This repository is a PyTorch implementation of the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" by Alexey Dosovitskiy et al. The paper introduces a new architecture called Vision Transformer (ViT) that applies the transformer to image recognition. The model achieves competitive results on ImageNet and other image recognition benchmarks while being more data-efficient.
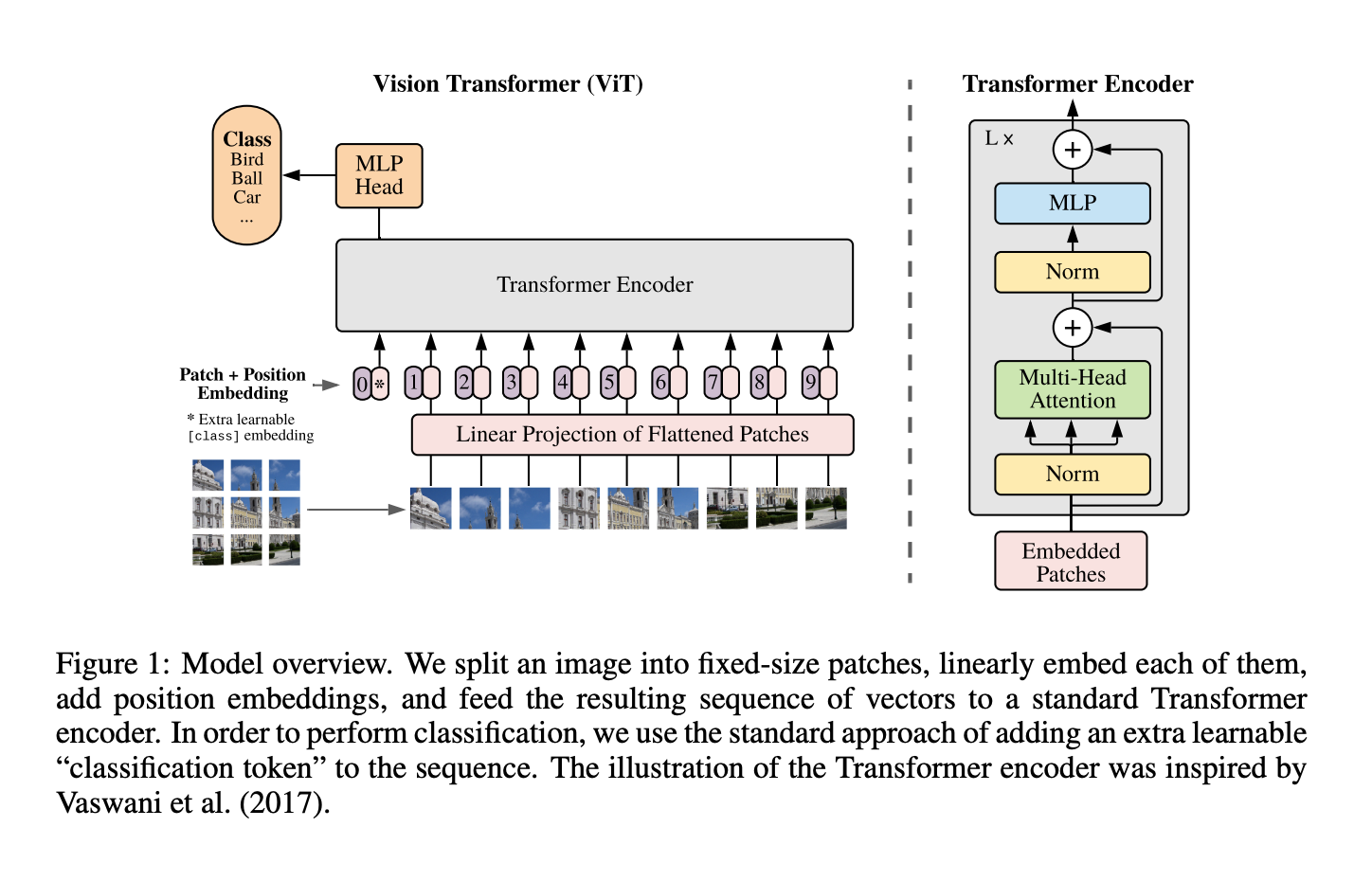
The model architecture is shown below. The input image is divided into fixed-size non-overlapping patches, which are then linearly embedded. The resulting sequence of embeddings is processed by a transformer encoder, which outputs a sequence of embeddings. The first token of the output sequence is used as the representation of the image, which is then passed through a feedforward network to produce the final output.
The link to the paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale