| 4:00pm-4:30pm | Arrive |
| 4:30pm-5:00pm | Project pitches |
| 5:00pm-5:30pm | Teams form |
| 5:30pm-9:00pm | Hacking |
| 9:00pm-9:45pm | Project presentations |
| 10:00pm | Prize announcements |

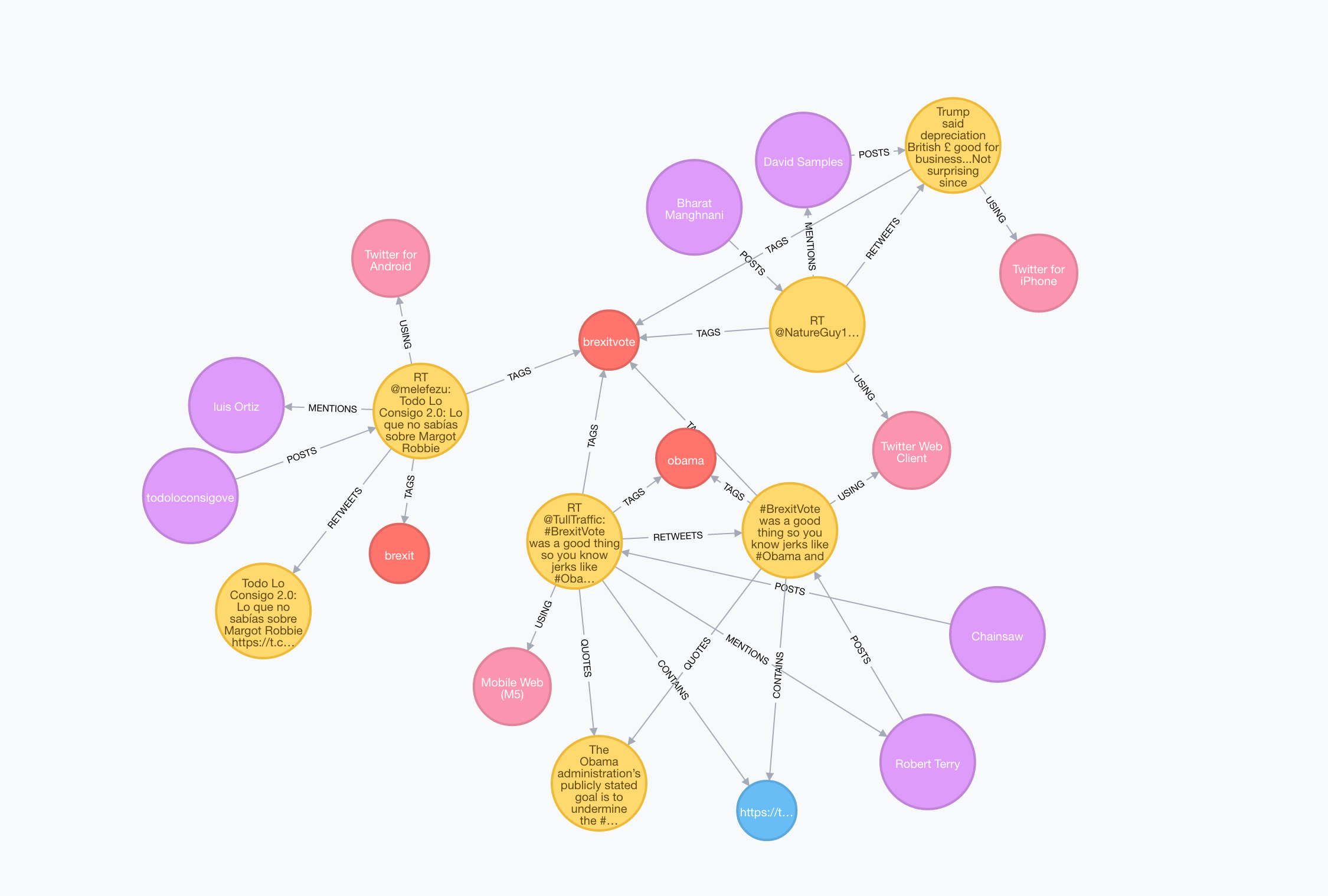
NOTE: This dataset has an interactive Neo4j Browser guide for exploring the data:


Download
wget http://demo.neo4j.com.s3.amazonaws.com/electionTwitter/neo4j-election-twitter-demo.tar.gz
tar -xvzf neo4j-election-twitter-demo.tar.gz
cd neo4j-enterprise-3.0.3
bin/neo4j start
NOTE: This dataset has an interactive Neo4j Browser guide for exploring the data:

Fivethirtyeight has made the data behind their famous election forecast publicly available:
http://projects.fivethirtyeight.com/2016-election-forecast/summary.json
You can easily pull this into Neo4j using apoc.load.json:
CALL apoc.load.json("http://projects.fivethirtyeight.com/2016-election-forecast/summary.json") YIELD value AS data
RETURN data
// Creating the graph
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://s3-us-west-2.amazonaws.com/neo4j-datasets-public/Emails-refined.csv" AS line
MERGE (fr:Person {alias: COALESCE(line.MetadataFrom, line.ExtractedFrom,'')})
MERGE (to:Person {alias: COALESCE(line.MetadataTo, line.ExtractedTo, '')})
MERGE (em:Email { id: line.Id })
ON CREATE SET em.foia_doc=line.DocNumber, em.subject=line.MetadataSubject, em.to=line.MetadataTo, em.from=line.MetadataFrom, em.text=line.RawText, em.ex_to=line.ExtractedTo, em.ex_from=line.ExtractedFrom
MERGE (to)<-[:TO]-(em)-[:FROM]->(fr)
MERGE (fr)-[r:HAS_EMAILED]->(to)
ON CREATE SET r.count = 1
ON MATCH SET r.count = r.count + 1;
// Updating counts
MATCH (a:Person)-[r]-(b:Email) WITH a, count(r) as count SET a.count = count;

The Fivethirtyeight teams does an amazing job of providing the data behind many of their stories in their Github repo. There are a lot of possibilities but here are a few ideas we hacked up:
Import
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/fivethirtyeight/data/master/hip-hop-candidate-lyrics/genius_hip_hop_lyrics.csv" AS row
MERGE (c:Candidate {name: row.candidate})
MERGE (a:Artist {name: row.artist})
MERGE (s:Sentiment {type: row.sentiment})
MERGE (t:Theme {type: row.theme})
MERGE (song:Song {name: row.song})
MERGE (line:Line {text: row.line})
SET line.url = row.url
MERGE (line)-[:MENTIONS]->(c)
MERGE (line)-[:HAS_THEME]->(t)
MERGE (line)-[:HAS_SENTIMENT]->(s)
MERGE (song)-[:HAS_LINE]->(line)
MERGE (a)-[r:PERFORMS]->(song)
SET r.data = row.album_release_date


Beyond the resources listed above.
We don't have Neo4j import scripts or graph exports for these, but we think they might be interesting to explore:
- Deep and interesting datasets for computational journalism
- US Government's open data
- NASA's Data Portal
- US City Data
- US Spending data
You'll need to use Neo4j to participate in the hackathon. You can download Neo4j here or use one of the hosted versions above.
Graph algorithms, data import, job scheduling, full text search, geospatial, ...
Grab your friendly Neo4j staff and community members if you have any questions.