Upravujte pouze soubor
ukol_12.py!
Cílem tohoto cvičení (kromě drobného opakování) je implementace algoritmu Counting Sort pro abecední řazení načteného textu. Při implementaci postupujte dle návodu níže. V případě nejasností se obraťte na svého cvičícího.
- Do modulu
ukol_12.pyimportujte balíčekos. - V dokumentaci zjistěte, pomocí jaké metody z balíčku
os.pathmůžeme zjistit, zda-li v pracovním adresáři existuje soubor s požadovaným názvem.
- Do modulu
ukol_12.pyimplementujte funkciread_data(). - Funkce bude mít dva vstupní prametry. Parametr
file_namebude reprezentovat název souboru se zdrojovými datyfamous_quotes.txt. Parametrcustom_idxbude reprezentovat index řádku, ze kterého v textovém souboru budeme načítat řetězec. - Funkce pomocí vhodné metody z balíčku
os.pathzjistí, jestli v pracovním adresáři existuje soubor, který chceme načíst. Pokud ne, vrátí hodnotuNone. - Funkce načte větu z požadovaného řádku textového souboru.
- Funkce vrátí načtenou větu jako seznam jednotlivých slov převedených na malé znaky. Seznam nebude obsahovat interpukční známeka obsažená na konci věty.
Algoritmus Counting Sort umí řadit pouze celá čísla. Naším úkolem je ovšem abecední řazení slov. Jednoduchý způsob, jak toto omezení obejít, je přiřadit každému slovu nějaký identifikátor (token), v našem případě celé číslo. Protože chceme, aby řazení bylo prováděno abecedně dle prvního znaku slova, můžeme toto celé číslo odvodit právě z prvního znaku (slova začínající stejným znakem tak budou mít stejný token).
- Do modulu
ukol_12.pyimplementujte funkcitokenize(). - Funkce bude mít jeden vstupní parametr reprezentující neseřazený seznam slov.
- Funkce vrátí seznam celých čísel, která odpovídají prvním znakům každého slova (Pořadí musí být zachováno).
Pro převod na pořadí znaku abecedy využijte funkci
ord. - Vzorová vstupní a výstupní data mohou vypadat např. takto:
Vstup: ['ave', 'caesar']; Výstup: [97, 9]
- Do souboru
ukol_12.pyimplementujte funkcicounting_sort(). - Funkce zavolá funkci
tokenize()a převede seznam slov na seznam tokenů (celých čísel). - Funkce pomocí metody Counting Sort zajistí vzestupné abecední seřazení slov načtené věty. Funkce bude mít jeden vstupní parametr, který bude reprezentovat seznam slov získaný v předchnozím kroku.
- Funkce vrátí jeden výstupní argument. Výstupním argumentem bude slovník obsahující
klíče
'sorted_sequence'a'frequency'. Pod klíčem'sorted_sequence'bude uložen seznam seřazených slov. Pod klíčem'frequency'bude uložen seznam o délce 256 prvků obsahující kumulativní četnosti slov se stejným počátečním znakem. Tento seznam je mezikrokem metody Counting Sort.
- Ke každé funkci doplňte stručný dokumentační řetězec.
Counting Sort je třídicí algoritmus, který třídí prvky pole počítáním počtu výskytů každého jedinečného prvku v poli. Počet je uložen v pomocném poli a třídění se provádí mapováním počtu jako indexu pomocného pole.
Inicializace pole (seznam) pro určení četností jednotlivých prvků. Protože pracujeme se znaky abecedy a všechny základní znaky se v Pythonu vyskytují v rozsahu 0–255, vytvoříme seznam obsahující 256 nulových hodnot. Toto pole bude využito pro ukládání počtu prvků v poli.

Inicializace pole pro ukládání sežazených slov. Vytvoříme seznam s takovým počtem prvků, kolik má vstupní neseřazená sekvence.
Výchozí hodnota prvků může být libovolná, např. 0 nebo "".
Sekvenčně projdeme seznam s tokeny (analyzujeme totiž celá čísla reprezentující text).
Do seznamu s četnostmi uložíme četnost každého tokenu. Četnost tokenu ukládáme na pozici odpovídající hodnotě tokenu.
Pokud máme např. 5 tokenů s hodnotou 123, uložíme do seznamu s četnostmi na pozici 123 hodnotu 5. Pokud token neexistuje, zůstane
v seznamu četností na jeho pozici hodnota 0.

Projdeme seznam s četnostmi a převedeme je na kumulativní četnosti (kumulativní četnost na pozici i bude dána
součtem všech četností v rozsahu 0:i, včetně). Jednoduchá implementace může spočívat např. v sekvenčním průchodu seznamem a s pomocí indexace
provést v každé iteraci kumulaci dvou po sobě jdoucích hodnot:
count[i] += count[i-1]
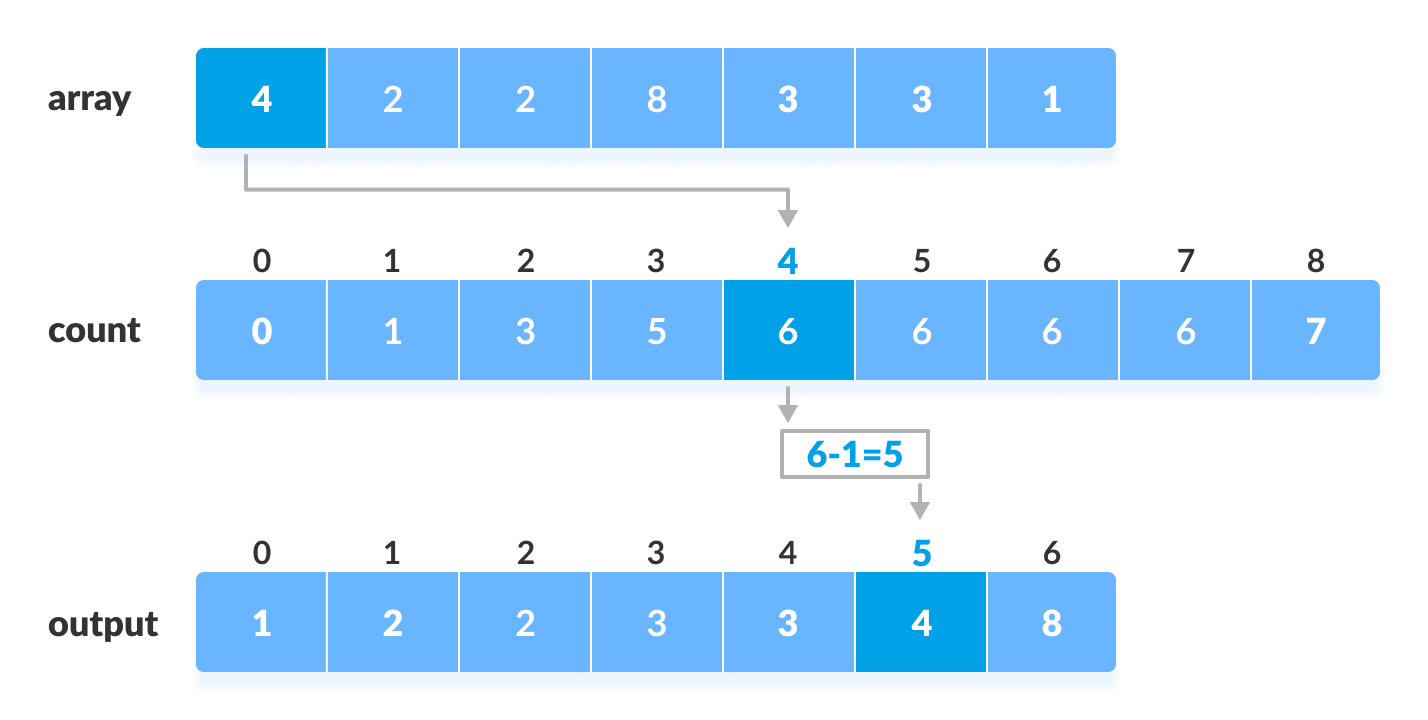
Tento výsledek nám pomůže při umisťování prvků do správného indexu seřazeného pole. Obrázek níže odpovída správně určeným kumulativním četnostem pro seznam z Kroku č. 3.

A teď nás čeká kouzlo celého algoritmu:) Označme si kumulativní četnost konkrétního prvku jako cf. Potom hodnota cf - 1
označuje pořadí tohoto prvku v seřazené sekvenci!
V našem příkladu níže máme na první pozici token s hodnotou 4. Jeho kumulativní četnost tedy nalezneme v seznamu kumulativních četností na indexu 4 (5. prvek).
Na této pozici leží hodnota 6. Po odečtení jedničky tedy získáme index toho prvku v seřazené sekvenci. První prvek z půovdní sekvence
bude v seřazené sekvenci vložen na index číslo 5. V našem případě může být postup následující:
- Sekvenčně projdeme seznam s tokeny (nejlépe pomocí indexace nebo po "zipnutí" se seznamem slov).
- Pro každý token nalezneme jeho kumulativní četnost a od této hodnoty odečteme jedničku.
- Do pole pro ukládání seřazených slov uložíme na index z bodu 2 slovo z neseřazeného seznamu, jehož pořadí odpovídá pořadí právě analyzovanéh tokenu.
- Po umístění prvku do správné polohy snížíme jeho kumulativní četnost o jeden (abychom nepřiřazovali stejné tokeny vždy do jedné pozice.
- A máme seřazeno!
Counting Sort je stabilní třídí algoritmus. Pozor tedy na zachování relativního pořadí jednotlivých slov. Kumulativní četnost určuje vždy poslední výskyt stejného prvku. Pokud však řadíme slova od prvního po poslední, bude důsledkem změna směru relativního pořadí (stejné prvky budou seřazeny v opačném pořadí oproti původní sekvenci). Problém můžeme vyřešit buď reverzním procházením řazené sekvence nebo vhodnou úpravou indexace při plnění seřazené sekvence.