


💡 Monkey series projects:✨.
[CVPR'24] Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, Xiang Bai






TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Yuliang Liu, Biao Yang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, Xiang Bai


2024.4.13🚀 Sourced code for TextMonkey is released.2024.4.5🚀 Monkey is nominated as CVPR 2024 Highlight paper.2024.3.8🚀 We release the paper TextMonkey.2024.2.27🚀 Monkey is accepted by CVPR 2024.2024.1.3🚀 Release the basic data generation pipeline. Data Generation2023.12.16🚀 Monkey can be trained using 8 NVIDIA 3090 GPUs. See subsection train for details.2023.11.06🚀 We release the paper Monkey.
Monkey-Chat
| Model | Language Model | Transformers(HF) | MMBench-Test | CCBench | MME | SeedBench_IMG | MathVista-MiniTest | HallusionBench-Avg | AI2D Test | OCRBench |
|---|---|---|---|---|---|---|---|---|---|---|
| Monkey-Chat | Qwev-7B | 🤗echo840/Monkey-Chat | 72.4 | 48 | 1887.4 | 68.9 | 34.8 | 39.3 | 68.5 | 534 |
conda create -n monkey python=3.9
conda activate monkey
git clone https://github.com/Yuliang-Liu/Monkey.git
cd ./Monkey
pip install -r requirements.txtWe also offer Monkey's model definition and training code, which you can explore above. You can execute the training code through executing finetune_ds_debug.sh.
The json file used for Monkey training can be downloaded at Link.
ATTENTION: Specify the path to your training data, which should be a json file consisting of a list of conversations.
Inspired by Qwen-VL, we freeze the Large Language Model (LLM) and introduce LoRA into four linear layers "c_attn", "attn.c_proj", "w1", "w2" for training. This step makes it possible to train Monkey using 8 NVIDIA 3090 GPUs. The specific implementation code is in modeling_qwen_nvdia3090.py.
- Add LoRA: You need to replace the contents of
modeling_qwen.pywith the contents ofmodeling_qwen_nvdia3090.py. - Freeze LLM: You need to freeze other modules except LoRA and Resampler modules in
finetune_multitask.py.
Run the inference code:
python ./inference.py --model_path MODEL_PATH --image_path IMAGE_PATH --question YOUR_QUESTION
Demo is fast and easy to use. Simply uploading an image from your desktop or phone, or capture one directly. Demo_chat is also launched as an upgraded version of the original demo to deliver an enhanced interactive experience.
We also provide the source code and the model weight for the original demo, allowing you to customize certain parameters for a more unique experience. The specific operations are as follows:
- Make sure you have configured the environment.
- You can choose to use the demo offline or online:
- Offline:
- Download the Model Weight.
- Modify
DEFAULT_CKPT_PATH="pathto/Monkey"in thedemo.pyfile to your model weight path. - Run the demo using the following command:
python demo.py - Online:
- Run the demo and download model weights online with the following command:
python demo.py -c echo840/Monkey
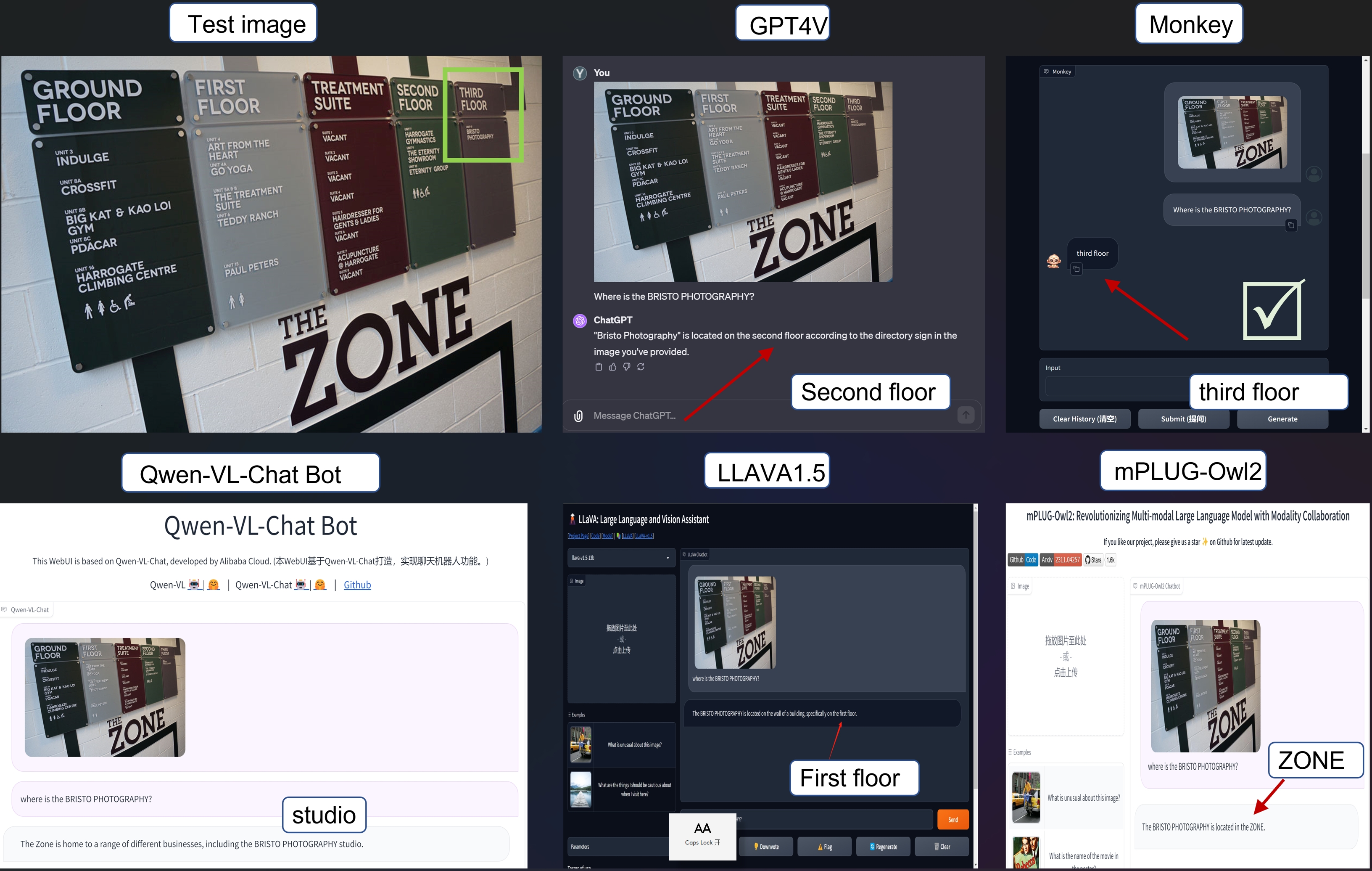
Before 14/11/2023, we have observed that for some random pictures Monkey can achieve more accurate results than GPT4V.
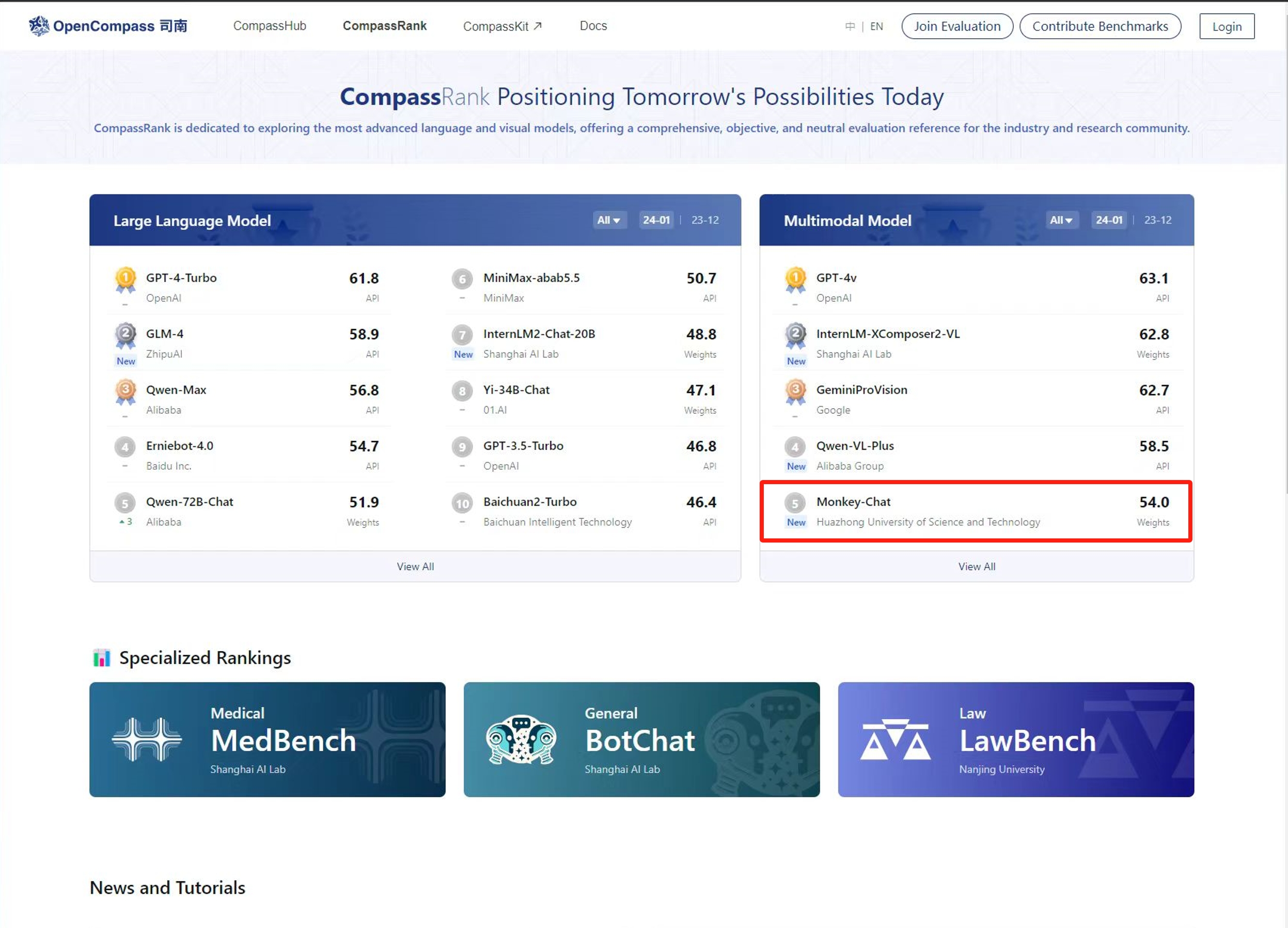
Before 31/1/2024, Monkey-chat achieved the fifth rank in the Multimodal Model category on OpenCompass.
The json file used for Monkey training can be downloaded at Link.
The data from our multi-level description generation method is now open-sourced and available for download at Link. Examples:

You can download train images from Train. Extraction code: 4hdh
You can download test images and jsonls from Test. Extraction code: 5h71
The images are from CC3M, COCO Caption, TextCaps, VQAV2, OKVQA, GQA, ScienceQA, VizWiz, TextVQA, OCRVQA, ESTVQA, STVQA, AI2D and DUE_Benchmark. When using the data, it is necessary to comply with the protocols of the original dataset.
We offer evaluation code for 14 Visual Question Answering (VQA) datasets in the evaluate_vqa.py file, facilitating a quick verification of results. The specific operations are as follows:
- Make sure you have configured the environment.
- Modify
sys.path.append("pathto/Monkey")to the project path. - Prepare the datasets required for evaluation.
- Run the evaluation code.
Take ESTVQA as an example:
- Prepare data according to the following directory structure:
├── data
| ├── estvqa
| ├── test_image
| ├── {image_path0}
| ├── {image_path1}
| ·
| ·
| ├── estvqa.jsonl
- Example of the format of each line of the annotated
.jsonlfile:
{"image": "data/estvqa/test_image/011364.jpg", "question": "What is this store?", "answer": "pizzeria", "question_id": 0}
- Modify the dictionary
ds_collections:
ds_collections = {
'estvqa_test': {
'test': 'data/estvqa/estvqa.jsonl',
'metric': 'anls',
'max_new_tokens': 100,
},
...
}
- Run the following command:
bash eval/eval.sh 'EVAL_PTH' 'SAVE_NAME'
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@inproceedings{li2023monkey,
title={Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models},
author={Li, Zhang and Yang, Biao and Liu, Qiang and Ma, Zhiyin and Zhang, Shuo and Yang, Jingxu and Sun, Yabo and Liu, Yuliang and Bai, Xiang},
booktitle={proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
year={2024}
}
@article{liu2024textmonkey,
title={TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document},
author={Liu, Yuliang and Yang, Biao and Liu, Qiang and Li, Zhang and Ma, Zhiyin and Zhang, Shuo and Bai, Xiang},
journal={arXiv preprint arXiv:2403.04473},
year={2024}
}Qwen-VL, LLAMA, LLaVA, OpenCompass, InternLM.
We welcome suggestions to help us improve the Monkey. For any query, please contact Dr. Yuliang Liu: ylliu@hust.edu.cn. If you find something interesting, please also feel free to share with us through email or open an issue. Thanks!