This project is comprised of 2 parts: A scrap/NLP pipeline and a web application to show results. The main motivation is to make easy to analyse scientific publications from different prestigious sources (scientific journals and websites) on a very novel topic: COVID-19 We then can show results on a website so any user can browse through results and find articles using keywords and other properties.
The first part of the project is an ETL/Scrap pipeline built using Kedro, a python tool for creating simple pipelines. It scraps covid-19 related Scientific papers and publications from different EMEA and worldwide sources/Journals, like:
- Lancet
- EMA
- ELSEVIER
- NEJM
- UPTODATE
- NATURE
- PUBMED
The pipeline has different nodes that:
- Scraps websites using Beautifulsoup or API calls.
- Creates Pandas Dataframes with article details.
- Runs several NLP processes (Tokenization, Lemmatization, Sentiment, etc) .
- Stores results in a SQLite DB to be used by the flask app on the dashboard website.
Dependencies are declared in src/requirements.txt for pip installation and src/environment.yml for conda installation.
To install them, run:
kedro install
You can run the Kedro project (Pipeline) with:
kedro run
To get an idea of the structure of the dataset that's created on the pipeline, you can look at: Primary Dataset
The SQLite DB that's used on the Flask visualizer is here: articles.db
Scrap details can be seen on the scrap nodes here:
https://github.com/sansagara/ipvu_trends_dashboard/blob/master/scrap/src/ipvu_scrapper/scrap/nodes.py
Some nodes are scraped using beautifulsoup, while others like elsevier are accessed through a REST API.
NLP processing can be seen on the process nodes here: https://github.com/sansagara/ipvu_trends_dashboard/blob/master/scrap/src/ipvu_scrapper/process/nodes.py
Keywords, Stopwords and Stems for this project are all listed on the parameters file: Parameters.yml
This is a Flask application that displays a dashboard (Like the one on the Flask lesson) It shows several charts and tables with different information like keyword frequency, sentiment, etc.
To install the flask app, you need:
- python3
- python packages in the requirements.txt file
Install the packages with
pip install -r requirements.txt
On a MacOS/linux system, installation is easy.
Open a terminal, and go into the directory with the flask app files.
Run python visualize/myapp.py in the terminal.
Be sure to see my demo video on YouTube! Video Walkthrough
The flask application portion is deployed on Heroku for easy demoing purposes: App on Heroku
Results can be seen directly on the App on Heroku or on the Video Walkthrough. Following is a reflection on how the results can be checked on the dashboard itself
As a mean to validate/see the results, several visualizations and charts are provided. Here's some explanation:
-
An Histogram that shows the evolution of the different keywords. We can check manually the occurrence of them on the datasets.
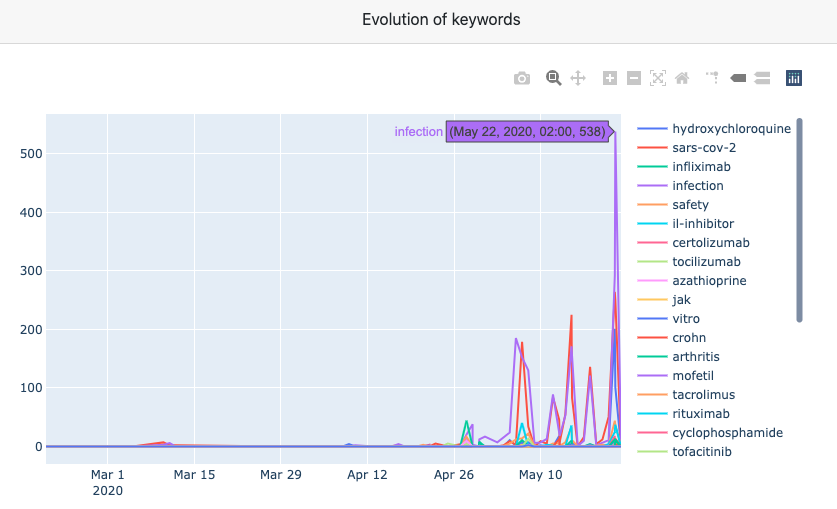
-
An LDA Topic model is retrained every time to detect topics on all articles scraped
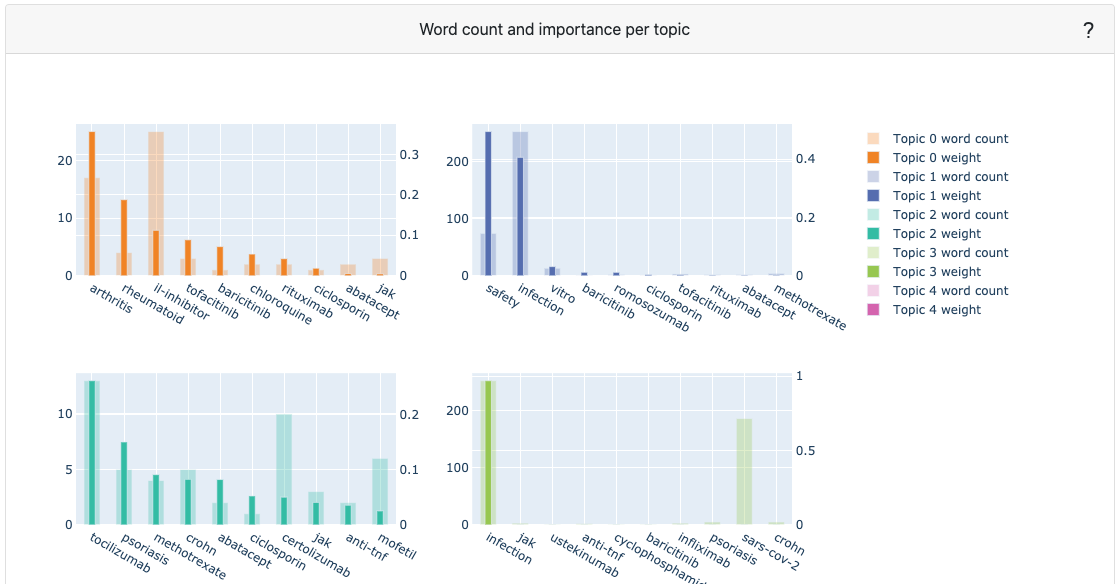
-
A wordcloud visualizes the top words occuring in the title and abstract of the article, whereby words which are more present are larger.
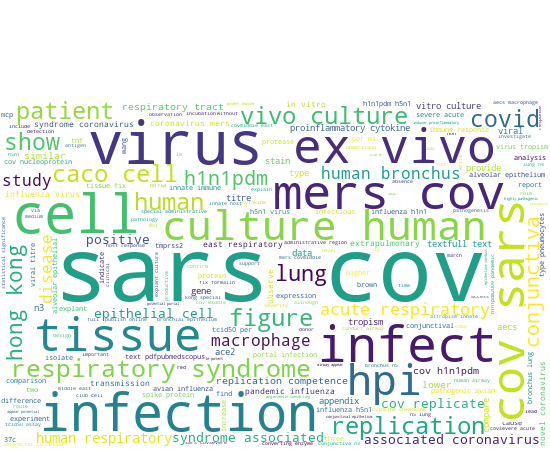
-
A violin/boxplot chart of all article abstract available. A violin plot shows the distribution of article sentiments, while a boxplot visualizes how the quartiles and average are distributed. In gold, the current article's sentiment is visualized relative to all other articles. The extent to which an article abstract is positive, negative or neutral is determined by the words used (e.g. great vs. good) and punctuation (e.g. !).
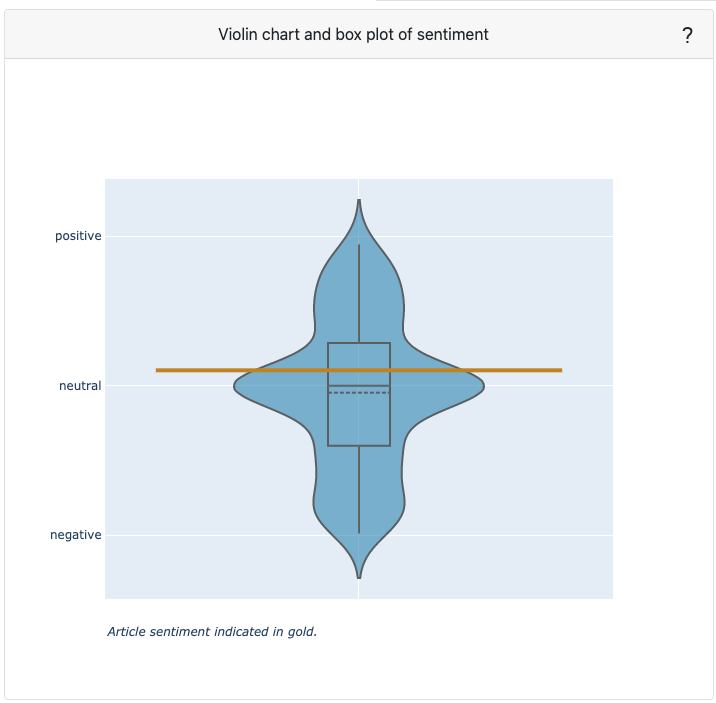




LDA training with Gensim is done each time a request is made. The code can be seen on: LDA code
A case was made with a project that allows for simple, efficient exploration of the environment related to the topics of Covid-19 in the Pharma and Health landscape. The results can then suggest publications for manual review to a team interested on a certain topic, sentiment or keyword.
- Scrap additional journals/sources.
- Use the content field with a pre-trained BERT model to recognize topics linked to the universe of interest.
- Train a ML model for Sentiment Analysis and Topic Detection that can learn and adapt whenever new batches of data.
- Customize the topics for Topic Analysis according to some business or research rules.
- Apply `A/B testing between Sources to check for bias or trends.
