RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Vision-Language Foundation Model for Remote Sensing
-
Zilun Zhang, Tiancheng Zhao, Yulong Guo, Jianwei Yin
-
Preprint (Updated on Dec 03): https://arxiv.org/abs/2306.11300
-
RS5M Data: https://huggingface.co/datasets/Zilun/RS5M/
-
CLIP-like Model for Remote Sensing: https://huggingface.co/Zilun/GeoRSCLIP
-
Stable Diffusion Model for Remote Sensing: https://huggingface.co/Zilun/GeoRSSD
-
Post: Link
Pre-trained Vision-Language Models (VLMs) utilizing extensive image-text paired data have demonstrated unprecedented image-text association capabilities, achieving remarkable results across various downstream tasks. A critical challenge is how to make use of existing large-scale pre-trained VLMs, which are trained on common objects, to perform the domain-specific transfer for accomplishing domain-related downstream tasks. In this paper, we propose a new framework that includes the Domain pre-trained Vision-Language Model (DVLM), bridging the gap between the General Vision-Language Model (GVLM) and domain-specific downstream tasks. Moreover, we present an image-text paired dataset in the field of remote sensing (RS), RS5M, which has 5 million RS images with English descriptions. The dataset is obtained from filtering publicly available image-text paired datasets and captioning label-only RS datasets with pre-trained VLM. These constitute the first large-scale RS image-text paired dataset. Additionally, we fine-tuned the CLIP model and tried several Parameter-Efficient Fine-Tuning methods on RS5M to implement the DVLM. Experimental results show that our proposed dataset is highly effective for various tasks, and our model GeoRSCLIP improves upon the baseline or previous state-of-the-art model by 3% ~ 20% in Zero-shot Classification (ZSC) tasks, 3% ~ 6% in Remote Sensing Cross-Modal Text–Image Retrieval (RSCTIR) and 4% ~ 5% in Semantic Localization (SeLo) tasks.

- Install Pytorch following instructions from the official website (We tested in torch 2.0.1 with CUDA 11.8 and 2.1.0 with CUDA 12.1)
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118- Install other dependencies
pip install pillow pandas scikit-learn ftfy tqdm matplotlib transformers adapter-transformers open_clip_torch pycocotools timm clip-benchmark torch-rs- Clone the repo from: https://huggingface.co/Zilun/GeoRSCLIP
git clone https://huggingface.co/Zilun/GeoRSCLIP
cd GeoRSCLIP- Unzip the test data
unzip data/rs5m_test_data.zip- Run the inference script:
python codebase/inference.py --ckpt-path /your/local/path/to/RS5M_ViT-B-32.pt --test-dataset-dir /your/local/path/to/rs5m_test_data- (Optional) If you just want to load the GeoRSCLIP model:
import open_clip
import torch
from inference_tool import get_preprocess
ckpt_path = "/your/local/path/to/RS5M_ViT-B-32.pt"
model, _, _ = open_clip.create_model_and_transforms("ViT-B/32", pretrained="openai")
checkpoint = torch.load(ckpt_path, map_location="cpu")
msg = model.load_state_dict(checkpoint, strict=False)
model = model.to("cuda")
img_preprocess = get_preprocess(
image_resolution=224,
) import open_clip
import torch
from inference_tool import get_preprocess
ckpt_path = "/your/local/path/to/RS5M_ViT-H-14.pt"
model, _, _ = open_clip.create_model_and_transforms("ViT-H/14", pretrained="laion2b_s32b_b79k")
checkpoint = torch.load(ckpt_path, map_location="cpu")
msg = model.load_state_dict(checkpoint, strict=False)
model = model.to("cuda")
img_preprocess = get_preprocess(
image_resolution=224,
)-
All tasks
EuroSAT_acc RESISC45_acc AID_acc retrieval-image2text-R@1-rsitmd retrieval-image2text-R@5-rsitmd retrieval-image2text-R@10-rsitmd retrieval-text2image-R@1-rsitmd retrieval-text2image-R@5-rsitmd retrieval-text2image-R@10-rsitmd retrieval-mean-recall-rsitmd retrieval-image2text-R@1-rsicd retrieval-image2text-R@5-rsicd retrieval-image2text-R@10-rsicd retrieval-text2image-R@1-rsicd retrieval-text2image-R@5-rsicd retrieval-text2image-R@10-rsicd retrieval-mean-recall-rsicd Selo_Rsu Selo_Rda Selo_Ras Selo_Rmi GeoRSCLIP-ViTB32 61.40 72.74 74.42 17.92 34.96 46.02 14.12 41.46 57.52 35.33 12.17 28.45 38.61 9.31 26.51 41.28 26.06 0.755636 0.730925 0.258044 0.744670 GeoRSCLIP-ViTH14 67.47 73.83 76.33 23.45 42.92 53.32 18.01 44.60 59.96 40.38 14.27 29.55 40.44 11.38 30.80 44.41 28.48 0.759515 0.741806 0.256649 0.749430 -
RSCTIR Task
-
RSICD Test set
Method Paradigm Tuned on R@1 (I2T) R@5 (I2T) R@10 (I2T) R@1 (T2I) R@5 (T2I) R@10 (T2I) mR LW-MCR Supervised RSICD 3.29% 12.52% 19.93% 4.66% 17.51% 30.02% 14.66% VSE++ Supervised RSICD 3.38% 9.51% 17.46% 2.82% 11.32% 18.10% 10.43% AFMFN Supervised RSICD 5.39% 15.08% 23.40% 4.90% 18.28% 31.44% 16.42% KCR Supervised RSICD 5.84% 22.31% 36.12% 4.76% 18.59% 27.20% 19.14% GaLR Supervised RSICD 6.59% 19.85% 31.04% 4.69% 19.48% 32.13% 18.96% SWAN Supervised RSICD 7.41% 20.13% 30.86% 5.56% 22.26% 37.41% 20.61% HVSA Supervised RSICD 7.47% 20.62% 32.11% 5.51% 21.13% 34.13% 20.16% PIR Supervised RSICD 9.88% 27.26% 39.16% 6.97% 24.56% 38.92% 24.46% FAAMI Supervised RSICD 10.44% 22.66% 30.89% 8.11% 25.59% 41.37% 23.18% Multilanguage Supervised RSICD 10.70% 29.64% 41.53% 9.14% 28.96% 44.59% 27.42% PE-RSITR GVLM + FT RSICD 14.13% 31.51% 44.78% 11.63% 33.92% 50.73% 31.12% MTGFE Supervised RSICD 15.28% 37.05% 51.60% 8.67% 27.56% 43.92% 30.68% RemoteCLIP GVLM + FT RET-3 + DET-10 + SEG-4 17.02% 37.97% 51.51% 13.71% 37.11% 54.25% 35.26% CLIP-Baseline GVLM - 5.31% 14.18% 23.70% 5.78% 17.73% 27.76% 15.74% GeoRSCLIP-FT GVLM + FT RS5M + RSICD 22.14% 40.53% 51.78% 15.26% 40.46% 57.79% 38.00% GeoRSCLIP-FT GVLM + FT RS5M + RET-2 21.13% 41.72% 55.63% 15.59% 41.19% 57.99% 38.87% -
RSITMD test set
Method Paradigm Tuned on R@1 (I2T) R@5 (I2T) R@10 (I2T) R@1 (T2I) R@5 (T2I) R@10 (T2I) mR LW-MCR Supervised RSITMD 10.18% 28.98% 39.82% 7.79% 30.18% 49.78% 27.79% VSE++ Supervised RSITMD 10.38% 27.65% 39.60% 7.79% 24.87% 38.67% 24.83% AFMFN Supervised RSITMD 11.06% 29.20% 38.72% 9.96% 34.03% 52.96% 29.32% HVSA Supervised RSITMD 13.20% 32.08% 45.58% 11.43% 39.20% 57.45% 33.15% SWAN Supervised RSITMD 13.35% 32.15% 46.90% 11.24% 40.40% 60.60% 34.11% GaLR Supervised RSITMD 14.82% 31.64% 42.48% 11.15% 36.68% 51.68% 31.41% FAAMI Supervised RSITMD 16.15% 35.62% 48.89% 12.96% 42.39% 59.96% 35.99% MTGFE Supervised RSITMD 17.92% 40.93% 53.32% 16.59% 48.50% 67.43% 40.78% PIR Supervised RSITMD 18.14% 41.15% 52.88% 12.17% 41.68% 63.41% 38.24% Multilanguage Supervised RSITMD 19.69% 40.26% 54.42% 17.61% 49.73% 66.59% 41.38% PE-RSITR GVLM + FT RSITMD 23.67% 44.07% 60.36% 20.10% 50.63% 67.97% 44.47% RemoteCLIP GVLM + FT RET-3 + DET-10 + SEG-4 27.88% 50.66% 65.71% 22.17% 56.46% 73.41% 49.38% CLIP-Baseline GVLM - 9.51% 23.01% 32.74% 8.81% 27.88% 43.19% 24.19% GeoRSCLIP-FT GVLM + FT RS5M + RSITMD 30.09% 51.55% 63.27% 23.54% 57.52% 74.60% 50.10% GeoRSCLIP-FT GVLM + FT RS5M + RET-2 32.30% 53.32% 67.92% 25.04% 57.88% 74.38% 51.81%
-
- The GeoRSSD models that were tuned with 1% and 20% data of RS5M has been released:
-
Dropbox:
-
Baidu Disk
- https://pan.baidu.com/s/1AcZcoY5VwdhZOhF_o8o0Fg?pwd=41y2
- Password: 41y2
-
The BigEarthNet with RGB channels only (with corresponding filenames in our csv files)
- https://pan.baidu.com/s/1aCqRmnCeow18ry__R_oZow?pwd=6ya9
- Password: 6ya9
-
Dropbox:
-
Baidu Disk
- https://pan.baidu.com/s/1NT8qxJJhWjxSlrXq5UqVPg?pwd=mcqc
- Password: mcqc
- The metafile and other useful files of RS5M can be found here: https://huggingface.co/datasets/Zilun/RS5M/
- See README.md in huggingface for a breakdown explanation of each file.
- We create the webdataset format files containing paired image and text for sequential data io. Do NOT untar the files.
- Download the webdataset files from the link provided above. The dataset directory should look like this:
/nas/zilun/RS5M_v5/webdataset ├── train ├── pub11-train-0000.tar ├── pub11-train-0001.tar ├── ...... ├── pub11-train-0030.tar ├── pub11-train-0031.tar ├── rs3-train-0000.tar ├── rs3-train-0001.tar ├── ...... ├── rs3-train-0030.tar ├── rs3-train-0031.tar ├── val ├── pub11-val-0000.tar ├── pub11-val-0001.tar ├── ...... ├── pub11-val-0030.tar ├── pub11-val-0031.tar ├── rs3-val-0000.tar ├── rs3-val-0001.tar ├── ...... ├── rs3-val-0030.tar ├── rs3-val-0031.tar - An example of data IO pipeline using webdataset files is provided in "dataloader.py". The throughput (images per second) is ~1800 images per second. (With Ryzen 3950x CPU and dual-channel 3200MHZ DDR4 RAM)
- Run the following to have a taste:
python dataloader.py --train_dir /media/zilun/mx500/RS5M/data/train --val_dir /media/zilun/mx500/RS5M/data/val --num_worker 16 --batch_size 400 --num_shuffle 10000
- We also provide the pure image files, which could be used with the metafiles from huggingface. Due to the huge amount of the image data, an SSD drive is recommended.
- Download the files from the Dropbox link or Baidu disk link provided. The dataset directory should look like this:
/nas/zilun/RS5M_v5/img_only ├── pub11 ├── pub11.tar.gz_aa ├── pub11.tar.gz_ab ├── ...... ├── pub11.tar.gz_ba ├── pub11.tar.gz_bc ├── rs3 ├── ben ├── ben.tar.gz_aa ├── fmow ├── fmow.tar.gz_aa ├── fmow.tar.gz_ab ├── ...... ├── fmow.tar.gz_ap ├── fmow.tar.gz_aq ├── millionaid ├── millionaid.tar.gz_aa ├── millionaid.tar.gz_ab ├── ...... ├── millionaid.tar.gz_ap ├── millionaid.tar.gz_aq - Combine and untar the files. You will have the images files now.
# optional, for split and zip the dataset tar -I pigz -cvf - pub11 | split --bytes=500MB - pub11.tar.gz_ # combine different parts into one cat pub11.tar.gz_* > pub11.tar # extract pigz -dc pub11.tar | tar -xvf - -C /data/zilun/RS5M_v5/img_only/
| Name | Amount | After Keyword Filtering | Download Image | Invalid Image (Removed) | Duplicate Image (Removed) | Outlier images (Removed by VLM and RS Detector) | Remain |
|---|---|---|---|---|---|---|---|
| LAION2B | 2.3B | 1,980,978 | 1,737,584 | 102 | 343,017 | 333,686 | 1,060,779 |
| COYO700M | 746M | 680,089 | 566,076 | 28 | 245,650 | 94,329 | 226,069 |
| LAIONCOCO | 662M | 3,014,283 | 2,549,738 | 80 | 417,689 | 527,941 | 1,604,028 |
| LAION400M | 413M | 286,102 | 241,324 | 25 | 141,658 | 23,860 | 75,781 |
| WIT | 37 M | 98,540 | 93,754 | 0 | 74,081 | 9,299 | 10,374 |
| YFCC15M | 15M | 27,166 | 25,020 | 0 | 265 | 15,126 | 9,629 |
| CC12M | 12M | 18,892 | 16,234 | 0 | 1,870 | 4,330 | 10,034 |
| Redcaps | 12M | 2,842 | 2,686 | 0 | 228 | 972 | 1,486 |
| CC3M | 3.3M | 12,563 | 11,718 | 1 | 328 | 1,817 | 9,572 |
| SBU | 1M | 102 | 91 | 0 | 4 | 36 | 51 |
| VG | 0.1M | 26 | 26 | 0 | 0 | 20 | 6 |
| Total | 4.2B | 6,121,583 | 5,244,251 | 236 | 1,224,790 | 1,011,416 | 3,007,809 |
| Name | Amount | Original Split | Has Class label |
|---|---|---|---|
| FMoW | 727,144 | Train | Yes |
| BigEarthNet | 344,385 | Train | Yes |
| MillionAID | 990,848 | Test | No |
| Total | 2,062,377 | - | - |
-
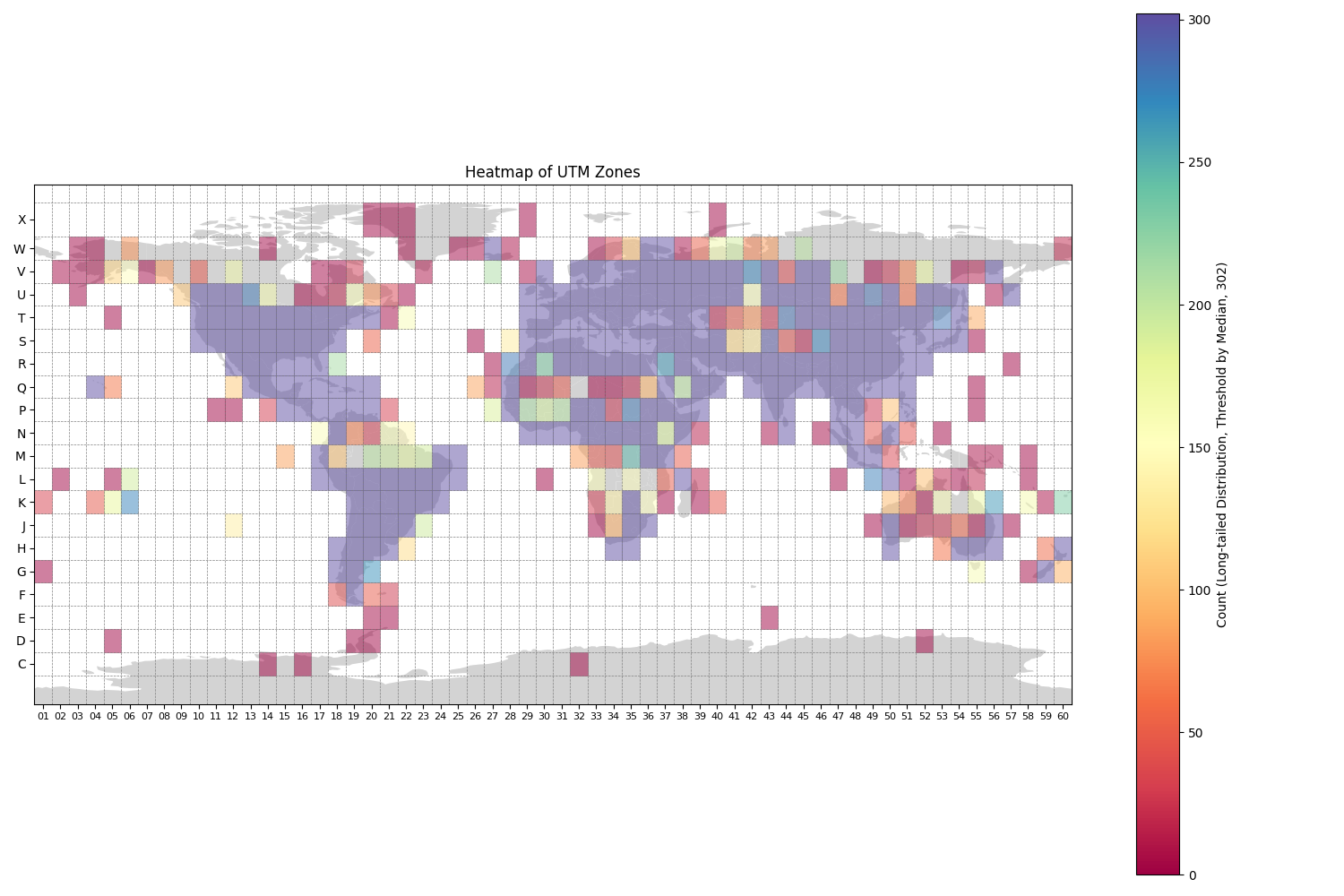
Statistics of geometa for images contain the UTM zone, latitude, and longitude information.
- YFCC14M: 7841
- FMoW: 727,144
- BigEarthNet: 344,385
-
Extract entity with "GPE" label using NER from NLTK
- Applied to captions in PUB11 subset
- Extraction Result
- 880,354 image-text pairs contain "GPE", and most of them are city/country names.

- Tuned with LoRA
- Checkpoint and inference code can be found through this link
Email: zilun.zhang@zju.edu.cn
WeChat: zilun960822
Slack Group: https://join.slack.com/t/visionlanguag-fks1990/shared_invite/zt-290vxhx5y-SUkCzf2aH3G9eu3lye2YvQ
We thank Delong Chen and his ITRA framework for helping us fine-tune the CLIP-like models. https://itra.readthedocs.io/en/latest/Contents/introduction/overview.html
If you use RS5M or GeoRSCLIP in a research paper, we would appreciate using the following citations:
@misc{zhang2023rs5m,
title={RS5M: A Large Scale Vision-Language Dataset for Remote Sensing Vision-Language Foundation Model},
author={Zilun Zhang and Tiancheng Zhao and Yulong Guo and Jianwei Yin},
year={2023},
eprint={2306.11300},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Some other citations:
@article{Long2021DiRS,
title={On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances and Million-AID},
author={Yang Long and Gui-Song Xia and Shengyang Li and Wen Yang and Michael Ying Yang and Xiao Xiang Zhu and Liangpei Zhang and Deren Li},
journal={IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing},
year={2021},
volume={14},
pages={4205-4230}
}
@inproceedings{Sumbul_2019,
title={Bigearthnet: A Large-Scale Benchmark Archive for Remote Sensing Image Understanding},
url={http://dx.doi.org/10.1109/IGARSS.2019.8900532},
DOI={10.1109/igarss.2019.8900532},
booktitle={IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium},
publisher={IEEE},
author={Sumbul, Gencer and Charfuelan, Marcela and Demir, Begum and Markl, Volker},
year={2019},
month=jul
}
@inproceedings{fmow2018,
title={Functional Map of the World},
author={Christie, Gordon and Fendley, Neil and Wilson, James and Mukherjee, Ryan},
booktitle={CVPR},
year={2018}
}