Variational autoencoder for molecules in tensorflow.
- Rdkit
conda install -c rdkit rdkit- Tensorflow
cpu-version
pip install tensorflowgpu-version
pip install tensorflow-gpuChEBML 24 Database was used for SMILES data.
SMILES strings were padded with spaces to max_len(default=120) and strings larger than max_len were discarded. Remaining strings are labeled character by character(max_len labels in one string).
Does the following steps:
- Downloads chembl_24_1_chemreps.txt.gz
- Preprocess SMILES strings
- Saves processed data into numpy arrays.
Numpy arrays contains training data, testing data, dictionaries for character <-> label(integer) interchange.
Model consists of CNN encoder and CuDNNGRU decoder and defined in vae.py
Does the following steps:
- Loads preprcessed data
- trains with fit_generator using DataGenerator
Notebooks are here to help after training is done.
This notebook helps to get variational structures when given a SMILES string.
This notebook helps visualizing learned latent space using a plot or tensorboard.
tensorboard visualization example:
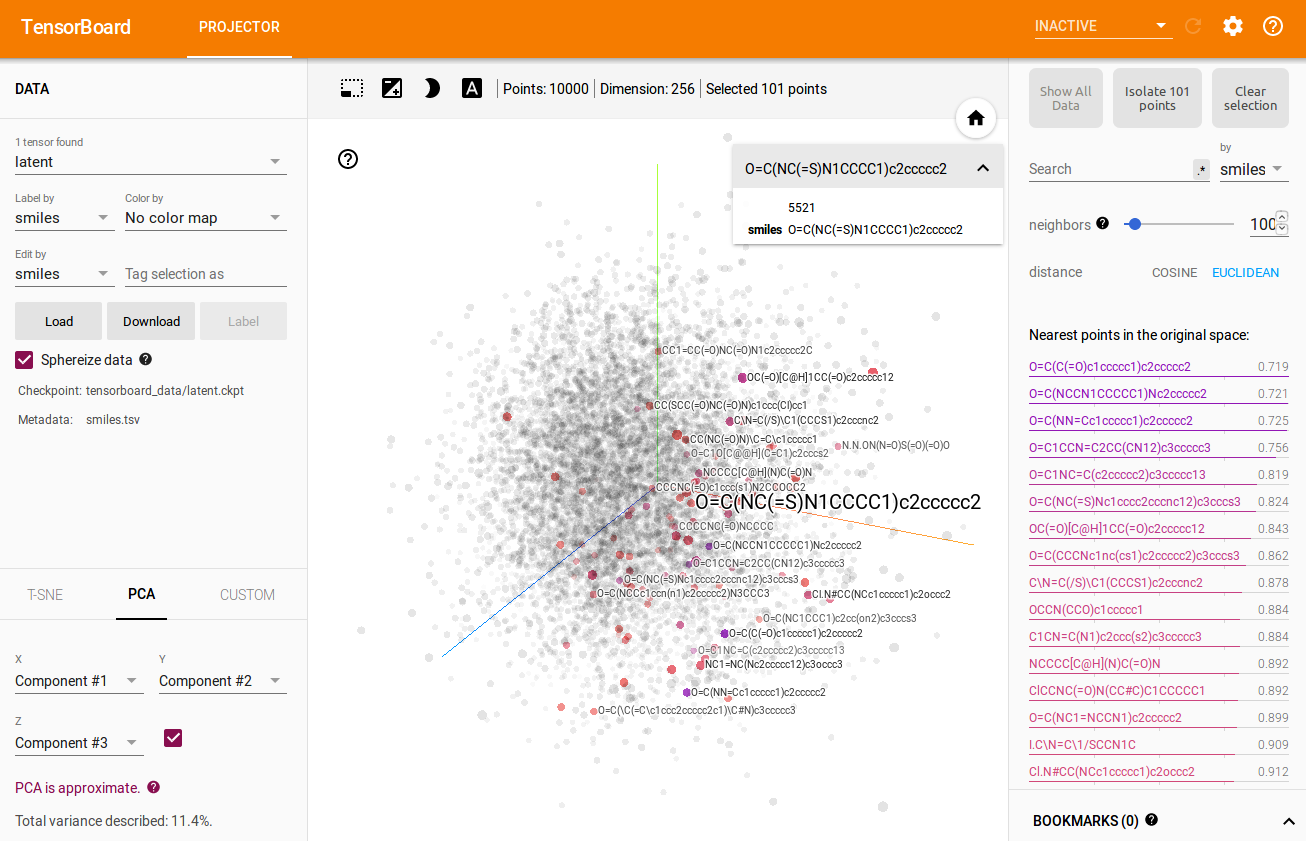
This notebook helps to get top_k similar molecules measured by euclidean distance in latent space.