Today I Learned in Java ...
Jump to Day
00 • 01 • 02 • 03 • 04 • 05 • 06 • 07 • 08 • 09 • 10 • 11 • 12 • 13 • 14 • 15 • 16 • 17 • 18 • 19 • 20 • 21 • 22 • 23 • 24 • 25 • 26 • 27 • 28 • 29 • 30 • 31 • 32 • 33 • 34 • 35 • 36 • 37 • 38Day 00 ↑
- everything is always passed by value.
- in case of primitive argument, the value is the primitive.
- in case of object reference argument, the value is the memory address.
- there can be more than one class defined in a file but only one of them can be public.
- if there are multiple classes defined in a single file, then compiling the file will lead to those many
.classfiles and they will have names of the corresponding classes. - the class name and the file name can be different unless it's a public class.
>>is right shift operator.>>>is unsigned right shift operator.- multiple
.classfiles can be archived into one.jarfile by runningjar cvf archive.jar c1.class c2.class. javapcan be used to view the generated Java bytecode,javap -c HelloWorld.class.
Day 01 ↑
- if there is a class which uses other classes, then compiling that class will lead to compilation of all the classes it uses, as the compiler can't really know whether it is valid Java code without doing a depth first compilation first.
- compiling the class that contains
main()will lead to compilation of the whole project, as it is the entry point. - the compiled
.classfiles need not be present in the current directory for a program to run, provided the classpath(s) is/are mentioned by using the-cpflag. By default, the classpath is set to current directory only. - the class loader will look for
.classfiles in the classpath during runtime. - the
-cpflag can also be used during compile time to let compiler know where the classes are present. - a
.jarfile can also be a classpath i.e., the-cpflag may contain both directories as well as files. - multiple classpaths can be separated by using : in Linux and ; in Windows.
Day 02 ↑
- once the type of a variable is set it can not be changed later as Java is a statically typed language.
- if the variable type is a class, then the variable will be an object reference.
- there are 3 types of variables in Java:
- local variables: declared in methods, constructors or blocks.
- instance variables: declared in a class but outside any methods, constructors or blocks.
- class/static variables: declared with the
statickeyword in a class but outside any methods, constructors or blocks.
- local variables must be initialized with a value before they are used.
Day 03 ↑
Stringobjects are immutable i.e., we cannot change the object itself, but we can change the reference to the object.StringBuilderandStringBufferobjects are mutable i.e, they can be used for dynamic string manipulation.- in an expression if either operand in
+is aStringobject, then Java converts the other operand to aStringand creates a newStringobject by concatenating both operands. - for
String, each time a string is concatenated, a new object is created and it's the main reason why it's not recommended for cases where a lot of string manipulation is needed, instead using aStringBuilderorStringBufferwill be more efficient. - operator overloading is not possible. Note that string concatenation operator
+is not an overloaded operator. - the string concatenation operator is just syntactic sugar, it is actually implemented through the use of the
StringBuilderorStringBufferclasses'append()method. - the compiler automatically converts an expression with string concatenation operator into a series of calls to the
append()method.
String s1 = "Hello"; String s2 = "World"; String s3 = s1 + " " + s2;is equivalent to:
String s1 = "Hello"; String s2 = "World"; StringBuilder sb = new StringBuilder(); sb.append(s1).append(" ").append(s2); String s3 = sb.toString();
Day 04 ↑
- array and class variables are pointers/object references.
- a default initial value is assigned to each element of a newly allocated array if no initial value is specified. For numerical types it is
0, for boolean it isfalseand for any pointer/object reference it isnull. - 2D arrays need not be rectangular, each row can be of different length. Helpful for symmetric matrices.
int[][] A = new int[3][4]; // rectangular int[][] B; // not rectangular B = new int[3][]; B[0] = new int[1]; B[1] = new int[2]; B[2] = new int[5];
- we can copy an array using the
arraycopyfunction. Like the output functionprintln,arraycopyis provided injava.lang.System, so we must use the nameSystem.arraycopy. The function has five parameters:- src: the source array
- srcPos: the starting position in the source array
- dst: the destination array
- dstPos: the starting position in the destination array
- count: number of values to copy
// to shift the values in an array: int[] A = {0, 1, 2, 3, 4}; System.arraycopy(A, 0, A, 1, 4);
Day 05 ↑
- there are no
byteorshortliterals but onlyintandlongliterals. _ can be used to improve readability of the literals. We can make a literallongby appending L or l. - a
longliteral can't be assigned to anbyte,shortorintvariable. The compiler will throw an "possible lossy conversion" error. Similarly adoubleliteral can't be assigned to anfloatvariable. - every primitive type has an associated boxed primitive, which have a lot of predefined functions and variables to make things easy.
int minValue = Integer.MIN_VALUE; int maxValue = Integer.MAX_VALUE;
- some numbers like 0.1, 0.2 etc. can not be accurately represented with IEEE 754 standard, as numbers represented in this format are a whole number times a power of two; rational numbers (such as 0.1, which is 1/10) whose denominator is not a power of two cannot be exactly represented.
Day 06 ↑
- instance and class/static variables are assigned a default value if nothing is assigned, for numerical types it is
0, for boolean it isfalseand for any pointer/object reference it isnull. - assignment statements aren't possible in the class level but if they are a part of a declaration statement then it is possible.
class Example { int a, b = 10; a = 10; // not possible }whereas,
class Example { int a; int b = a = 10; // possible }
- expression and control flow statements aren't possible in the class level.
- only numeric to numeric casting is possible. Note that
charalso falls under numeric data type as it is represented by an unsignedint. - we can not cast anything to
booleanor vice-versa, as it is a non-numeric primitive (the only non-numeric primitive).
Day 07 ↑
- there are two types of type casting:
- implicit type casting: will be done automatically
- smaller to larger (widening conversion)
- integer to floating point
- explicit type casting: should be explicitly mentioned
- larger to smaller (narrowing conversion)
chartobyte/shortand vice-versa requires explicit casting
- implicit type casting: will be done automatically
- casting to
charis always explicit as all the other numeric types can have negative values whereascharcan't take negative values. - if we are casting a value to a data type but the value is outside the range of the data type then JVM will discard all but the lower bytes of the value. For example,
byte b = (byte) 130; // +130 (= 0b0000_0000_1000_0010) System.out.println(b); // -126 (= 0b1000_0010)
- floating point to integer will always truncate the value.
int pi = (int) 3.14f; // pi = 3 char a = (char) 65.5; // a = 'A'
- information loss due to implicit casting is also possible. Assigning a
int/longtofloatorlongtodoublecould lead to loss of precision, usually the case when the numbers are large, as IEEE 754 fails to accurately represent large numbers.
int i = 1234567890; float f = i; System.out.println((int) f);
- for object references, bit depth is JVM specific i.e., in a JVM all object references will have the same size.
- there are various ways to initialize an array:
int[] a = {1, 1, 1}; // can only be used in a declaration statement int[] b = new int[]{1, 1, 1}; int[] c = new int[3]; // or `int c[] = new int[3]` Arrays.fill(c, 1); int[][] d = {{1, 2}, {3, 4}, {5, 6}}; int[][] e = new int[][]{{1, 2}, {3, 4}, {5, 6}}; int[][] f = new int[3][2]; int[] g = f[1];
Day 08 ↑
- we cannot have a static method access non-static members because we have no way of knowing which non-static members we should be accessing i.e., static methods have no access to state (instance variables/methods). Note this holds for
mainmethod too as it isstatic.
public class InstanceInStatic { int instanceVariable; void instanceMethod() {} static int staticVariable; static void staticMethod() {} public static void main(String[] args) { System.out.println(instanceVariable); instanceMethod(); // will result in a compilation error: // "non-static variable/method can not be referenced from a static context" System.out.println(staticVariable); staticMethod(); // possible } }
- we can access anything from an instance method, even
staticvariables/methods. - method overloading doesn't work if we only change the return type as return type is not included in the method signature.
Day 09 ↑
- when there are multiple methods with the same name, the compiler tries to find a method having parameters with the exact same data type, but if it isn't present then it tries to find a method that has the next larger data type.
void example(int a) {} void example(short a) {} byte b = 1; example(b); // will call `example(short)`
- the process of compiler picking the method to be invoked and subsequently JVM using that information at runtime is called method binding.
- we can pass zero or more parameters to a function by using varargs (variable-length arguments). It gives an illusion that the method is infinitely overloaded.
- a method can't have more than one varargs parameter.
- if the method has more than one parameter then the varargs parameter must be the last one.
- during invocation the corresponding argument can be an array of any size or it can be a sequence of any number of comma separated arguments, in this case the compiler automatically converges them into an array.
void example(int... items) {} example(1, 2, 3); // = example(new int[]{1, 2, 3});
System.out.printfuses varargs under the hood.- we can use
main(String... args)instead ofmain(String[] args). - if we have a bunch of overloaded methods and one of them is a varargs method then during method invocation the varargs method will be the last one to be matched.
- below is an invalid overload example:
void foo(boolean flag, int... items) {} void foo(boolean flag, int[] items) {}
Day 10 ↑
- the main purpose of the constructor is to initialize the object's state.
- the default constructor is inserted only if the class definition does not include a constructor.
- constructors don't return anything but they can have a
return. this()is used to call an overloaded constructor, must be first statement in a constructor.- we can't have more than one
this()per constructor. - calling the same constructor using
this()will lead to a recursive invocation error. Another way this is possible if one constructor calls another and the called constructor calls the callee.
class Example { Example() { this(1); } Example(int i) { this(); } }
- we can't have an instance variable inside
this()invocation statement, it's because the variable is not yet initialized at that point in time, it'll result inerror: cannot reference variable before supertype constructor has been called. - there is an implicit call to the
Objectsuperclass after which the control comes to the subclass where all the instance variables get initialized. - from Java 11 onwards we can compile and execute a program by running a single command,
java Hello.java. Compilation will happen in memory and so will not generate a.class.
Day 11 ↑
- arithmetic operators can't be used on
boolean, but bitwise operators can be used. - it is not possible to use bitwise not (
~) withboolean, if such a behavior is needed then we will have to use logical not (!). - bitwise operators can't be used on
floatanddouble. - in an arithmetic operation, operands smaller than
intare promoted toint.
System.out.println('a' + 'b'); // = 195
- if operands belong to different types, then the smaller type is promoted to larger type (true for ternary operators as well). Note if
longandfloatare operands,longis promoted tofloateven thoughlongis 64 bits andfloatis 32 bits. (order of promotion: int -> long -> float -> double) - in a logical
&&and||statement, the evaluation of right operand/statement is conditionally dependent on the evaluation of left operand/statement. &&can be used to preventNullPointerException.
if (obj != null && obj.id == 1024) ...
- according to the Java Language Specification (JLS),
&,|and^when applied onbooleanoperands are referred to as logical operators and not bitwise. In other words, the operators&,|,^,~are referred to as bitwise ONLY when they are applied on integer operands.
Day 12 ↑
switchcan take anenumor an integer (byte,short,char,int) expression or a corresponding wrapper class. At runtime when the variable is evaluated, the primitive value will be unwrapped and will be compared with thecaselabels.switchexpression can also be aString(from Java 7 onwards).- as we can have object references as
switchexpression, there is a possibility of it evaluating tonullleading to aNullPointerException. - the value of the
caselabel must be unique, non-null, within the range of the data type of theswitchexpression and should be known at compile time itself.
byte b = 2; switch (b) { case 1: ... break; case 128: // error ... break; }
- a ternary expression can't be used as a standalone statement.
for (;;) { ... }is same aswhile (true) { ... }.- labelled
breakcan be used to break out of a code block.
label: { if (true) break label; System.out.println("This statement will not get executed."); }
- the label used with a
breakstatement must be the label of the block in which thebreakstatement appears.
Day 13 ↑
- it is possible to have a labelled
continuewhich can only be associated with an enclosing loop statement unlike labelledbreakwhich can be associated with any block statement. - classes can directly reference other classes in the package by directly using the class names, but to access a class from a different package we have to either use
importor by using the package followed by dot followed by the class name.
import java.util.ArrayList; ... ArrayList A = new ArrayList();or,
java.util.ArrayList A = new java.util.ArrayList();
java.lang.*is imported by default.- strings are objects of the class
java.lang.String.
Day 14 ↑
- if we want to access a
classfrom anotherpackagethen it should have thepublicaccess modifier, not required if we are accessing it from the samepackage. - there are four access modifiers:
- private: inside class
- default: inside package
- protected: inside package and any subclass (need not be in the same package)
- public: inside and outside package
- an object of a class can access
privatemembers of another object of the same class.
class Student { private int id; boolean equals(Student s) { return id == s.id; } }
- a string literal is also a
Stringobject. Below are a few ways to initialize aStringobject.
String s0 = "Hello!"; String s1 = new String(); // empty string String s2 = new String(s0); char[] c = {'h', 'e', 'l', 'l', 'o'}; String s3 = new String(c);
- regular Java objects can't be assigned literals directly but assigning literals to wrapper class objects is possible.
- the string pool is a memory area in the heap where the JVM stores all string literals. When we create a string literal, the JVM first checks the string pool to see if an identical string already exists. If it does, the JVM simply returns a reference to that string, rather than creating a new
Stringobject. This helps to conserve memory, as the JVM only needs to store one copy of each unique string value in memory. - when we create a string using the
newkeyword, a newStringobject is always created in the heap, separate from the string pool. The contents of thisStringobject can be the same as a string in the pool, but it is still a separate object in memory, with its own memory address.
String s1 = "abc"; String s2 = "abc"; String s3 = new String("abc"); System.out.println(s1 == s2); // true System.out.println(s1 == s3); // false
Day 15 ↑
- the
Stringobjects created using thenewkeyword are separate objects in memory, they can still benefit from the memory-saving properties of the string pool. If we call theintern()method on aStringobject created using thenewkeyword, the JVM will add that string to the pool if it's not already there, and return a reference to the interned string. - the primary use of the
intern()method is to conserve memory. When we intern a string, the JVM only needs to store one copy of that string in memory, and all references to that string will refer to the same object. This can be especially useful when working with a large number of strings that have the same value, as it can greatly reduce the amount of memory used by the program.
String s1 = "Hello"; String s2 = new String("Hello"); // Before interning, s1 and s2 refer to different objects in memory System.out.println(s1 == s2); // false // Intern s2 s2 = s2.intern(); // After interning, s1 and s2 refer to the same object in memory System.out.println(s1 == s2); // true /* In this example, s1 is created using a string literal, so it is automatically interned. s2 is created using the String constructor, so it is not interned. When we call s2.intern(), the JVM checks the pool of all interned strings, finds a match for the value of s2, and returns a reference to that string. From this point forward, s1 and s2 refer to the same object in memory. */
- the term "intern" is a metaphor that refers to the practice of interning objects in a pool, much like an internship program. Just as an intern program pools together interns from different companies to work on a shared project, string interning pools together all strings with the same value so that they can be represented by a single instance in memory.
- the result string literal concatenation is also stored in the string pool, however if one of them is a variable, the result won't go to the string pool as it is evaluated at the run time. But if we make the variable a
finalthen it'll be evaluated at compile time itself and will end up at the string pool.
String s1 = "Hello"; String s2 = "lo"; final String s3 = "lo"; System.out.println(s1 == "Hel" + "lo"); // true System.out.println(s1 == "Hel" + s2); // false System.out.println(s1 == "Hel" + s3); // true
Day 16 ↑
- classes and interfaces can only have
publicordefaultaccess specifiers. - all the methods in
java.lang.Mathare static. - the
Mathclass is non-instantiable, which means we can't create it's objects. This can be achieved by making the default constructorprivate. - there are two types of initializers, static initializer and instance initializer.
- static initializers are used to initialize the static variables. A static initializer is declared using the
statickeyword, and it is executed only once when the class is loaded.
class Example { static final double i; static HashMap<Integer, String> h = new HashMap<>(); static { i = Math.random(); h.put(1, "one"); h.put(2, "two"); } }
- static initializers are useful when we need to initialize
staticvariables with a value that can't be computed at compile time. - we can't reference instance variables from static intializers.
- instance initializers are used to initialize instance variables. The syntax is similar to static initializer but without the
statickeyword. - a constructor can also be used to initialize instance variables but instance initializers are helpful if we want to share a block of code between multiple constructors i.e., Java compiler copies initializer blocks into the beginning of every constructor.
- we can reference static variables from instance initializers.
- if there is a chain of overloaded constructor invocations, then instance initializer code will be copied only into the last invoked constructor. This ensures that instance initializer code is executed only once for every object that gets created. So, instance initializer code is copied into every constructor that does not have a
this()invocation statement. - if there are multiple initializers (static or instance) then they will be executed in order.
Day 17 ↑
java.lang.StringBuilderhas four constructors:StringBuilder(): constructs a string builder with no characters in it and an initial capacity of 16 charactersStringBuilder(CharSequence seq): constructs a string builder that contains the same characters as the specifiedCharSequenceStringBuilder(int capacity): constructs a string builder with no characters in it and an initial capacity specified by the capacity argumentStringBuilder(String str): constructs a string builder initialized to the contents of the specified string
- the
capacity()method ofStringBuilderclass returns the current capacity of the builder. If the number of character increases from its current capacity, then a new internal array is allocated with a size that is twice the old size plus 2 and the data is copied over.
StringBuilder s = new StringBuilder(); System.out.println(s.capacity()); // 16 s.append("Hello, World!"); System.out.println(s.capacity()); // 16 s.append("!!!!"); System.out.println(s.capacity()); // 34
- the
ensureCapacity()method ensures that the capacity is at least equal to the specified minimum. If the current capacity is less than the argument, then a new internal array is allocated with greater capacity. The new capacity is the larger of the argument or twice the old capacity, plus 2.
StringBuilder s = new StringBuilder(); System.out.println(s.capacity()); // 16 s.ensureCapacity(10); System.out.println(s.capacity()); // 16 s.ensureCapacity(17); System.out.println(s.capacity()); // 34 s.ensureCapacity(71); System.out.println(s.capacity()); // 71
- the
trimToSize()method attempts to reduce storage used for the character sequence. It creates a new internal character array with the current length of the buffer and copies the content of the old array to the new array.
Day 18 ↑
- the
deletemethod inStringBuilderwhen called copies the remaining characters in the buffer to the left to fill in the gap created by the deleted characters. This operation can be slow if the buffer is large and the number of characters to delete is large. - when we make a reference variable
finalthen the reference is constant, not the object content. finalvariables can't get default values.- a
finalinstance variable once initialized can not be changed for the life of the object. They must be initialized during declaration or in constructor(s) or inside instance initializer. - a
finalstatic variable is constant irrespective of the number of instances. They must be initialized during declaration or inside the static initializer. (E.g.,public static final int MAX_VALUE = 0x7fffffff;). - constant variables are
finalvariables but for afinalvariable to be qualified as a constant variable there are few restrictions:- type of variable should be either a primitive or a
String. - the variable should be initialized in the declaration statement itself and the right side should be a compile time constant expression.
- type of variable should be either a primitive or a
- a static factory method is a public static method in a class that returns an instance of that class. These can be used to create objects instead of using a constructor.
Integer boxedI = Integer.valueOf(1); int i = boxedI.intValue();
Day 19 ↑
- one of the advantages of using static factory methods is that they allow for the caching and reusing objects, which can help to improve performance and reduce memory usage. This can be particularly useful when working with immutable objects, since they can be safely shared between different parts of a program.
- below is a static factory method from creating
Integerobjects, which checks if the value passed in is within -128 (IntegerCache.low) to 127 (IntegerCache.high) first, and if it is, it returns a cached instance of anIntegerobject instead of creating a new one. This technique is used to improve performance and reduce memory usage.
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
- the
IntegerCacheis initialized at runtime by the JVM and a total of 256Integerobjects are cached. In addition to these 256 objects, JVM also caches other commonly used boxed primitive objects. These include:Boolean:Boolean.TRUEandBoolean.FALSEByte: All possibleBytevaluesCharacter: All unicode characters from'\u0000'to'\u007f'Short: All possibleShortvaluesLong: AllLongvalues between-128and127Float:Float.NaN,Float.POSITIVE_INFINITY, andFloat.NEGATIVE_INFINITY.Double:Double.NaN,Double.POSITIVE_INFINITY, andDouble.NEGATIVE_INFINITY.
Integer a = Integer.valueOf(10); // returns a cached Integer object Integer b = Integer.valueOf(10); // returns the same cached Integer object Integer c = new Integer(10); // creates a new Integer object System.out.println(a == b); // true System.out.println(a == c); // false
Day 20 ↑
- prior to Java 5 one had to manually create a boxed primitive by invoking either it's constructor or by
valueOfmethod. But in Java 5 a feature called auto-boxing was introduced, meaning the compiler can automatically box a primitive if needed.
// auto-boxing Integer i = 5; // Integer i = new Integer(5); // auto-unboxing int j = i; // int j = i.intValue();
- auto-boxing can also be seen in method invocation
auto-boxing void go(Integer boxed) {} go(25); // compiler will wrap it before invocationauto-unboxing void go(int i) {} go(new Integer(25)); // compiler will unwrap it before invocationArrayList list = new ArrayList(); list.add(5); // list.add(new Integer(5));
- it is also possible to directly perform arithmetic operations on boxed primitives.
Integer i = 1; ++i; int j = 3 * i;
<,>,>=and<=on boxed primitives will lead to auto-unboxing but in case of==and!=the addresses will be compared.
Day 21 ↑
- a class can extend from only one class i.e., Java does not support Multiple Inheritance.
- is-a test is a fundamental test that can be used to check inheritance relationship. If it is failing then inheritance relation should not be applied.
- with polymorphism, a supertype can be assigned any of it's subtypes. It means that the type of object reference and the actual object referenced can be different, the type of object reference has to be a supertype of the actual object that is being referenced.
Employee employee = new Manager(); /*reference type*/ /*object type*/
- the compiler uses reference type to decide on whether a method can be invoked on an object reference or not.
User user = new Editor(); user.approveReview(); // compiler error, as User doesn't have this method
- at runtime, JVM uses the object type to decide which method is invoked, where JVM invokes the most specific version in the inheritance tree, starting from the object type and moving upwards in the tree.
Day 22 ↑
- once implicit casting on an inherited class is done, we can only invoke those subclass methods which are also defined in the super-class but sub-class specific methods become invalid. To address this we need to use explicit casting.
Staff s = new Editor(); s.approveReview(); // invalid ((Editor) s).approveReview(); // valid
instanceofoperator is used to check whether an object reference is indeed an instance of the class. Note that it is the object type, but not the reference type that matters. Also the object referenced by the variable can be a subclass of the class specified on the right side, it doesn't have to be a direct instance.
User u = new User(); Staff s = new Staff(); User us = new Staff(); System.out.println(u instanceof User); // true System.out.println(u instanceof Staff); // false System.out.println(s instanceof Staff); // true System.out.println(s instanceof User); // true System.out.println(us instanceof User); // true System.out.println(us instanceof Staff); // true
- there are two method overriding rules:
- same parameters and compitable return types (must be same or subclass type, applicable only to non-primitive return types)
- can't be less accessible (access level must be same or friendlier, e.g., we can't override a
publicmethod and make itprivate)
- the
superkeyword is related to objects that's why it can never be used inside astaticmethod.
Day 23 ↑
- method binding is the process of connecting a method call to the actual implementation of the method. There are two types of method binding:
- static binding: it occurs at compile time, where the compiler resolves the method call based on the declared type of the object.
- dynamic binding: it occurs at runtime, where the actual implementation of the method is determined based on the runtime type of the object.
- static methods are statically bound at compile time based on the declared type of the object however, instance methods are dynamically bound at runtime based on the actual type of the object.
- the
@Overrideannotation is used to indicate that a method in subclass intends to override a method of it's superclass. It is a way for the compiler to check that the method signature in the subclass is correct and that the method actually overrides a method in the superclass. If the method signature is incorrect or the method does not override a method in the superclass, the compiler will issue an error. - a
finalmethod can not be overriden. - both static as well as instance variables can not be overridden. Note that instance methods can be overridden but not instance variables.
- static methods can not be overridden since they are bounded at compile time and method overriding relies on dynamic binding at runtime. If static methods are redefined by a derived class, then it is not Method Overriding but Method Hiding.
Day 24 ↑
- if we pass
thistoSystem.out.println()then it automatically invokestoString(). If thetoString()method is overridden then it'll get invoked. - inherited methods might depend on superclass state that's why superclasses must be initialized first. This means that all the superclass constructors should run before the subclass constructor. This is achieved by constructor chaining, where a subclass implicitly calls the superclass constructor and this process goes on until the
Objectclass's constructor is invoked. - the
super()method can be used to explicitly invoke a superclass's constructor, however it must be the first statement. - a constructor can have either
this()orsuper()but not both. - with overloaded constructors, the last one in the hierarchy is responsible for invoking a superclass constructor.
- if we don't provide an invocation statement then the compiler inserts a
super()implicitly, it will be added in a constructor that doesn't invoke a overloaded constructor. - if for any reason a superclass constructor can not be invoked then it'll lead to a compiler error.
class User { // User() {} // fix 1 User(int id) {} } class Staff extends User { Staff(int id) { // super(id); // fix 2 } }
- there are two ways to prevent inheritance:
- by making the class
final(not extendible but instantiable e.g.,Stringclass) - by making the constructor
private(neither extendible nor instantiable e.g.,Mathclass)
- by making the class
- the reason why making the constructor
privateprevents inheritance is because theprivateaccess modifier makes the constructor private to the class and so it can not be invoked from the subclass which means constructor chaining is not possible and hence the subclass can not be created.
Day 25 ↑
abstractclasses are non-instantiable, but defines common protocol for subclasses.
abstract class Syntax { ... }
- like an abstract class an abstract method also involves inserting the keyword
abstractin the method declaration.- it doesn't have a body.
- must be overridden (which also means that
abstractmethods can not bestatic)
abstractmethod →abstractclassabstractclass → any method- a subclass can also be
abstractand it need not overrideabstractmethods. - if a subclass is non-abstract then it must override all of the unimplemented abstract methods.
- an abstract class can also have a constructor. However, this constructor is only accessible from a subclass constructor as it is not possible to instantiate an abstract class.
- if we do not include a constructor in an abstract class (which is the typical case), then compiler inserts a no-arg constructor implicitly just like in the case of a normal class. And this implicitly created constructor will also be invoked from the subclass as part of constructor chaining process and this constructor will in turn invoke the superclass constructor, i.e., includes a
super(). So, nothing is different from the regular superclass & subclass scenario. - in general, the term "type" is often used to refer a either a
classor aninterface. - prior to Java 8,
interfacecould only have public abstract methods but since Java 8 onwards aninterfacecan have concrete methods. - interfaces will not have any state i.e., they do not have instance variables or constructors which makes them non-instantiable.
- we can implement multiple interfaces but can only inherit one (as Java doesn't support Multiple Inheritance). Moreover an interface can have multiple subclasses from multiple packages.
- an
interfaceis implicitly abstract.
public interface InterfaceName { // or `public abstract interface InterfaceName` /** * static final fields * abstract methods * concrete/default methods (from Java 8 onwards) * static methods (from Java 8 onwards) * nested classes or interfaces */ // Note: // 1. all the above members are implicitly `public` and can't be `private` or `protected` // (from Java 9 onwards we can have `private` concrete methods) // 2. in case of abstract methods, `abstract` is implicit (no need to use the `abstract` keyword) // 3. variables are `public`, `static` and `final` by default // 4. if `public` is omitted from the interface, then all members will become default rather than `public` }
- interfaces are imported just like classes.
- a class implementing an interface is a subtype of that interface due to which the following is possible:
Interface obj = new Class(); Class obj = new Class();
- an interface can only be a reference type and it can never be an object type.
Interface obj = new Interface(); // not possible
Day 26 ↑
- like a class, an interface can also extend another interface (it can me more than one). Note that a class implementing the sub-interface has to implement all abstract methods declared in both the sub as well as the super-interfaces. For example,
ArrayListimplements abstract methods from bothListas well asCollectioninterfaces.
public interface List extends Collection { ... }
- a class can only implement an interface but it can not extend an interface.
- unlike classes, an interface can extend multiple interfaces.
public interface BlockingDeque extends BlockingQueue, Deque { ... }
- we should prefer interfaces over abstract classes.
- we should refer to objects by their interfaces i.e., whenever possible try to use an interface as a reference type in all kinds of variable declarations and also use them as method return types.
void foo(ArrayList list) { // we can invoke this method with an `ArrayList` only // i.e., we can not pass another similar implementation } foo(new ArrayList()); void bar(List list) { // as `List` is an interface, we can pass any type which implements it } bar(new ArrayList()); bar(new LinkedList());
Day 27 ↑
- marker interfaces dont't have any methods and are used to mark or tag a class of having a certain property. Below are few examples of marker interfaces in the Java API:
java.util.RandomAccess: any class implementing this interface declares that it allows fast random access of its elements.ArrayListis once such class which implements it.java.io.Serializable: any class implementing this interface declares that it allows its objects to be serialized, which means that the objects can be converted into byte streams, which can be saved to a file or transmitted over a network. This process is useful for saving the state of an object and for transferring objects between different applications or systems.java.lang.Cloneable: by implementing this interface a class declares that its objects can return their clones i.e., a duplicate object having the same state as the original.
class CloneableClass implements Cloneable { public CloneableClass clone() { try { return (CloneableClass) super.clone(); // invokes `Object.clone()` but return type is `Object` } catch (CloneNotSupportedException e) {} return null; } } // Note: `clone()` in `Object` is protected, so something like above is required to support cloning// another example of a marker interface in action Collections.shuffle(List list) { if (list instanceof RandomAccess) { // apply shuffle directly } else { // 1. copy elements to an array // 2. shuffle array // 3. dump array back into list } }
- to use the
clone()method, a class must implement theCloneableinterface. If a class attempts to callclone()on an object that does not implementCloneable, aCloneNotSupportedExceptionwill be thrown at runtime. - the
clone()method performs a shallow copy, which means it creates a new object with the same contents as the original object, but the contents themselves are not cloned. Instead, the new object contains references to the same objects as the original. Therefore, any changes made to the objects referred to by the new object will also affect the original object and vice versa.
class A { B b; A() { b = new B(); } } class B {}A a1 = new A(); A a2 = a1.clone(); // the `B` instance in `a1` and `a2` will be the same.
- the
defaultkeyword is used in interfaces to define a default implementation for a method (from Java 8 onwards). The method can be called from any class that implements the interface, but can be overridden by any implementing class if necessary. Also, these are instance methods. - if a class extends an class with some method and implements an interface with some default method, and both methods have the same signature, then the definition in the super-class has higher precedence over the default method in the super-interface. The default method can be invoked by using
InterfaceName.super.method(). - a default method can be re-abstracted in a sub-interface or in an abstract sub-class.
- we can not use
finalorsynchronizedkeywords with default methods.
Day 28 ↑
- below are few benefits of default methods:
- interface evolution (main purpose)
- default implementation can be overridden
- eliminate utility classes (e.g.,
list.sort()instead ofCollection.sort(List)) - allow interface to stay as functional interface (an interface with exactly one abstract method)
- a functional interface will remain as a functional interface even if we add a
defaultorstaticmethod to it. - unlike static methods in classes, static methods in interfaces are not inherited.
- unlike classes, static methods in interfaces can only be invoked via interface name but not from an object reference.
- JIT (Just-In-Time) compilation is a method used by the Java Virtual Machine (JVM) to improve the performance of Java programs. The JIT compiler analyzes the bytecode of a Java program as it is running, and translates the frequently executed portions of the code into native machine code, which can be executed directly by the computer's processor.
- A Java program is loaded into the JVM and the bytecode is interpreted by the JIT compiler.
- As the program is running, the JIT compiler monitors the bytecode and identifies frequently executed sections of code.
- The JIT compiler then translates these frequently executed sections of bytecode into native machine code.
- The native machine code is then executed by the processor, resulting in improved performance of the program.
- As the program continues to run, the JIT compiler may continue to identify and compile more sections of code.
- JIT compilation can significantly improve the performance of Java programs, but it can also add overhead to the program, as the JIT compiler needs to monitor and analyze the bytecode.
Day 29 ↑
- an exception is simply an object of
java.lang.Throwableor one of it's subclasses. - the
throwskeyword is used in method signatures to declare that the method may throw certain types of exceptions. When a method throws an exception, it essentially indicates that something went wrong during the execution of the method, and it cannot be handled within the method itself. Instead, the exception is "thrown" back to the calling method, which can either handle the exception or propagate it further down the call stack. If themainmethod alsothrowsthe exception then it will not be handled, asmainis in the bottom of the call stack. - The
throwskeyword is followed by one or more exception classes, separated by commas. - The
throwskeyword is not used to actually throw an exception; it is only used to declare that a method may throw an exception of a certain type. To actually throw an exception, we use thethrowkeyword followed by an instance of the exception class.
import java.io.IOException; import java.io.FileNotFoundException; void example() throws IOException, FileNotFoundException { if (someCondition) throw new IOException("An I/O error occured."); }
- To avoid using the
throwskeyword, we can handle the exception using a try-catch block. Instead of declaring the exception using thethrowskeyword, we can surround the code that might throw an exception with atryblock, and catch the exception using acatchblock. By doing this, we can handle the exception ourselves instead of propagating it down the call stack. Also note that we can throw the exception from inside the catch block as well.
void example() { try { // code that might throw an exception } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { throw e; } finally { // will run if an checked/unchecked exception is generated } // note: sub-class exception catch should be before super-class // else it'll lead to an unreachable catch block compiler error }
Exceptionobjects can be referenced polymorphically.
void example() throws IOException, FileNotFoundException { ... }as FileNotFoundException is a subclass of IOException, we can do something like:
void example() throws IOException { ... }
Day 30 ↑
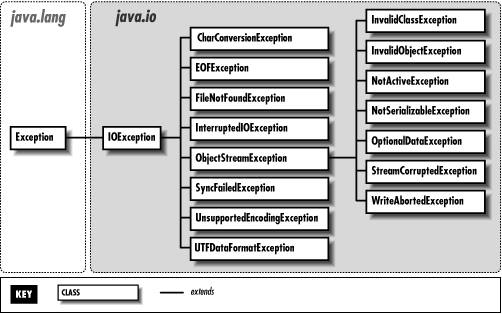
java.lang.Throwableis the super-class of all exception related classes and errors.
┌──────────────── Throwble ──────────────────┐ ▼ ▼ ┌────────────── Exception ────────────────┐ Error ▼ ▼ ▼ │ IOException AWTException RunTimeException ├─VirtualMachineError │ │ │ ├─FileNotFoundException ├─NullPointerException └─LinkageError │ │ │ └─EOFException ├─ArrayOutOfBoundsException └─NoClassDefFoundError │ ├─IllegalArgumentException │ ├─ClassCastException │ └─NumberFormatException
- exceptions are classified into two categories:
- Checked exceptions are those that the compiler checks at compile-time, and requires the programmer to handle or declare them using the
throwskeyword. If a method can potentially throw a checked exception, the programmer must either handle it using a try-catch block, or declare it using thethrowskeyword in the method signature. - Unchecked exceptions, on the other hand, are not checked by the compiler at compile-time, and don't require the programmer to handle or declare them. They are usually caused by programming errors, such as dividing by zero or accessing a null reference, and can be avoided by writing correct code.
- Checked exceptions are those that the compiler checks at compile-time, and requires the programmer to handle or declare them using the
- some common examples of checked exceptions in Java include
IOException,SQLException, andClassNotFoundException, while common examples of unchecked exceptions includeNullPointerException,ArrayIndexOutOfBoundsException, andArithmeticException. - below are couple of rules when it comes to exceptions & method overriding:
- If the super class method does not declare an exception, then the overriding method in the subclass cannot declare a checked exception, but can declare an unchecked exception.
- If the super class method declares a checked exception, then the overriding method in the subclass can declare same exception or a subclass exception or no exception at all, but cannot declare parent exception.
- If the super class method declares an unchecked exception, then the overriding method can declare any unchecked exception or no exception at all, but cannot declare a checked exception.
- a
tryblock must be accompanied by at least onecatchblock orfinallyblock.
┌─────No─────Exception?─────Yes───────┐ ▼ ▼ - try Skip rest of try - finally │ - code after finally │ ▼ ┌──Yes──Exception handler?──No──┐ ▼ ▼ - catch - finally, but not code after it - finally - switch control to invoking method - code after finally - repeat until matching handler is found
- before Java 7, resources such as file I/O streams had to be explicitly closed in a finally block. Below is a standard template of what was done before Java 7:
FileInputStream in = null; try { in = new FileInputStream(filename); // read data } catch (FileNotFoundException e) { ... } finally { try { if (in != null) in.close(); } catch (IOException e) { ... } }
- "try with resources" block is a feature introduced in Java 7 that simplifies the process of working with resources that must be closed after use, such as files, streams, and database connections. It allows the developer to declare and initialize the resource inside the
trystatement, and the resource will be automatically closed when the block exits, regardless of whether an exception is thrown. The resource created withintryparenthesis is implicitlyfinal, so it can not be reassigned within thetryblock. - multiple resources can also be created within the
tryparenthesis and must be separated using ;. The resources are created sequentially, once the try-catch block is evaluated the resources are closed in the reverse order.
try (FileInputStream in = new FileInputStream(filename); FileOutputStream out = new FileOutputStream(filename)) { // read data } catch (FileNotFoundException e) { // handle the exception } catch (IOException e) { ... }
- any resources that we create in the parenthesis must implement
java.lang.AutoCloseableor one of it's sub-interfaces. It has only one method i.e.,close(). - this
tryblock need not have acatchor afinallyprovided that the code within the block and the overriddenclose()method does not throw an exception.
Day 31 ↑
- in a multi-layered system where we have higher level methods invoking lower level methods and a higher level method catches an exception from a lower level, then according to Effective Java, instead of propagating that exception we should throw a new exception that is more meaningful in terms of higher level abstraction. This way the higher level is not polluted with lower level details, and this idiom is referred to as Exception translation. But in some cases the lower level exception might be appropriate to higher levels, in that case it is fine to propagate them.
- exception chaining, also known as exception wrapping, is a technique used to associate one exception with another. It is a way to provide additional context about an exception and its cause. It is useful when an exception occurs deep within the call stack, but the root cause of the problem may be higher up in the stack. By wrapping the original exception with another one, we can pass the original exception up the call stack while providing more context about what caused it.
- to chain exceptions, we can pass the original exception to the constructor of a new exception. This new exception becomes the "wrapper" exception, and the original exception becomes its cause. We can then throw the wrapper exception, which includes information about both the original exception and the reason why it occurred.
- in this example, if an
IOExceptionoccurs, we wrap it in a newRuntimeExceptionand pass the original exception as its cause. When theRuntimeExceptionis thrown, it includes information about the original exception and the reason why it occurred. This can be useful for debugging and troubleshooting issues in a system.
try { // Some code that may throw an exception } catch (IOException e) { // Wrap the original exception with a new exception throw new RuntimeException("Error occurred while processing data", e); }
Day 32 ↑
- the
assertkeyword takes a boolean expression as an argument and throws anAssertionErrorif the expression evaluates tofalse. If the expression istrue, the program continues to execute normally.
public int divide(int dividend, int divisor) { assert divisor != 0 : "Divisor cannot be zero"; return dividend / divisor; }
assertstatements should not be used for program logic or error handling that are essential for the correct functioning of the program. Instead, they should be used as a tool for testing and debugging during development.- assertions can be enabled or disabled (default) at class or package level by using
-ea/-enableassertionsor-da/-disableassertionsflags respectively.
java -ea:exceptions.assertions.A exceptions.assertions.A java -ea -da:exceptions.assertions.D exceptions.assertions.A # enabled for every class except assertions in D java -ea -da:exceptions.assertions... exceptions.assertions.A # enabled for every class except classes in the (sub)packages
- the Collections Framework can be divided into two parts as follows. All the implementations below are
Serializable,Cloneable, most allownulland none of them areSynchronizedi.e., they can be accessed by multiple threads at the same time.
┌──────────┐ ┌─────────────────────────────┤Collection├───────────────────────┐ │ └────┬─────┘ │ │ │ │ ┌─▼─┐ ┌─▼──┐ ┌──▼──┐ ┌───────┤Set│◄─────────┐ ┌────►│List│◄──────┐ ┌───┤Queue│ │ └──▲┘ │ │ └──▲─┘ │ │ └───▲─┘ ┌────▼────┐ │ │ │ │ │ │ │ │SortedSet│ │ │ │ │ │ │ │ └────┬────┘ │ │ │ │ │ ┌──▼──┐ │ │ HashSet LinkedHashSet ArrayList Vector LinkedList──►│Deque│ PriorityQueue ┌────▼───────┐ └──▲──┘ │NavigableSet│ │ └────▲───────┘ │ │ │ │ │ TreeSet ArrayDeque┌───┐ ┌────────►│Map├────────┐ │ └▲─▲┘ ┌────▼────┐ │ │ │ │SortedMap├─────┐ │ │ │ └─────────┘┌────▼───────┐ │ │ │ │NavigableMap│ │ │ └───────────┐ └────▲───────┘ │ │ │ │ HashTable LinkedHashMap HashMap TreeMap
Vector,StackandHashtableare legacy implementations which support synchronization, however it is recommended to not use them anymore as synchronization slows things down, instead useArrayList,ArrayDequeandHashMaprespectively.Collectionhas various sub-interfaces but it has only one direct sub-class i.e.,AbstractCollectionwhich provides the skeletal implementation of it.
Day 33 ↑
- the
java.util.Collectioninterface includes several methods common to all collections which can be broadly classified into 3 categories:- Basic Operations
- Bulk Operations
- Array Operations
public interface Collection<E> extends Iterable<E> { // Basic Operations boolean add(E element); // optional boolean remove(Object element); // optional boolean contains(Object element); int size(); boolean isEmpty(); Iterator<E> iterator(); // Bulk Operations boolean addAll(Collection <? extends E> c); // optional boolean removeAll(Collection<?> c); // optional boolean retainAll(Collection<?> c); // optional boolean containsAll(Collection<?> c); void clear(); // optional // Array Operations Object[] toArray(); <T> T[] toArray(T[] a); // e.g., String[] a = c.toArray(new String[0]); } // Note: "optional" means the subclass need not support it // i.e., it will define an empty method that will throw an UnsupportedOperationException.
- the
java.util.Listinterface is useful when sequence/positioning matters. It models a resizable linear array with indexed access which can have duplicates.
public interface List<E> extends Collection<E> { // Positional Operations E get(int index); E set(int index, E element); // optional void add(int index, E element); // optional boolean add(E element); // optional E remove(int index); // optional boolean addAll(int index, Collection<? extends E> c); // optional // Searching Operations int indexOf(Object o); int lastIndexOf(Object o); // Iteration Operations ListIterator<E> listiterator(); ListIterator<E> listiterator(int index); // Range-view Operations List<E> subList(int fromIndex, int toIndex); }
java.util.ArrayListis an array implementation of theListinterface.
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
- the size of the internal array in
ArrayListincreases by 50% when it is full by default. This means that if the current capacity of theArrayListis N, then the new capacity will be N + (N/2). The capacity of anArrayListcan be increased by using theensureCapacity()method, useful when adding a large number of elements as it may reduce the amount of incremental reallocation. - during iteration using a for-each loop, removing an element will lead to
ConcurrentModificationException.
for (int element : list) { if (element == 9) list.remove(9); }
Collectionextendsjava.lang.Iterablewhich enables any of its objects to be used in for-each loops.Iterableis aninterfacewhich has only oneabstractmethod callediterator(), which the sub-class has to implement. Internally for-each invokes this method to iterate the elements of theCollection.
public interface Iterable<T> { Iterator<T> iterator(); default void forEach(Consumer<? super T> action) { ... } default Spliterator<T> spliterator() { ... } }
ArrayListhas a nested class which implementsjava.util.Iterator, an instance of that nested class is returned wheniterator()is invoked.
public interface Iterator<E> { boolean hasNext(); E next(); void remove(); default void forEachRemaining(Consumer<? super T> action) { ... } }
- It allows us to remove an element during iteration.
Iterator<Integer> it = list.iterator(); while (it.hasNext()) { int element = it.next(); if (element == 9) it.remove(); } list.forEach(System.out::println);
Day 34 ↑
- to implement an iterable data structure (example), we need to:
- implement
Iterableinterface along with its methods in the said Data Structure. - create an Iterator class which implements
Iteratorinterface and corresponding methods.
- implement
class CustomDataStructure implements Iterable<> { // code for data structure public Iterator<> iterator() { return new CustomIterator<>(this); } } class CustomIterator<> implements Iterator<> { // constructor CustomIterator<>(CustomDataStructure obj) { // initialize cursor } // Checks if the next element exists public boolean hasNext() { ... } // moves the cursor/iterator to next element public T next() { ... } // Used to remove an element. Implement only if needed public void remove() { // default throws UnsupportedOperationException. } } // Note: the Iterator class can also be implemented as an inner class // of the Data Structure class as it won’t be used elsewhere.
ListIteratorextendsIteratorand provides additional functionality. WithIteratorwe can only remove elements but withListIteratorwe can additionally add and replace elements. Moreover, we can both iterate both forwards as well as backwards.
public interface ListIterator<E> extends Iterator<E> { void add(E e); void set(E e); void remove(); boolean hasNext(); E next(); boolean hasPrevious(); E previous(); int nextIndex(); int previousIndex(); }
Day 35 ↑
java.util.LinkedListis a doubly linked list implementation ofList&Dequeinterfaces.
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
java.util.Queueis a collection designed for holding elements prior to processing. Besides basicCollectionoperations, queues provide additional insertion, extraction, and inspection operations. Each of these methods exists in two forms: one throws an exception if the operation fails, the other returns a special value (either null or false, depending on the operation). The latter form of the insert operation is designed specifically for use with capacity-restrictedQueueimplementations.
public interface Queue<E> extends Collection<E>┌─────────┬──────────────────┬─────────────────────────────────┐ │ │ Throws exception │ Returns special value │ ├─────────┼──────────────────┼─────────────────────────────────┤ │ Insert │ add(e) │ offer(e) ~ false │ │ Remove │ remove() │ poll() ~ null if queue is empty │ │ Examine │ element() │ peek() ~ null if queue is empty │ └─────────┴──────────────────┴─────────────────────────────────┘
java.util.Dequeis a linear collection that supports element insertion and removal at both ends. Methods are provided to insert, remove, and examine the element. Each of these methods exists in two forms: one throws an exception if the operation fails, the other returns a special value (eithernullorfalse, depending on the operation). The latter form of the insert operation is designed specifically for use with capacity-restrictedDequeimplementations.
public interface Deque<E> extends Queue<E>
- when a deque is used as a queue, FIFO (First-In-First-Out) behavior results. Elements are added at the end of the deque and removed from the beginning. The methods inherited from the
Queueinterface are precisely equivalent toDequemethods as indicated by the following table:
┌──────────────┬─────────────────────────┐ │ Queue Method │ Equivalent Deque Method │ ├──────────────┼─────────────────────────┤ │ add(e) │ addLast(e) │ │ offer(e) │ offerLast(e) │ │ remove() │ removeFirst() │ │ poll() │ pollFirst() │ │ element() │ getFirst() │ │ peek() │ peekFirst() │ └──────────────┴─────────────────────────┘
- Deques can also be used as LIFO (Last-In-First-Out) stacks. This interface should be used in preference to the legacy
Stackclass. When a deque is used as a stack, elements are pushed and popped from the beginning of the deque.Stackmethods are precisely equivalent toDequemethods as indicated in the table below:
┌──────────────┬─────────────────────────┐ │ Stack Method │ Equivalent Deque Method │ ├──────────────┼─────────────────────────┤ │ push(e) │ addFirst(e) │ │ pop() │ removeFirst() │ │ peek() │ peekFirst() │ └──────────────┴─────────────────────────┘
java.util.ArrayDequeis a resizable-array implementation of the Deque interface. Array deques have no capacity restrictions; they grow as necessary to support usage.
public class ArrayDeque<E> extends AbstractCollection<E> implements Deque<E>, Cloneable, Serializable
- below are various ways to create an
ArrayDeque:ArrayDeque()ArrayDeque(int)ArrayDeque(Collection)
ArrayDequeis faster thanLinkedListas a queue.- unlike
List,java.util.Setinterface does not add any new methods on top of what it inherits from theCollectioninterface. However due to the fact that it does not allow duplicates, it places some additional requirements on some of the inherited methods and also the constructors. java.util.HashSetis a hash table based implementation of theSetinterface. Internally, it uses aHashMap, but sinceHashSetstores only individual objects those objects will be stored as keys while an empty object (an instance of theObjectclass) will be stored as a value. It allows onenullvalue.
Day 36 ↑
- when we override the
equals()method in a class, we are essentially defining a custom way to compare objects of that class for equality. If two objects are considered equal based on theequals()method, they should have the same hash code value as well. If the hash code values of two objects are different, then theCollectionclasses will assume that they are not equal and can potentially store both of them, leading to duplicate entries. Therefore, it is recommended to override thehashCode()method in a way that is consistent with theequals()method to avoid this problem (example). - for
nullkeys, thehasCodeis always 0. -java.util.LinkedHashSetis an implementation of theSetinterface and it is similar toHashSetin that it stores elements in a hash table. However,LinkedHashSetalso maintains a doubly linked list of the elements in insertion order. This means that the order in which elements are added to the set is preserved, and it can be traversed in that order using the iterator.
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, Serializable
- the
LinkedHashSetclass also overrides theadd()andaddAll()methods of theHashSetclass to maintain the insertion order while adding elements to the set. When an element is added to the set, it is first hashed to determine its bucket, and then it is inserted at the end of the bucket's linked list. If the element is already in the set, it is moved to the end of the list. java.util.SortedSetandjava.util.NavigableSetdefine sets that are sorted in a specific order defined by a comparator or the natural ordering of elements.- the
SortedSetinterface provides additional methods that allow for accessing and manipulating elements based on their position in the set, such assubSet(),headSet(), andtailSet(). - the
NavigableSetinterface extends theSortedSetinterface and provides additional methods for navigating the set based on the ordering of the elements, such aslower(),floor(),ceiling(), andhigher(). These methods return elements that are strictly less than, less than or equal to, greater than or equal to, and strictly greater than a given element, respectively. - both
SortedSetandNavigableSetare implemented by thejava.util.TreeSetclass, which uses a red-black tree to maintain the elements in sorted order. This allows for efficient operations on the set, such as finding the smallest or largest element, or finding elements within a specific range. - the
java.lang.Comparableinterface is used to provide a default natural sorting order for a class. A class that implements theComparableinterface must implementcompareTo(), which compares the current object with the specified object and returns a negative integer, zero, or a positive integer if the current object is less than, equal to, or greater than the specified object, respectively. ThecompareTomethod is used by sorting algorithms likeArrays.sort()andCollections.sort(). - the
java.util.Comparatorinterface is used to provide a custom sorting order for a class. A class that implements theComparatorinterface must implementcompare(), which compares two objects and returns a negative integer, zero, or a positive integer if the first object is less than, equal to, or greater than the second object, respectively. Thecomparemethod is used as an argument to sorting algorithms likeArrays.sort()andCollections.sort()to provide a custom sorting order. - the difference between
ComparableandComparatoris thatComparableprovides a natural ordering of objects and is implemented by the object being sorted, whereas Comparator provides an external ordering of objects and is implemented by a separate class (example).
Day 37 ↑
- not all
Collectionclasses come with a skeletal/abstract class which the correspondingCollectionclass extends. But all these abstract classes extendjava.util.AbstractCollection. - the skeletal classes provided by Java are optional and can be used as a starting point for implementing a new collection class. However, many of the built-in collection classes do not extend the skeletal classes. For example,
ArrayListandLinkedListdo not extendAbstractList, andHashSetandLinkedHashSetdo not extendAbstractSet. - unlike
Collectioninterface,java.util.Mapinterface does not extend theIterableinterface but the elements can still be iterated usingentrySet().
public interface Map<K, V> { // Basic Operations V put(K key, V value); V get(Object key); V remove(Object key); boolean containsKey(Object key); boolean containsValue(Object value); int size(); boolean isEmpty(); // Bulk Operations void putAll(Map<? extends K, ? extends V> m); void clear(); // Collection View Operations (can not invoke add/addAll but remove operations are possible) Set<K> keySet(); Collection<V> values(); Set<Map.Entry<K,V>> entrySet(); // can be used for iterating the Map public interface Entry { K getKey(); V getValue(); V setValue(V value); } }
- note that in case of
keySet()aSetwas returned whereas in case ofvalues()aCollectionis returned as there can be dupicate values. entrySet()returns a set view of all the mappings in theMap, and each mapping is an instance of the nested interfaceEntry.- we should be careful when using mutable objects as keys, as any modification to key may lead to modification of the
hashCode. For example if we are using aListas a key, then if we modify theListthen it'shashCodewill also change. Below isAbstractList'shashCode()definition:
public int hashCode() { int hashCode = 1; for (E e : this) hashCode = 31 * hashCode + (e == null ? 0 : e.hashCode()); return hashCode; }
- similar to
LinkedHastSet,java.util.LinkedHashMappreserves insertion order using a doubly linked list. It permitsnulland exactly onenullkey. - iteration speed of
LinkedHashSet/LinkedHashMapis slightly faster than that ofHashSet/HashMap. (Read more...) LinkedHashMapcan be used as a LRU Cache (example).java.util.TreeMapis a class that implements theSortedMapinterface using red-black tree to store its elements. The elements are sorted in ascending order based on their natural ordering of keys or a specified comparator. It also implements theNavigableMapinterface, which provides navigation methods for accessing the keys and values in a sorted map.- streams are of two types:
- Byte Streams (
InputStream,OutputStream) - Character Streams (
Reader,Writer)
- Byte Streams (
java.io.InputStreamandjava.io.OutputStreamare the base abstract classes for all byte oriented input/output streams.java.io.Readerandjava.io.Writerare the base abstract classes for all character oriented input/output streams.
Day 38 ↑
InputStreamis used to read data in groups of 8 bit bytes.abstract int read() throws IOExceptionreads 1 byte and returns asintbetween 0 & 255, and returns -1 if end of stream is detected.int read(byte[] b, int off, int len) throws IOException- the first byte read is stored into element b[off], the next one into b[off+1], and so on. The number of bytes read is, at most, equal to len. Let k be the number of bytes actually read; these bytes will be stored in elements b[off] through b[off+k-1], leaving elements b[off+k] through b[off+len-1] unaffected.
- returns bytes read or -1 if end if stream is detected
- internally it repeatedly invokes
read() int read(byte[] b) throws IOExceptioncallsread(b, 0, b.length)
- all read calls are blocking i.e., when data is unavailable the method would wait until the data is available.
OutputStreamis used to write data in groups of 8 bit bytes.abstract void write(int) throws IOExceptionwrites only the least significant byte and remaining 24 bits are discarded.void write(byte[] b, int off, int len) throws IOExpection- writes len bytes from the specified byte array starting at offset off to this output stream. The general contract for write(b, off, len) is that some of the bytes in the array b are written to the output stream in order; element b[off] is the first byte written and b[off+len-1] is the last byte written by this operation.
- repeatedly invokes
write() void write(byte[] b) throws IOExceptioncallswrite(b, 0, b.length)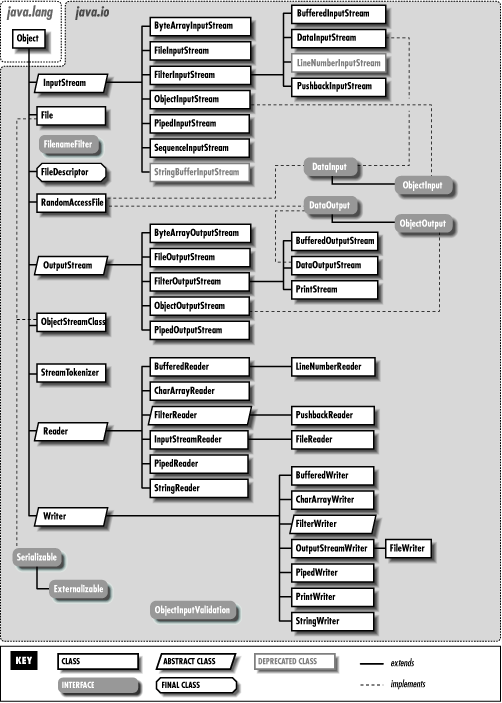
java.io.FileInputStream&java.io.FileOutputStreamare used to read/write bytes from/to files respectively. These classes extendInputStreamandOutputStreamand provide implementations forread()andwrite().FileOutputStream(String filename) throws FileNotFoundExceptioncreates a new file if the file does not exists, and overwrites the file if it exists. But inFileInputStreamif a file does not exists then it will throw anFileNotFoundExceptionas there is no point creating an empty file and reading nothing from it.FileOutputStreamthrowsFileNotFoundExceptionin the following cases:- file cannot be created for writing
- file is a directory
- cannot be opened for any other reason
- the above classes' way of reading and writing data is inefficient as it reads/writes single byte at a time. Instead, reading/writing from/to a block of memory buffer and flushing all the data to the disk is more efficient. There are two specialized classes which allows us to do that, those are
java.io.BufferedInputStreamandjava.io.BufferedOutputStream.

