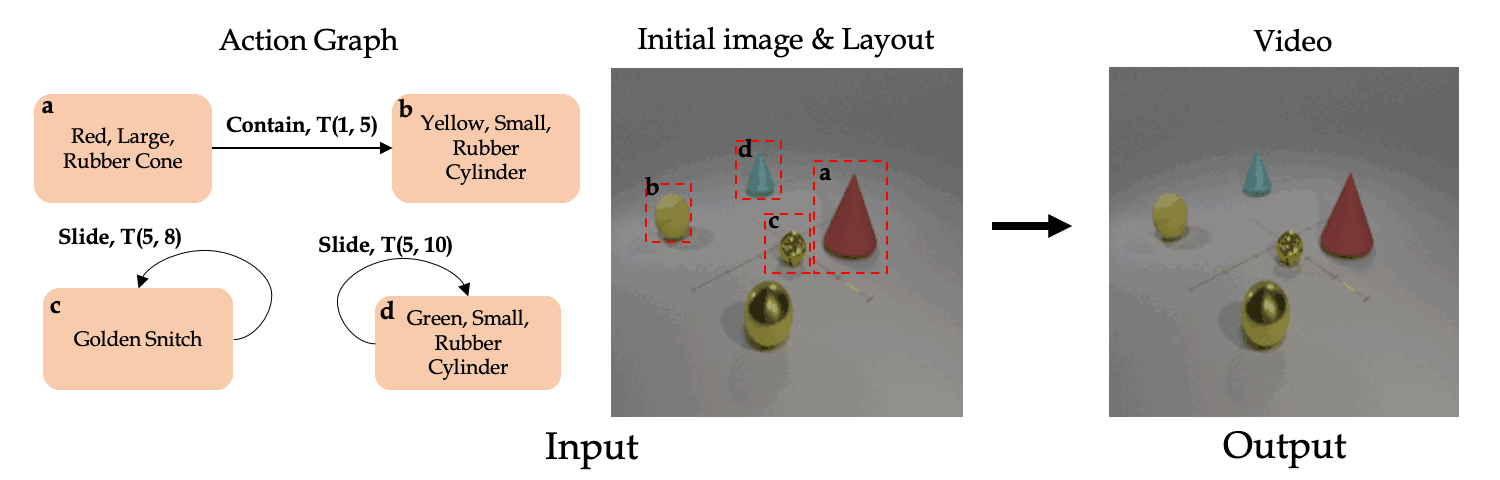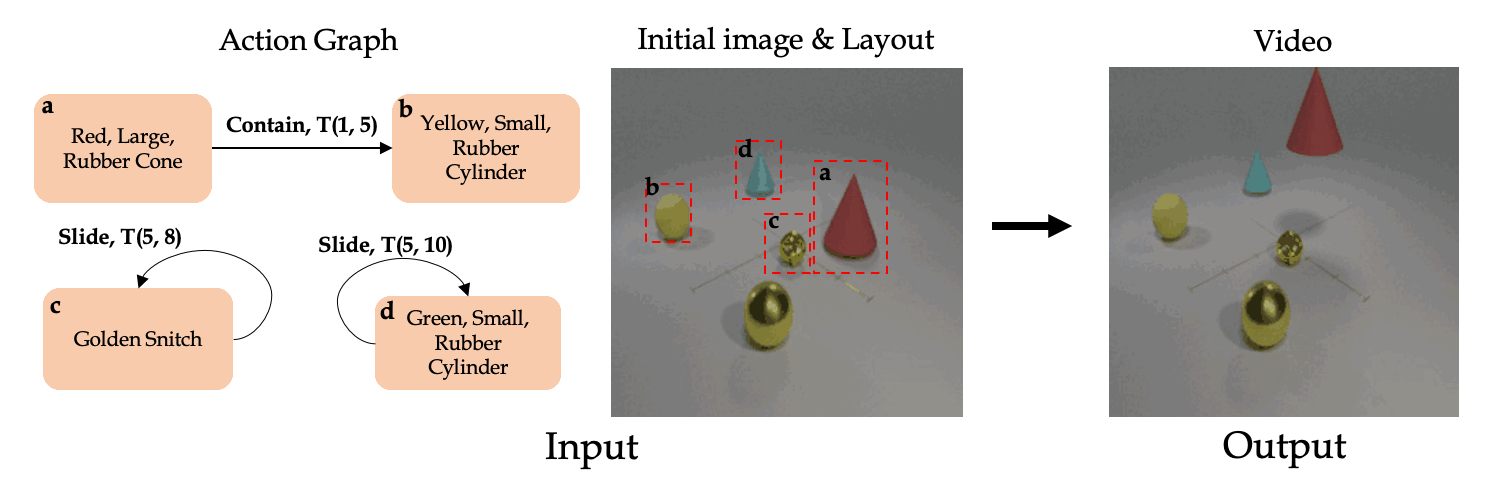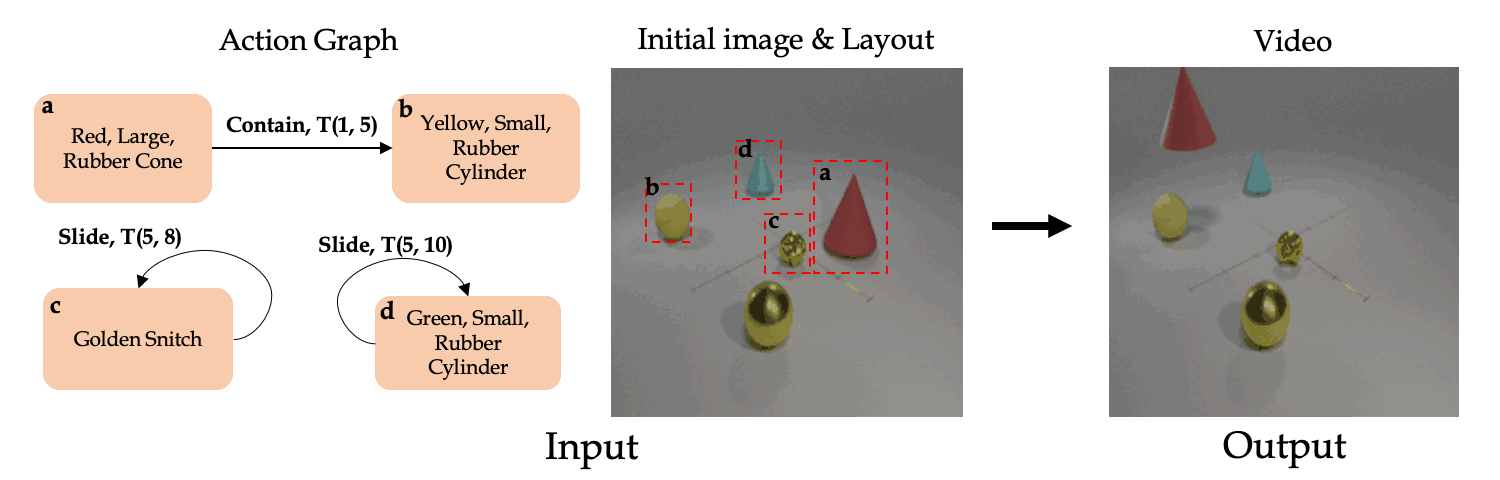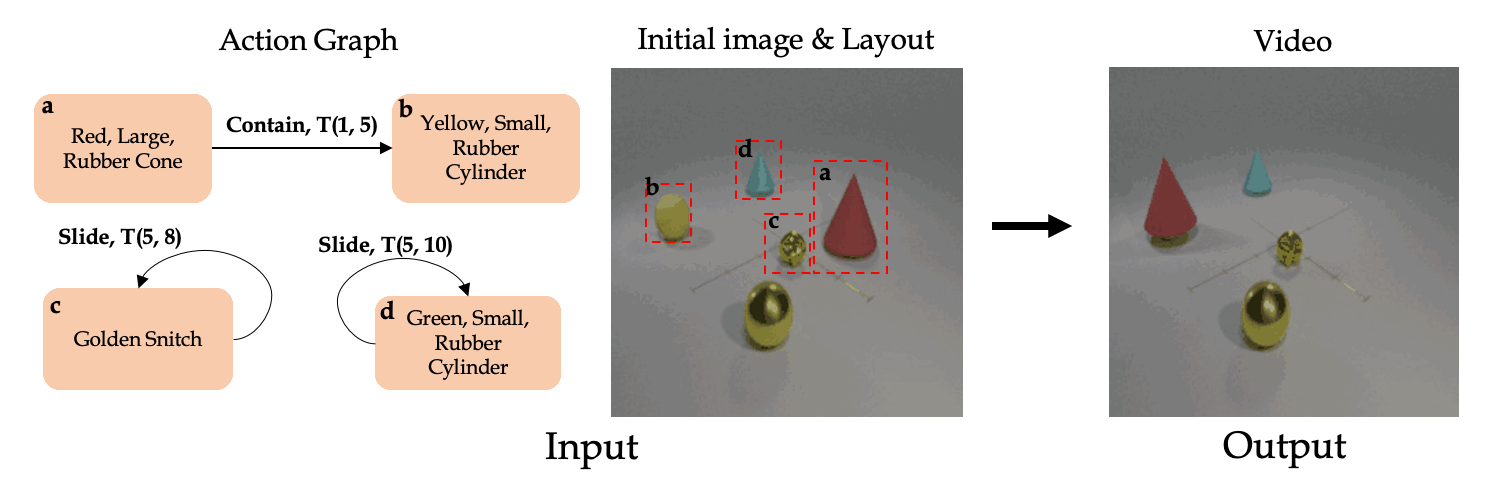
Back to Project Page.
- CATER training code and eval - DONE
- Something-Something V2 training code and eval- TODO
- Pretrained models - TODO
We recommend you to use Anaconda to create a conda environment:
conda create -n ag2vid python=3.7 pipThen, activate the environment:
conda activate ag2vidInstallation:
conda install pytorch==1.4.0 torchvision==0.5.0 -c pytorch
pip install -r requirements.txtDownload and extract CATER data:
cd <project_root>/data/CATER/max2action
wget https://cmu.box.com/shared/static/jgbch9enrcfvxtwkrqsdbitwvuwnopl0.zip && unzip jgbch9enrcfvxtwkrqsdbitwvuwnopl0.zip
wget https://cmu.box.com/shared/static/922x4qs3feynstjj42muecrlch1o7pmv.zip && unzip 922x4qs3feynstjj42muecrlch1o7pmv.zip
wget https://cmu.box.com/shared/static/7svgta3kqat1jhe9kp0zuptt3vrvarzw.zip && unzip 7svgta3kqat1jhe9kp0zuptt3vrvarzw.zip
python -m scripts.train --checkpoint_every=5000 --batch_size=2 --dataset=cater --frames_per_action=4 --run_name=train_cater --image_size=256,256 --include_dummies=1 --gpu_ids=0
Note: on the first training epoch, images will be cached in the CATER dataset folder. The training should take around a week on a single V100 GPU. If you have smaller GPUs you can try to reduce batch size and image resolution (e.g, use 128,128).
A model with example validation outputs is saved every 5k iteration in the <code_root>/output/timestamp_<run_name> folder.
To run a specific checkpoint and test it:
python -m scripts.test --checkpoint <path/to/checkpoint.pt> --output_dir <save_dir> --save_actions 1
Note: this script assumes the parent directory of the checkpoint file contains the run_args.json file which includes some training configuration like dataset, etc.
@article{bar2020compositional,
title={Compositional video synthesis with action graphs},
author={Bar, Amir and Herzig, Roei and Wang, Xiaolong and Chechik, Gal and Darrell, Trevor and Globerson, Amir},
journal={arXiv preprint arXiv:2006.15327},
year={2020}
}
If you liked this work, here are few other related works you might be intereted in: Compositional Video Prediction (ICCV 2019), HOI-GAN (ECCV 2020), Semantic video prediction (preprint).
Our work relies on other works like SPADE, Vid2Vid, sg2im, and CanonicalSg2IM.