- Set up the Kafka cluster with monitoring tools in the form of Docker compose.
- Collect the house transation data as an event and send to Kafka topic.
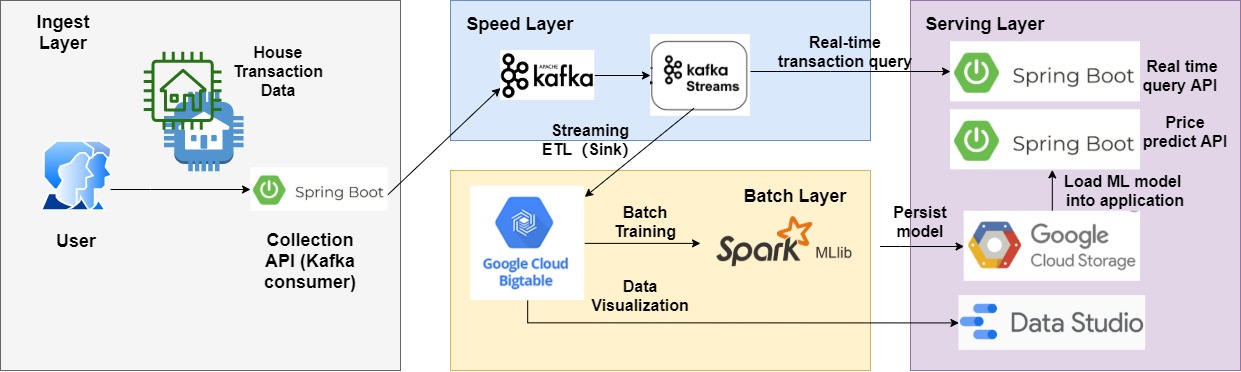
2. Speed Layer
- Kafka producer & consumer.
- Streaming ETL that will sink to Big Query.
- Materialize the KTable of count based on the tumbling timewindow.
3. Batch Layer
- Train the Regression Model by machine learning API provided by Spark MLlib and persist into GCS.
- Use metrics to evaluate the performance of each Model.
- Load the ML model inside SpringBoot application to provide prediction function.
- Provide interactive query based on Kafka Timewindow Streaming.
- Integrate the Neural Network to solve regression problem by using deeplearning4j.
- Use Flink & Alink to achieve the unified online & offline machine learning, since the Spark MLlib only provide the streaming linear regression model for the regression problem.
- Embed the pre-processing and feature engineering into pipeline and make them automatically.