爬取一个或多个指定微博用户关注列表中的微博账号,批量获取其user_id,并写入user_id_list.txt文件。
程序支持读文件,一个用户最多可以获取200个user_id,写入user_id_list.txt文件;然后可以用生成的user_id_list.txt作为config.json文件“user_id_list”参数的值,继续获取user_id,生成文件,最多可以获得200X200=40000个use_id;然后又可以利用这40000个user_id获得40000X200=8000000个user_id,以此类推,可以获得大量user_id。
$ git clone https://github.com/dataabc/weibo-follow.git
$ pip install -r requirements.txt
{
"user_id_list": "user_id_list.txt",
"cookie": "your cookie"
}
user_id_list可以填目标用户user_id文件路径,上面填的就是路径,user_id_list.txt内容是user_id,可以写多个,每个user_id一行,可以像下面这样填:
1669879400
1223178222
具体如何获取一个微博用户的user_id,见如何获取user_id, 也可以添加注释,这样填:
1669879400 Dear-迪丽热巴
1223178222 胡歌
也可以直接填目标用户user_id,如:
"user_id_list": ["1669879400", "1223178222"]
上面的意思是分别获取user_id为“1669879400”、“1223178222”的用户的关注列表,并将被关注者的user_id写入user_id_list.txt;
cookie是微博爬虫cookie,具体如何获取cookie见如何获取cookie,获取后用真实的cookie替换“your cookie”就可以。
$ python weibo_follow
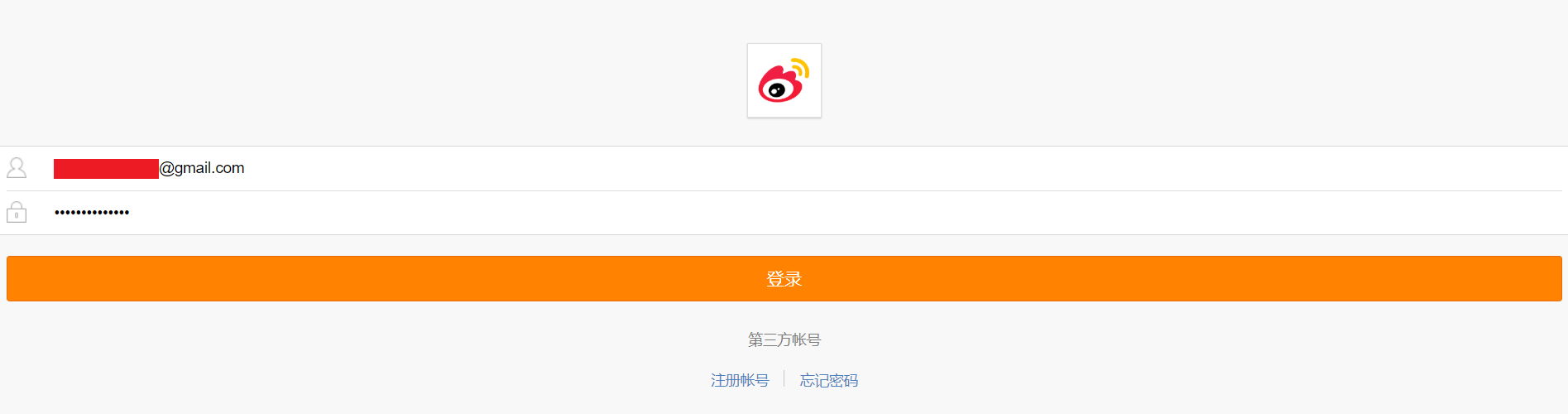
1.用Chrome打开https://passport.weibo.cn/signin/login;
2.输入微博的用户名、密码,登录,如图所示:
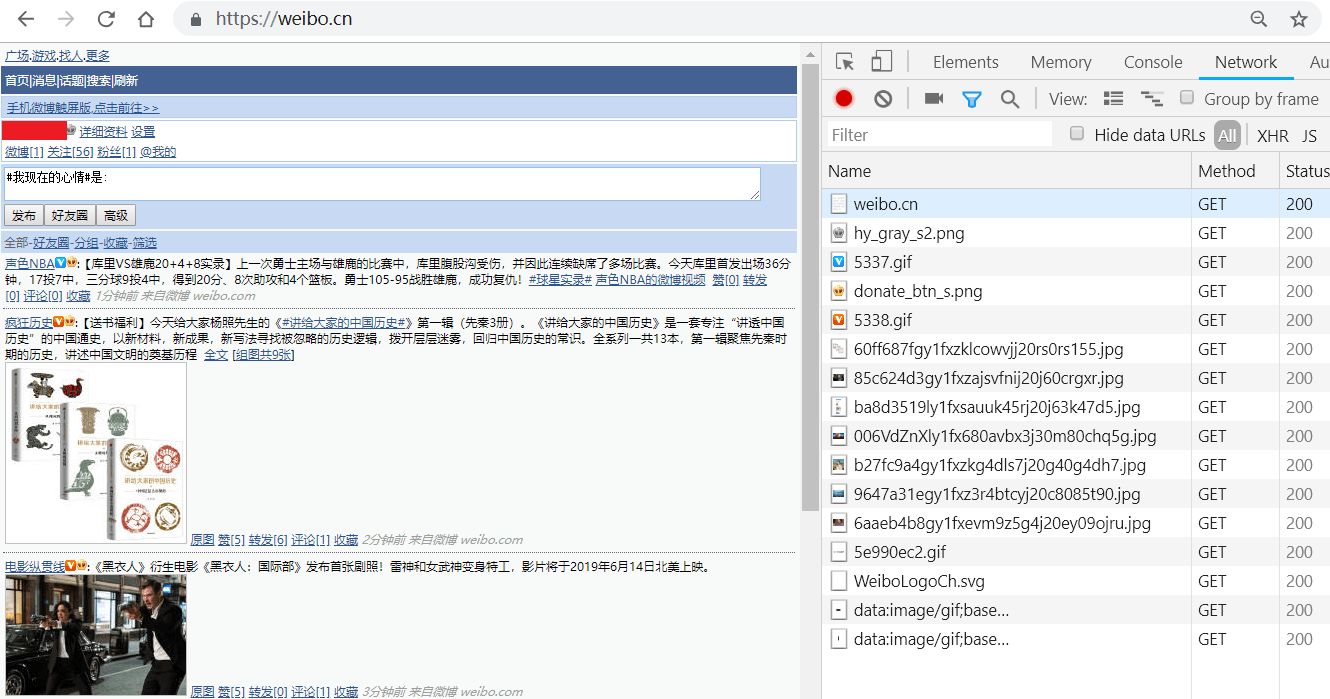
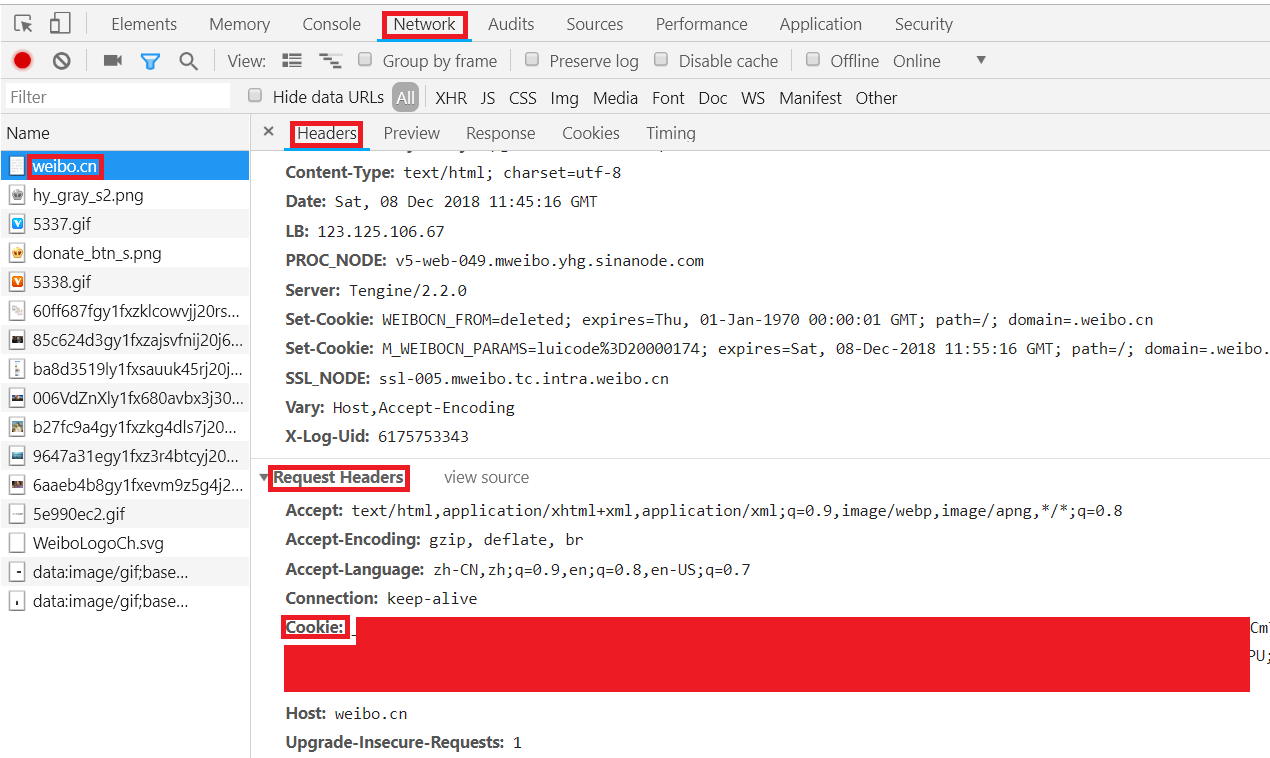
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到https://weibo.cn,跳转后会显示如下类似界面:
1.打开网址https://weibo.cn,搜索我们要找的人,如"迪丽热巴",进入她的主页;
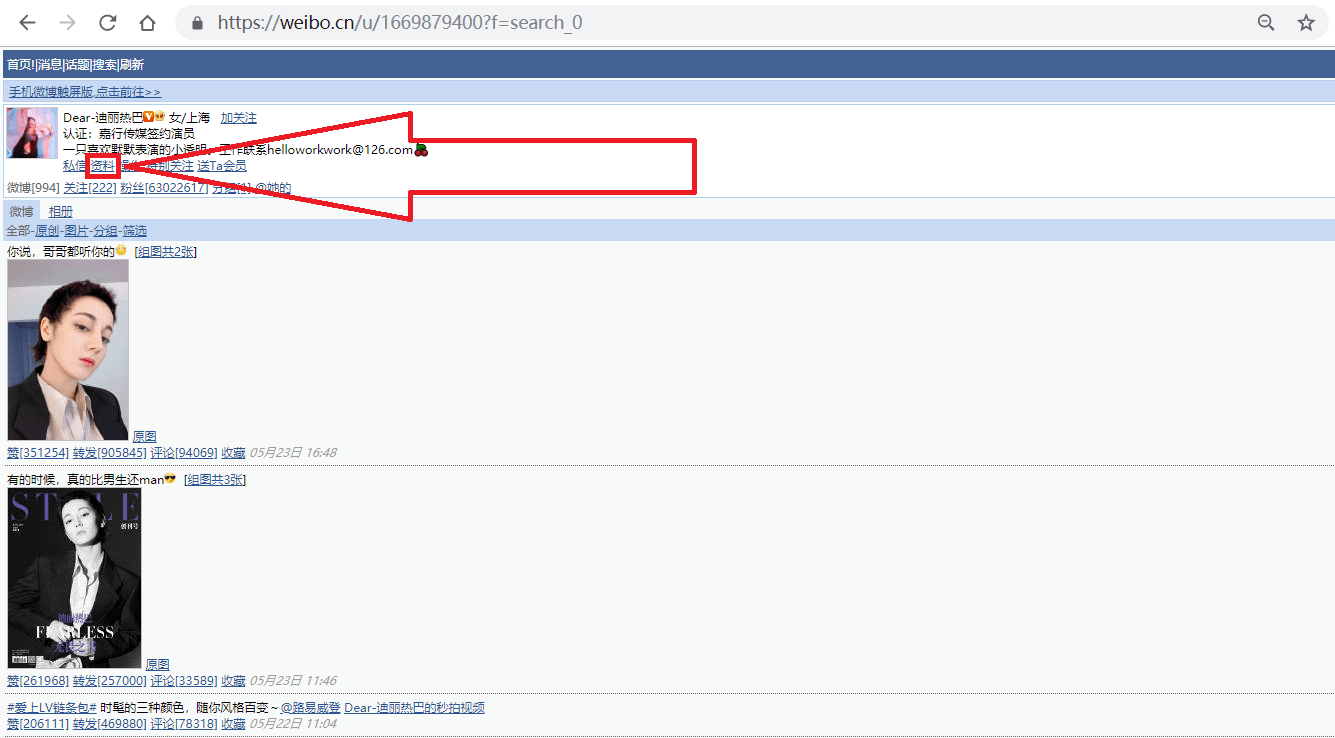
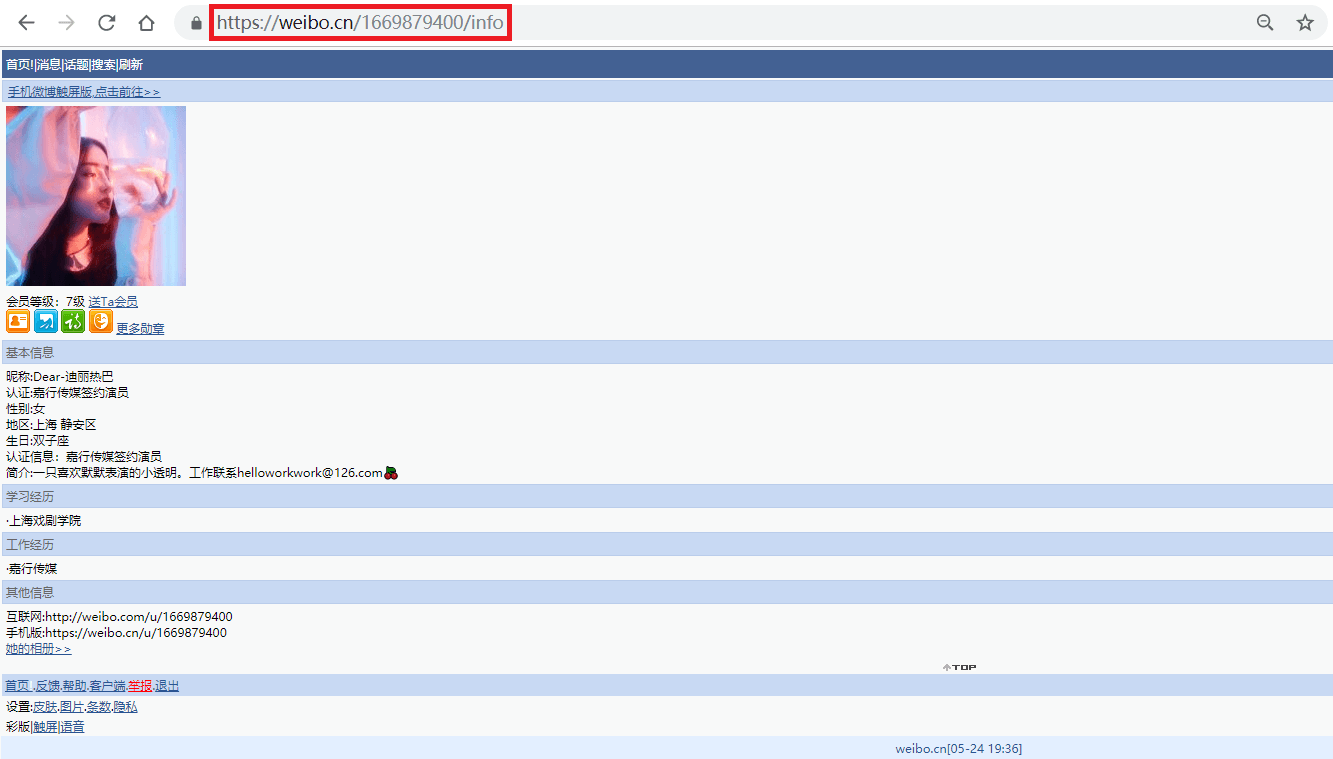
事实上,此微博的user_id也包含在用户主页(https://weibo.cn/u/1669879400?f=search_0)中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是"https://weibo.cn/user_id?f=search_0"的形式,而是"https://weibo.cn/个性域名?f=search_0"或"https://weibo.cn/微号?f=search_0"的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。