



Deepfakes are synthetic media in which a person in an existing image or video is replaced with someone else's likeness.
Dataset source: kaggle - Deepfake Detection Challenge
The 21st century’s answer to Photoshopping, deepfakes use a form of artificial intelligence called deep learning to make images of fake events, hence the name deepfake. Want to put new words in a politician’s mouth, star in your favourite movie, or dance like a pro? Then it’s time to make a deepfake. The AI firm Deeptrace found 15,000 deepfake videos online in September 2019, a near doubling over nine months. A staggering 96% were pornographic and 99% of those mapped faces from female celebrities on to porn stars. As new techniques allow unskilled people to make deepfakes with a handful of photos, fake videos are likely to spread beyond the celebrity world to fuel revenge porn.
Danielle Citron, a professor of law at Boston University, puts it: “Deepfake technology is being weaponised against women.” Beyond the porn there’s plenty of spoof, satire and mischief.
To address this problem, this repo demonstrates InceptionResnetv2 and VGG16 models to detect whether the video is real or deepfaked at a basic level.
Poor-quality deepfakes are easier to spot. The lip synching might be bad, or the skin tone patchy. There can be flickering around the edges of transposed faces. And fine details, such as hair, are particularly hard for deepfakes to render well, especially where strands are visible on the fringe. Badly rendered jewellery and teeth can also be a giveaway, as can strange lighting effects, such as inconsistent illumination and reflections on the iris.
Inception-ResNet-v2 is a convolutional neural network that is trained on more than a million images from the ImageNet database. The network is 164 layers deep and can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images. The network has an image input size of 299-by-299, and the output is a list of estimated class probabilities.

It is formulated based on a combination of the Inception structure and the Residual connection. In the Inception-Resnet block, multiple sized convolutional filters are combined with residual connections. The usage of residual connections not only avoids the degradation problem caused by deep structures but also reduces the training time. The figure shows the basic network architecture of Inception-Resnet-v2.
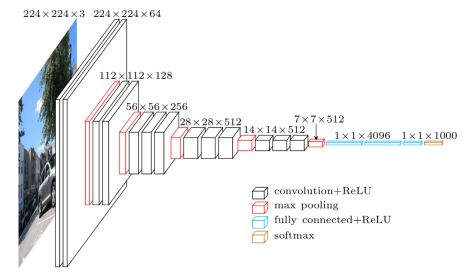
VGG16 is a convolution neural net (CNN ) architecture which was used to win ILSVR(Imagenet) competition in 2014. It is considered to be one of the excellent vision model architecture till date. Most unique thing about VGG16 is that instead of having a large number of hyper-parameter they focused on having convolution layers of 3x3 filter with a stride 1 and always used same padding and maxpool layer of 2x2 filter of stride 2. It follows this arrangement of convolution and max pool layers consistently throughout the whole architecture. In the end it has 2 FC(fully connected layers) followed by a softmax for output. The 16 in VGG16 refers to it has 16 layers that have weights. This network is a pretty large network and it has about 138 million (approx) parameters.

.gif?raw=true)
-
- Python
-
- Tensorflow
- OpenCV
- dlib (face detection library)