Generating video descriptions using deep learning in Keras
Start with AWS Ubuntu Deep Learning AMI on a EC2 p2.xlarge instance. (or better, p2.xlarge costs $0.9/hour on-demand and ~$0.3/hour as a spot instance)
source activate tensorflow_p27
conda install scikit-learn
conda install scikit-imageIf you are not using AWS, ensure you have a recent version of Keras and Tensorflow installed and working, and also install scikit-learn and scikit-image if you want to train tag prediction models
git clone https://github.com/rohit-gupta/V2L-MSVD.git
cd V2L-MSVDbash fetch-pretrained-model.sh
sudo bash install-youtube-dl.sh
bash fetch-youtube-video.sh https://www.youtube.com/watch?v=cKWuNQAy2Sk
bash process-youtube-video.sh bash fetch-pretrained-model.sh
bash fetch-from-localpath.sh /home/ubuntu/vid1.mp4
bash process-youtube-video.sh bash fetch-data.shIf you only want to use Verified descriptions ->
bash preprocess-data.sh CleanOnly If you want to use both verified and unverified descriptions ->
bash preprocess-data.shbash extract_frames.shbash run-feature-extractor.shbash train-simple-tag-prediction-model.shbash train-language-model.shbash score-language-model.sh- If at any stage you get an error that contains
/lib/libstdc++.so.6: version `CXXABI_1.3.x' not foundYou can fix it with:
cd ~/anaconda3/envs/tensorflow_p27/lib && mv libstdc++.a stdcpp_bkp && mv libstdc++.so stdcpp_bkp && mv libstdc++.so.6 stdcpp_bkp && mv libstdc++.so.6.0.19 stdcpp_bkp/ && mv libstdc++.so.6.0.19-gdb.py stdcpp_bkp/ && mv libstdc++.so.6.0.21 stdcpp_bkp/ && mv libstdc++.so.6.0.24 stdcpp_bkp/ && cd -- Tensorflow 1.3 has a memory leak bug that might affect this code
You can fix it by upgrading Tensorflow.
Reference for this problem: #3
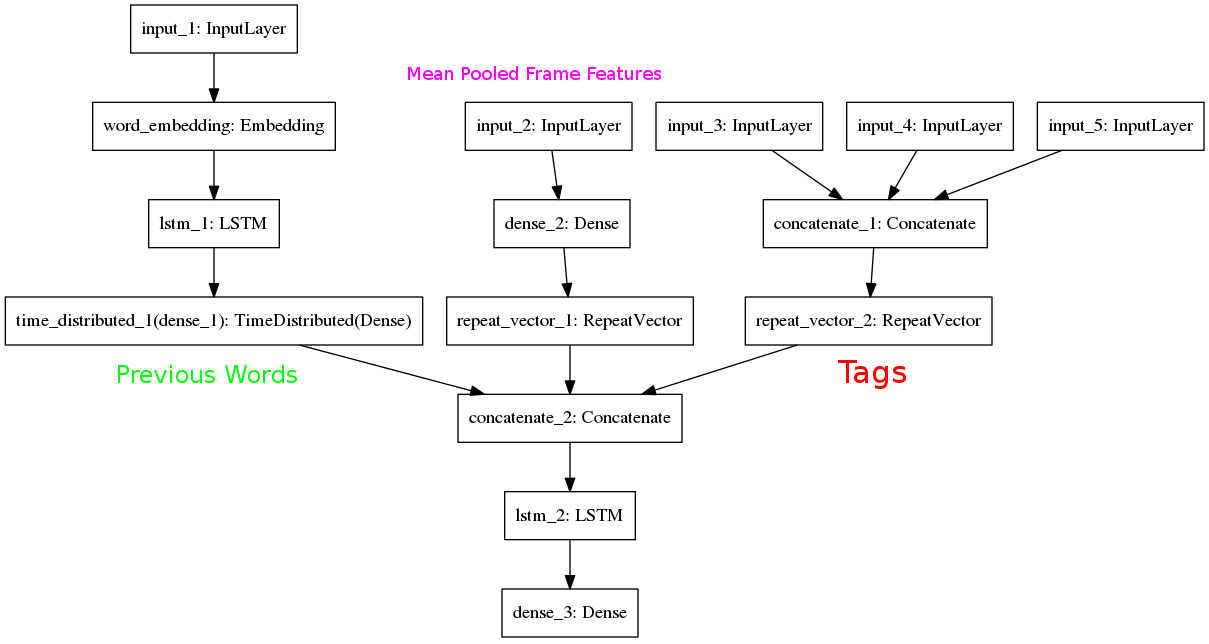
The video captioning model here uses Mean Pooled ResNet50 features of video frames along with Object, Action and Attribute tags predicted by a simple feedforward network.
The Table below compares the performance of our model with some other models that also rely on mean pooled frame features. It is sourced from papers 1, 2 and 3.
| Model | METEOR score on MSVD |
|---|---|
| Mean Pooled (AlexNet Features) | 26.9 |
| Mean Pooled (VGG Features) | 27.7 |
| Mean Pooled (GoogleNet Features) | 28.7 |
| Ours (Mean Pooled ResNet50 Features + Predicted Tags) | 29.0 |