This is a possible implementation for a service for taking screenshot of a webpage. It shall be scaled up horizontally, and vertically to respond to massive amount of requests. It uses RabbitMQ as the messaging system.
-
It uses chromedp as the screenshot engine. Other screenshot engines are possible to add.
-
It uses the Request-Reply pattern, that is referred to as Remote Procedure Call (RPC).
-
Worker run jobs in parallel, and send the response, when they have it.
-
The dispatcher reads the jobs from the file. It sends out the requests and waits for the response.
-
The responses are saved in Amazon S3. The response contains a link to S3 so that user can have access to the screenshot next time.
-
It is written in Go.
-
Worker, and Dispatcher nodes are disigned to be standalone and can be scaled up as a possible "scaling group" in Amazon terms.
The input is a number of URLs, and the output is a number of screenshots.
To run it, you should know that there are three components. worker, dispatcher, broker.
There are two alternative solutions that we can choose for this service. Current Implementation has a broker-based approach. The broker-less approach would be added in the future.
- With a message Broker
- Without a message Broker
There is a trade-off between complexity and cost.
The full implementation is the approach with message-broker, due to ease of extension for future features.
This architecture is an extended version of RabbitMQ RPChttps://www.rabbitmq.com/tutorials/tutorial-six-go.html tutorial. If you want to understand why such architecture is chosen you can read the RabbitMQ tutorial. However, it is important to note that in the RabbitMQ tutorial, as a simplified version, It is not possible to run the "Client" program concurrently. For this project, the dispatcher is a modified version of "client" in the tutorial. It works, but it is recommended to use this system using asynchronous clients such as websocket-enabled for better performance. (Future improvement idea)
The deployment, worker,dispatcher are involved with the broker-based approach.
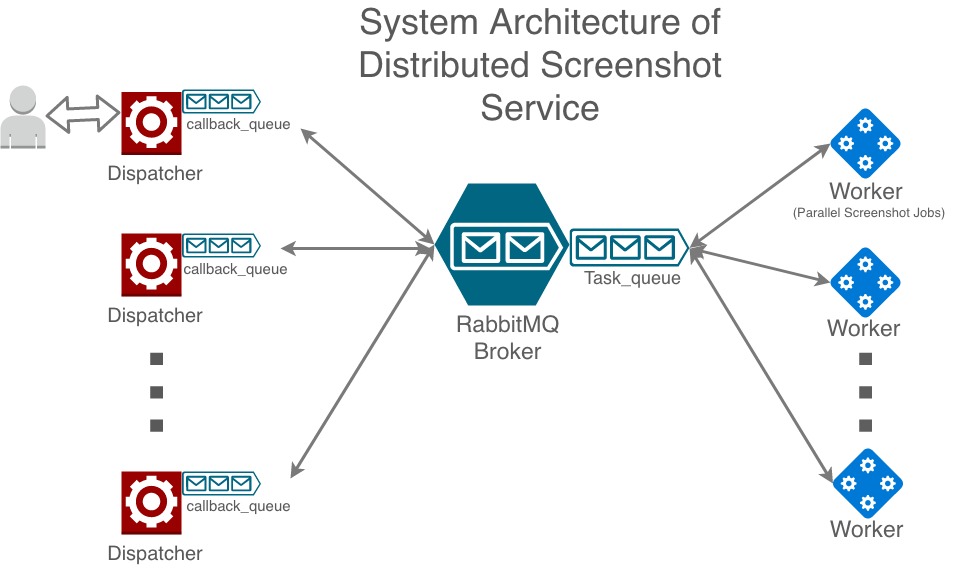
This is the diagram of the system.
diagram of broker and worker and dispatcher
- It is simpler to implement. Less concurrent code means less hard-to-find bugs.
- A
workerinstance could be in an internal network to do its job. In this case that it needs to connect to the internet for taking screenshot, it could be hidden a private network behind a NAT. The NAT doesn't allow connections to be initiated from outside of the network. - If a
workerstops working, thebrokerwould detect if faster, and the message could be handed over to another worker by the RabbitMQ broker. This nice feature can be handled by proper configuration, without the need to re-invent the wheel. - If someone else wants to extend the work, they read the worker code that is about the logic, not the code about how concurrency is handled, which may save time and energy in the long-run, and a more maintainable code.
- Broker is the single point of failure. The whole solution could be mirrored as fail-over service, but cost, complexity?
- Possible vulnarabilities, immaturities in the RMQ protocol.
TODO: not complete.
This way, a single micro-service is developed in go. This micro-service is responbile for the quality of the service. The micro-service, should know its limits, and if the micro-service's resources are getting saturated, it should not get more requests, since it will increase latency of the requests.
- The micro-service would have a pool of go-routines that handle screenshot taking in parallel. This parameter depends on the CPU, Memory capability of the OS, since we use chrome-headless, it should be measured over time, to fine-tune this parameter.
- The micro-service would have a pool of go-routines that handle S3 operations, to prevent exhausting file descriptors. (We cannot have more than a number of open socket connections.)
TODO
If you have any question or suggestion, you can contact me. https://rahafrouz.github.io/amir