SofAR Obstacle detection project
Team
- Ruslan Aminev
- Luigi Secondo
Project plan
- Find datasets
- Evaluate datasets, select feasible ones
- Choose detection algorithm (DNN architecture)
- Prepare labels according to chosen algorithm
- Develop training pipeline and train neural network
- Integrate algorithm in ROS
1. Find datasets
Suitable dataset should contain images or image sequences of scenes, where different number of persons could be present. Labels should determine position of the person on the image in terms of the bounding box (or should be convertible to bounding box).
Datasets with pedestrians:
-
KITTI
Among lot of various road environment datasets there is one which is useful for our problem:
- Dataset for detection with 8 classes (Car, Van, Truck, Pedestrian, Person_sitting, Cyclist, Tram, Misc).
-
Cityscapes
Road scene segmentation dataset. Labels are provided as masks for classes of objects and object`s instances.
-
Daimler
There are road environment datasets for different problems:
- Pedestrian segmentation
- Pedestrian path prediction (stopping, crossing, bending in, starting)
- Stereo pedestrian detection
- Mono pedestrian detection (this should be taken)
- Mono pedestrian classification
- Cyclists detection
-
Caltech
The Caltech Pedestrian Dataset consists of approximately 10 hours of 640x480 30Hz video taken from a vehicle driving through regular traffic in an urban environment. About 250,000 frames (in 137 approximately minute long segments) with a total of 350,000 bounding boxes and 2300 unique pedestrians were annotated.
-
MOT17 (Multiple Object Tracking Benchmark)
Dataset for multiple object tracking mostly related to pedestrian tracking.
-
KAIST
The KAIST Multispectral Pedestrian Dataset consists of 95k color-thermal pairs (640x480, 20Hz) taken from a vehicle. All the pairs are manually annotated (person, people, cyclist) for the total of 103,128 dense annotations and 1,182 unique pedestrians. The annotation includes temporal correspondence between bounding boxes like Caltech Pedestrian Dataset.
-
Oxford RobotCar Dataset
Dataset was collected in over 1000 km of recordered driving in all weather conditions. There are almost 20 million images of the same road from 6 cameras.
2. Evaluation of datasets
With a first "human" evaluation we concluded that:
- KITTI is not very large but could be useful, so we evaluate it.
- Cityscapes is a segmentation dataset and it'll require a lot of work to convert segmentation labels to bounding boxes for detection, so we have decided to drop it.
- Daimler has only black & white pictures, so we have decided to drop it.
- Caltech was created specifically for our problem and has a lot of images, so we evaluate it.
- MOT-17 was also created for pedestrians detection, so we evaluate it.
- KAIST is compatible with Caltech in terms of labels and has a lot of images, so we evaluate it.
- Oxford is too big to be evaluated with our personal machines so we have decided to drop it
For a more detailed report for each evaluated dataset (1, 4, 5, 6)
check data-eval/README.md report.
3. Choose detection algorithm
There are several well known object detection approaches which use CNN as their main part: Fast RCNN, Faster RCNN, SSD, YOLO, and others.
For our problem we selected YOLO (there also exists the second version) as it has ability to simultaneously detect (in one pass) and classify object in image. SSD architecture also has this property, but choice of YOLO was also dictated by presence of really light version of architecture "Tiny YOLO". It should be able to perform in real time pace on low grade hardware like mobile versions of NVIDIA GPUs in laptops or NVIDIA Jetson TX modules. However, Tiny YOLO has worse accuracy than full size network.
Authors of YOLO provide their implementation in pure C and CUDA called Darknet. It requires compilation from source and presence of CUDA Toolkit. According to requirements of the project we have to use TensorFlow so we looked on the internet and found Python3 implementation Darkflow, which allows to easily use YOLO in TensorFlow. It allows to try architecture without CUDA Toolkit using only CPU version of TensorFlow, however it requires installation which includes compilation of some Cython functions which are required for YOLO to make it faster.
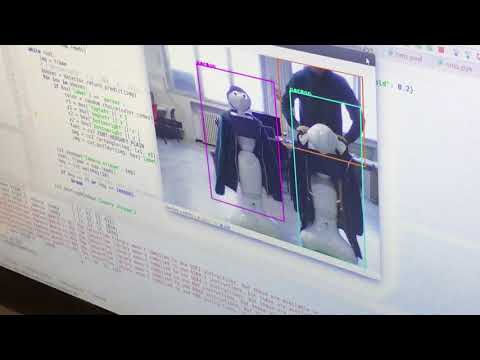
We are able to run existing detectors for several classes,
which are trained on VOC
or COCO datasets with "person" class
among others (see detection/cam_inference.py and
detection/img_inference.py). To perform this darkflow is used
according the instructions in it's repository.
4. Prepare labels
Darkflow is said to be TensorFlow implementation of Darknet, however it's internal label parsing tools for training are not designed according to Darknet conventions, which are described on Darknet website.
So to use Darkflow for training with your own dataset it's required to change some code to use labels formatted according to Darknet well defined rules. In our case a patch was written.
The whole process is described in more details in detection/README.md.
5. Training
If the dataset and network configuration are prepared properly, training
is easy, one just have to use Darkflow command to do it:
flow --model cfg/tiny-yolo-voc-3c.cfg --load bin/tiny-yolo-voc.weights --train --annotation train/Annotations --dataset train/Images
For more details also look in detection/README.md.
Unfortunately there were no proper hardware available for training, but there are some possibilities to use online services:
- Amazon Web Services (some credits are available via GitHub Student Developer Pack).
- Google Cloud Platform with 300$ free credits.
- Google Colaboratory with totally free access to machines with NVIDIA Tesla K80 13Gb.
However understanding and configuration of this tools require a lot of time compared with straightforward training using local machine. So for now we don't provide our trained neural network specifically for the problem of pedestrian detection, but developed workflow allows to easily do this.
6. Inference and integration in ROS
Inference via Darkflow is described in detection/README.md. However to use
detection in ROS we had to adapt some things for Python2, details are also
provided in detection/README.md. We ended with our own Python2 package
"objdet" which uses TensorFlow and some postprocessing functions adapted
from Darkflow. The script detection/pure_tf_cam.py provides example of
using this package.
In order to run detection in ROS environment we create a ROS Detection node which is able to read images from any appropriate topic. It runs detection and publishes results in ROS via custom message format to make them available for other nodes.

To use OpenCV for image related operations we have to convert them to OpenCV format using CvBridge which is a ROS library with required functions.
Details of the ROS integration phase is available in pedect-ws/README.md
Video demo
Conclusion
To conclude we could say that almost all items of plan have been done except of training on our own dataset.
Two things were most difficult in this project:
- understanding the YOLO architecture and Darkflow framework,
- integrating detection in ROS.
During our project development we learned that there are things to do in a better way:
- check compatability of libraries (really bad time trying to use Python3 with ROS),
- look for available architectures before evaluating datasets (this could save time for dataset preparation).