- citationsr
- Intro & setup
- Collect citation information/citations
- Collect fulltexts of citing documents
- Extract citation cases from citing documents
- Extract txt documents from pdf documents
- Collect metadata on citing documents and rename files accordingly
- Extract citation cases
- Analysis of citation cases
- References
The R package citationsr comprises functions that can be used to extract and analyze citation cases. When study A cites study B, it contains text fragments that refer to study B. We call study A a citing document and the text fragments it contains citation cases.
This readme serves to outline the methods applied in Bauer et al. (2016) with contributions from Paul C. Bauer, Pablo Barberá and Simon Munzert. The idea is to go beyond a simple and primitive analysis of impact as 'times cited'. The code is licensed under an Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license.
Disclaimer: We currently don't have time to work on this project and can't provide support. But we hope to develop it further at a later stage.
If you have questions please contact us at mail@paulcbauer.eu.
We are interested in questions such as the following:
- What do others write about a particular study? Which studies engage seriously with a particular study?
The tutorial illustrates how the code in the package citationsr can be used to investigate the impact of a particular study. The tutorial targets users that are very familiar with R. In principle, one may want to analyze the impact of a single or several studies. Most steps are common to both aims.
As described more extensively in Bauer et al. (2016) we need to pursue the following steps:
- Collect citation information, i.e. which works cite our study(ies) of interest
- Documents that cite a study are called citing documents, text passages within those documents that refer to a study are called citation cases.
- Collect the full text of citing documents
- Convert citing documents into raw text that can be analyzed
- Collect metadata on the citing documents
- Extract citation cases from citing documents
- Analyze citation cases
Below we present code that cycles through those steps. Essentially, we present the steps pursued in our study in which we investigate the impact of six highly cited studies in the fields of Political Science, Sociology and Economics.
Importantly, all of the above steps require methods that come with error. For intance Step 2, collecting fulltexts, contains error because we are not able to collect all fulltexts. Step 5, extracting citation cases, contains error because technically it is a challenging problem. Hence, the methods we present here are by no means perfect.
Right now you can install the package from github for which you need to install the devtools package.
install.packages("devtools")
library(devtools)
install_github("paulcbauer/citationsr")Create a working directory in which you store all the files linked to the analysis. We created a folder called analysis within which most of the analysis will take place.
In principle there are several ways to do this. Here we just present one approach relying on the Web of Science. Naturally, the citation information from the Web of Science is biased in various ways, e.g. it mostly contains journal publications and not books.
It is rather easy to program an R function that scrapes websites such as the Web of Science. However, since that is not legal, we present the manual way here. The Web of Science lets you download 500 citation records at a time and you can obtain them following the steps below. Unfortunately, you need access to the Web of Science (usually trough your university).
- Search for the study of interest
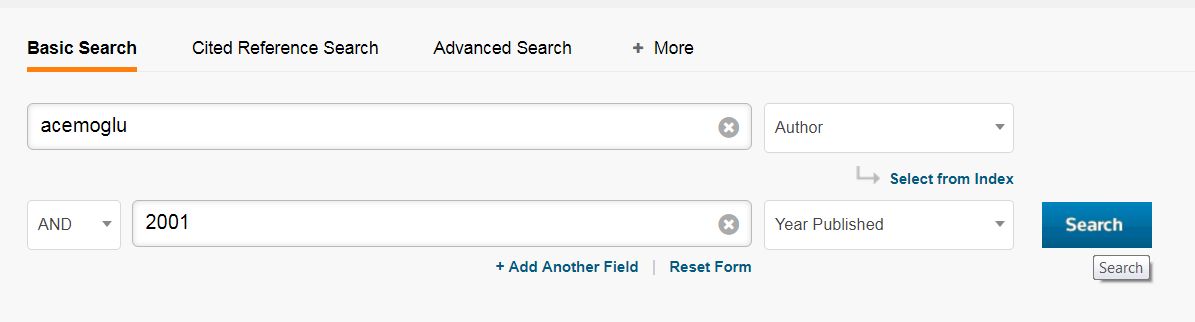

- Identify the right study in the list and click on 'Times Cited'


- Save citation records "Other File Formats"
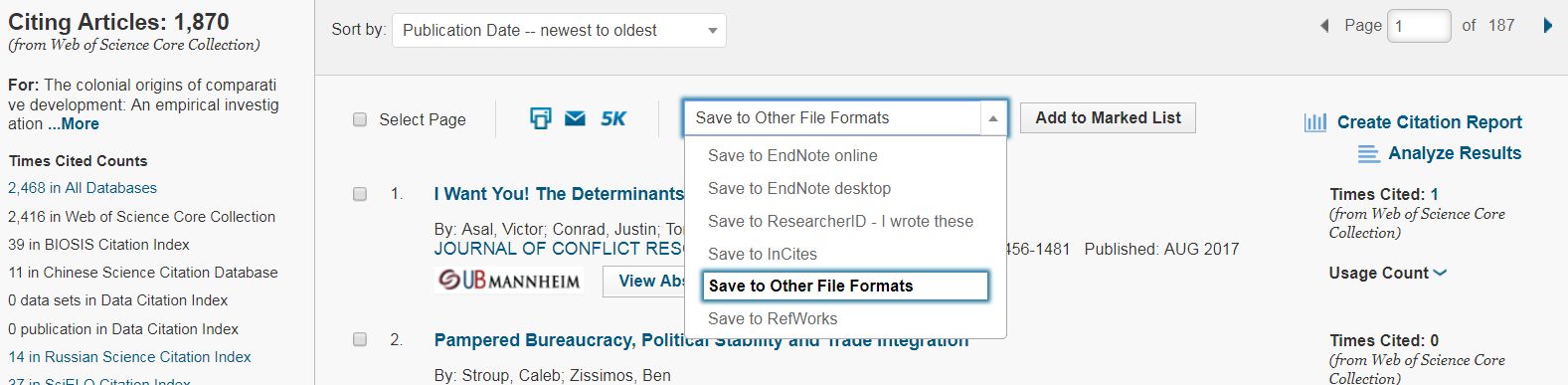

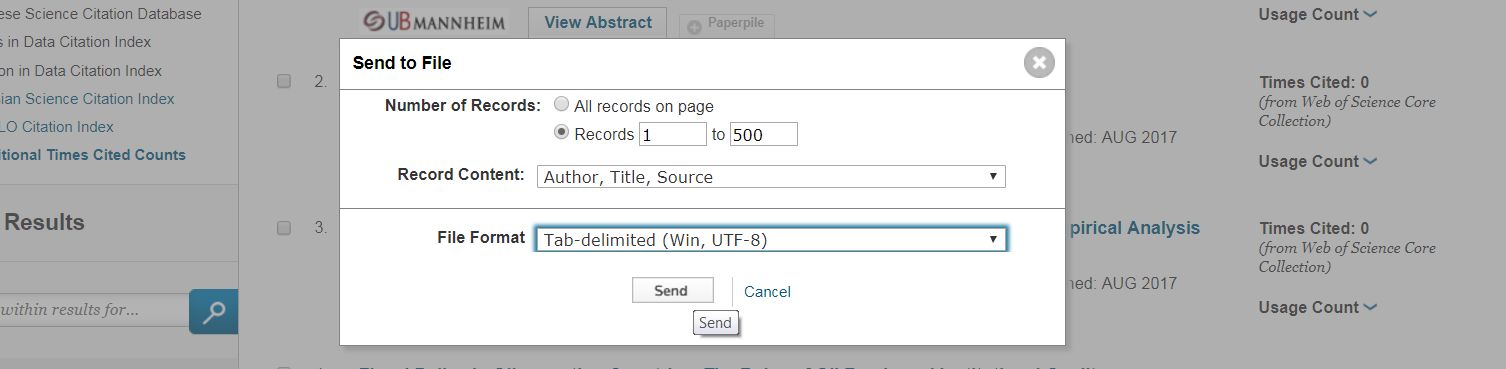
- Choose number of records (max. 500), record content ('Author, Title, Source') and File Format ('Tab-delimited') and click send.

- Change name of downloaded file with author names, year and pages of exported records and copy the files to the
analysis/citationsfolder.


- Your
analysis/citationsfolder should like below.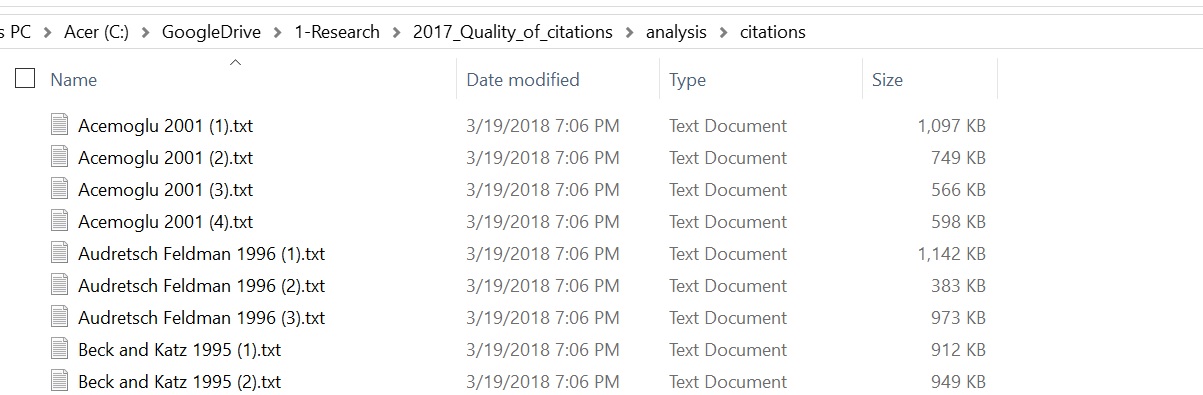

- Use the code below to merge and store the citation records in one single data frame
Again there are several ways to do this. We'll go with the third approach.
- Manual approach: Click & Save on Google Scholar
- Automated approach: Fulltext package
- Automated approach: Paperpile
Go to GoogleScholar. Search for you article of interest. Click on cited by. Go through the articles and download those that you can access through the links on the right. Potentially, you will get more articles then by going through the citations that you get from the web of knowledge. On the other hand it's increadibly laborious.
The fulltext package and the contained function ft_get() by Scott Chamberlain should be able to scrape fulltexts of articles if you feed it a set of dois.
Paperpile is a commercial reference manager (3 Euros/month for academics) that works together with Google Drive. The nice thing is that it includes a very PDF scraper (as other reference managers as well). Once you upload DOIs for the studies for which you want to collect fulltexts, paperpile does a good job at downloading them to your GoogleDrive.
To proceed we need two helper functions that are available in a package called paperpiler.
-
paperpiler::gen_ris()below takes a set of dois and generates a*.risfile that can be imported into paperpile. -
Once you have created the ris file called, e.g.
records.risyou can import that into paperpile. See the steps below in which you import the file and the corresponding records into a folder calledimpactanalysis. You might also want to label all records in that folder with a particular label, e.g.impactanalysisto keep track of them. Importantly, Paperpile only downloads articles onto your google drive that are accessible through your university network. -
Choose "Upload Files" in the "Add Papers" menu.

- Choose the "*.ris" files an click on "open".

- Check "Organize into a new folder" and give a name to the folder, e.g. "impactanalysis". Then click "Start upload".

- Click on the folder "Impactanalysis" and click on the "Select" menu on "All".

- In the "More actions..." menu click on "Auto-Update".

- Then you update auto-update so that paperpile fetches information on those articles using the DOIs. Importantly, publishers dislike it when you download to many articles in one batch. Take this into account as you don't want to block your university's access to those publishers. Thus, download only small batches of PDFs and potentially discuss with your library before you do that or contact the publisher directly. Paperpile provides the following warning message:
"You are about to start an automatic bulk download of 9428 papers. If too many papers in your library are from a single publisher, your computer might get temporarily blocked from access to the publisher's website. Also, if many of your papers have incomplete meta-data your computer might get blocked by Google Scholar because Paperpile make too many requests to find the missing data. Although temporary blocks are rare and not a big problem, please consider downloading the PDFs in smaller batches."

- Subsequently, you collect the PDFs which then sit in the paperpile folder on your computer. Click on the "More actions..." menu on "Download PDFs".

-
Once, you have pursued these steps all the PDFs will be stored in your Paperpile folder on your GoogleDrive. Now, we need to fetch those files and copy them to a folder in which you analyze them.
-
paperpiler::fetch_docs()relies on the dataframecitation_datathat we generated from the web of knowledge and searches through your paperpile directory. I tries to identify files through their title and if that does not work through an author/year combination. It's fuzzy so it may fetch more docs then necessary. -
Make sure that the PDF documents are in the folder you specified in the "to" argument after you collected their fulltexts.
Paperpile allows you to store several versions of an articles. Normally, these are marked with "(1)", "(2)" etc. in their file names. Use the code below to delete any duplicate files that you fetched from the Paperpile folder.
Skip this step. Sometimes it's a good idea to rename the PDFs files before you analyze them. The function below simply searches for all PDF documents in the folder and renames them from 1.pdf to *.pdf.
Now, we need to extract text from those PDFs to analyze them. Here you can use the extract_text() function. The argument from specifies the folder in which the documents are located. number can be omitted or specified to limit the number of documents for which you want to extract text (e.g. for testing extraction for a few documents starting with the first).
-
The function relies an an open-source PDF text extraction tool called "pdftotext.exe" from XPDF. Download the Xpdf tools for your system, extract the .zip file and copy
pdftotext.exe. You have to indicate the path topdftotext.exein theextract_text()function. -
You can rerun this function. Before extraction it will automatically delete all
*.txtthat are present in the folder specified into =. If the folder does not exist it will create it.
Above we started with citation data from the Web of Science. There might be cases where we just have text documents or PDFs but we don't have any more information on them. The function get_metadata() analyzes the text documents in the folder specified by from = and tries to identify them (relying on the DOIs the contain). Crossref does not like it if you scrape metada for too many docs at once. So ideally execute the function for batches of files be specifying start = and end =.
- Importantly, identifying articles through their text is a hard problem and may fail for several reasons such as...
- ...no DOI in the text
- ...other DOIs in the text
- ...DOI not recognized by crossref
- Beware: Crossref may limit the requests you can make. We included a possibility to restrict metadata collection to a subset of the files in the
doc_textfolder. Simply, by specifying the rank of the first end last file for which you would like to collect metadata throughstart =andend =.
If now strange encoding appears in your files you can safely ignore this encoding issues. However, sometimes this may be necessary. We worked on both Windows PCs and Macs and sometimes ran into encoding issues.
The extraction of citation cases works better in a .txt file in which the text is not interrupted by running heads, page number etc. Below we provide two functions that try to clean the text at least to some extent.
delete_refs_n_heads()deletes references and running headers (e.g. author names on every page). It relies on the metadata that was collected before throughget_metadata()- A file
deleted_running_headers.htmlis stored in your working directory that includes all the lines that were deleted from the .txt files.
- A file
clean_text()replaces any dots that are not punctuation marks among other things. For instance, it converts abbrevations, e.g. "No." to "NUMBER". It also produces a text without linebreaks.
The extract_citation_cases() function cycles through files ending on _processed.txt in the from folder and extracts citation cases. It writes both html (for easy lookup) and csv (for analyses later) to the to folder that are named according to the study whose impact we study, e.g. AcemogluJohnsonRobinson_2001_citation_cases.html and AcemogluJohnsonRobinson_2001_citation_cases.csv.
Above we only looked at a single study. In our paper we investigate the impact of six studies. We stored the information on those six studies - such as authors and publication year - in a text file called publicationdata.txt and load this information for a starter.
We loop over the info in publicationdata.txt and extract the citation cases below. For each of the six studies it produces html and csv files with the citation cases.
After citation case extraction we end up with a dataframe in which the rows are citations cases (in our case 6 dataframes for 6 studies). The columns are different variables that contain information such as...
document: Contains the path and name of the file that was subject to extractioncitation.case: Contains the extracted citation case/text fragmentyear: Contains the publication year of the citing documentnchar.citation.case: Contains the number of characters of the citation case
From hereon you can apply any methods you like to analyze the citation case data.
We also programmed some functions to automate the process of analysis.
- Start by creating one or several output folder in which you store the results of the analysis. Below we do so for a single study.
- The
analyze_citations()produces some simple analyses/graphs of the citation cases.
- The
topic_analysis()performs some topic analysis on the citation cases.
Just as we extracted the citation cases referring to several studies with a loop above we can also apply the two analysis functions within a loop.