last are also available. raw allows to retrieve the data without processing. last allows to retrieve the last data in the specified time range. |
| Stream | Enable/Disable Stream mode. Stream allows to periodically update the data without refreshing the dashboard. The difference data from the last updated values is only retrieved. |
| Interval | Streaming interval in milliseconds. You can also use a number with unit. e.g. 1s, 1m, 1h. The default is determined by a width of panel and time range. |
| Capacity | The stream data is stored in a circular buffer. Capacity determines the buffer size. The default is detemined by a initial data size. |
| Alias | Set alias for legend. |
| Alias pattern | Set regular expressoin pattern to use PV name for legend alias. Refer Legend Alias with Regex Pattern |
| Function | Apply processing function for retrieved data. Refer Apply Processing Functions |
Variables are supported for PV names registered in Archiver Appliance.
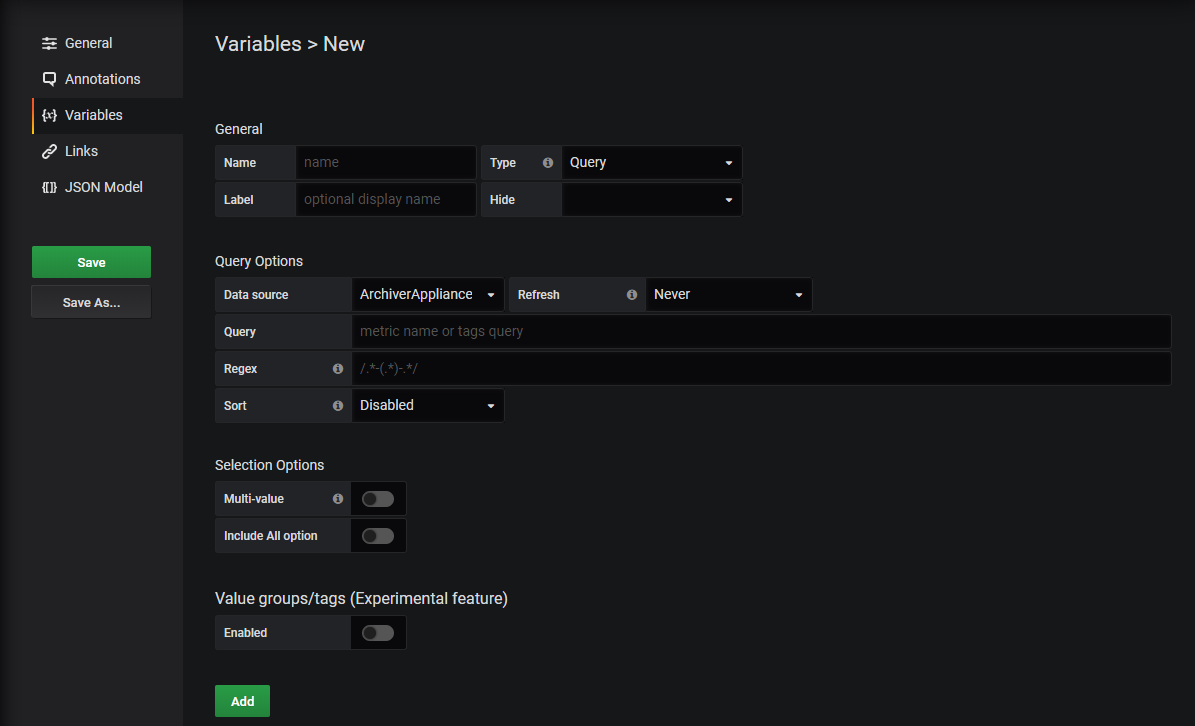
You can use regular expression pattern same as Query Edit. Only wildcard pattern and alternation pattern are available.
You can also use another variable as a part of query. For example, you have variable group, which is a list of PV name prefixes according to PV naming rules on your institute.
Below is a query in this case.
${group}:.*Default maximum number of PV names you can use in variables is 100. Limit parameter is available to change maxmum number. Parameters must be follow ? character.
PV:NAME:.*?limit=1000This data source plugin consists of both frontend and backend components.
Node version v12.x is recommended. If you're new to the Node.js ecosystem, Node Version Manager is a good place to start for managing different Node.js installations and environments.
grafana-toolkit is used to develop the plugin. Please refer grafana-toolkit documentation for more information.
- Begin by installing Yarn (https://yarnpkg.com/)
npm install -g yarn- Install dependencies
yarn install- Build plugin in development mode or run in watch mode
yarn devor
yarn watch- Build plugin in production mode
yarn buildIf the Mage build tool is not already installed, you may install it using the installation instructions on the Mage homepage
- Update Grafana plugin SDK for Go dependency to the latest minor version:
go get -u github.com/grafana/grafana-plugin-sdk-go- Build backend plugin binaries for Linux, Windows and Darwin:
mage -v- List all available Mage targets for additional commands:
mage -lThanks to pklaus / docker-archiver-appliance and pklaus / archiver-appliance-with-example-ioc, the test environment is available with Docker Compose.
docker-compose upThe following containers are runinng after docker-compse up.
| Name | Description |
|---|---|
| grafana | Runs a Grafana server. |
| archappl | Runs a EPICS Archiver Appliance. |
| redis | Runs a datastore for the persistance of the appliance configuration. |
| example | Runs a example EPICS IOC to be archived. |
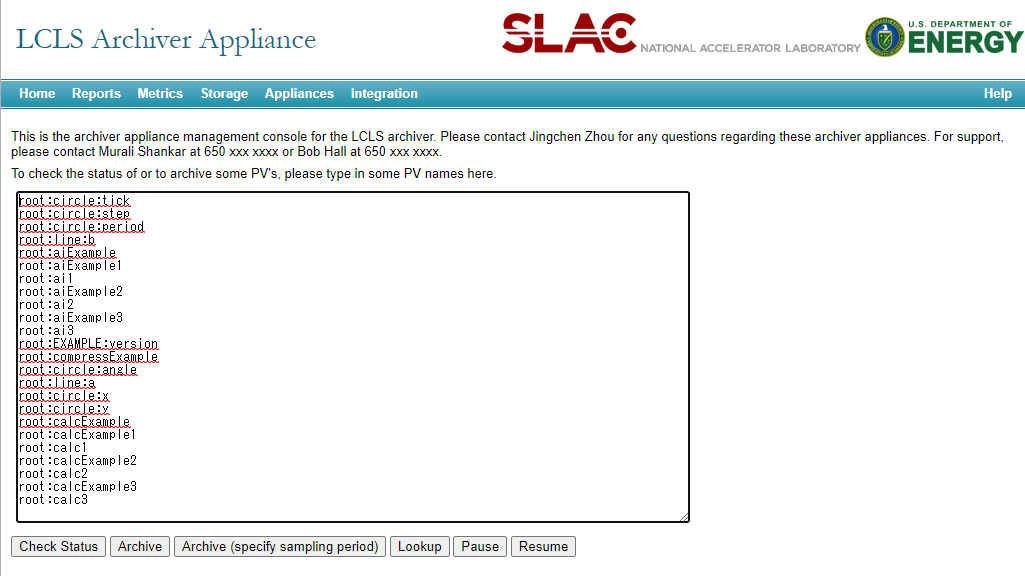
To set up the Archiver Appliance, open http://localhost:17665/mgmt/ui/index.html. You can add the PVs served by the example IOC on this page.
Enter the following lines in the input field and then clicking the Archive button.
the Archive will be start a few minuites later.
root:circle:tick
root:circle:step
root:circle:period
root:line:b
root:aiExample
root:aiExample1
root:ai1
root:aiExample2
root:ai2
root:aiExample3
root:ai3
root:EXAMPLE:version
root:compressExample
root:circle:angle
root:line:a
root:circle:x
root:circle:y
root:calcExample
root:calcExample1
root:calc1
root:calcExample2
root:calc2
root:calcExample3
root:calc3
To add a data source, open Grafana (http://localhost:3000). On the data sources page, add a data source and set URL as http://archappl:17665/retrieval.
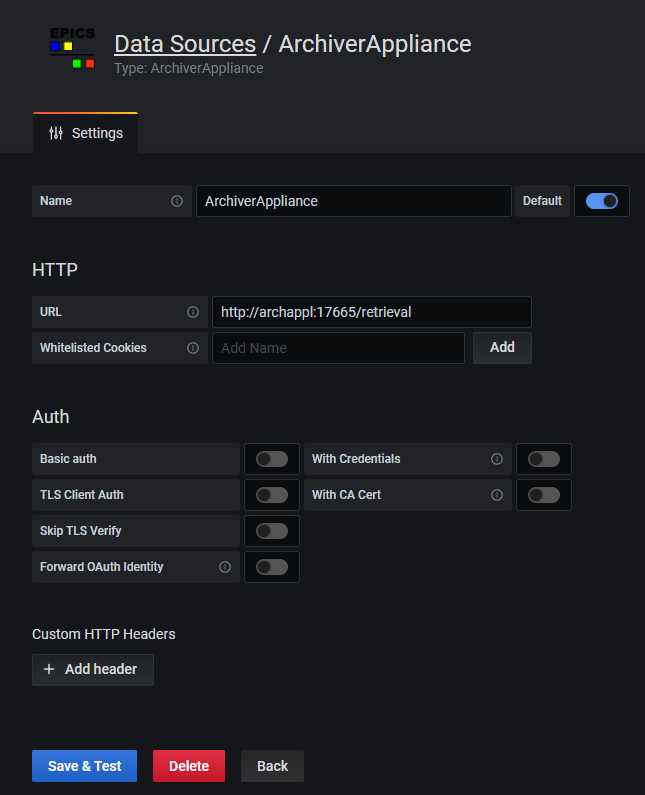
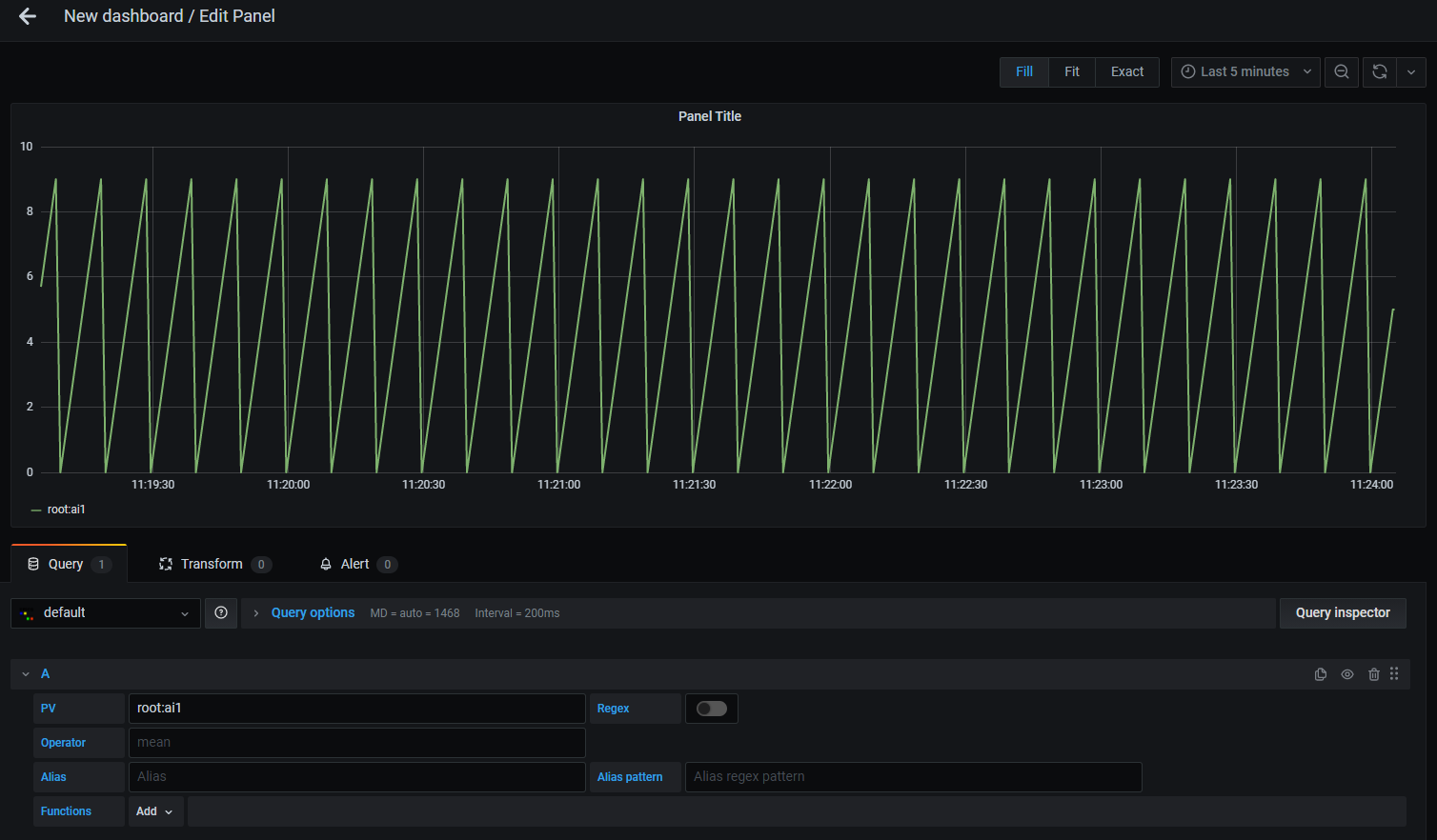
The following is a example query with this test environment.
python -m venv env
source env/bin/activate
pip install sphinx myst-parser sphinx_rtd_theme
make html
| Build: | Status: |
|---|---|
| Latest release | |
| Master Branch | |
| Local Master Branch | |
| Local Latest Branch |