easy-bert
easy-bert是一个中文NLP工具,提供诸多bert变体调用和调参方法,极速上手;清晰的设计和代码注释,也很适合学习。
1. 快速安装
主要支持两种安装方法:
-
PYPI安装:
pip install easy-zh-bert注意:因为和别的库重名,上传到pypi上的名字为easy-zh-bert
-
Github源码安装:
pip install git+https://github.com/waking95/easy-bert.git- 可以指定具体的版本,如
0.5.0,即:pip install git+https://github.com/waking95/easy-bert.git@v0.5.0
2. 极速上手
上手前,请确保:
- 已从hugging
face官网下载好chinese-roberta-wwm-ext,保存到某个目录,如:
./models/chinese-roberta-wwm-ext; - 创建好你将要保存模型的目录,如:
./tests/test_model;
分类任务
from easy_bert.bert4classification.classification_predictor import ClassificationPredictor
from easy_bert.bert4classification.classification_trainer import ClassificationTrainer
pretrained_model_dir, your_model_dir = './models/chinese-roberta-wwm-ext', './tests/test_model'
texts = ['天气真好', '今天运气很差']
labels = ['正面', '负面']
trainer = ClassificationTrainer(pretrained_model_dir, your_model_dir)
trainer.train(texts, labels, validate_texts=texts, validate_labels=labels, batch_size=2, epoch=20)
predictor = ClassificationPredictor(pretrained_model_dir, your_model_dir)
labels = predictor.predict(texts)更多代码样例参考:tests/test_bert4classification.py
序列标注
from easy_bert.bert4sequence_labeling.sequence_labeling_predictor import SequenceLabelingPredictor
from easy_bert.bert4sequence_labeling.sequence_labeling_trainer import SequenceLabelingTrainer
pretrained_model_dir, your_model_dir = './models/chinese-roberta-wwm-ext', './tests/test_model'
texts = [['你', '好', '呀'], ['一', '马', '当', '先', '就', '是', '好']]
labels = [['B', 'E', 'S'], ['B', 'M', 'M', 'E', 'S', 'S', 'S']]
trainer = SequenceLabelingTrainer(pretrained_model_dir, your_model_dir)
trainer.train(texts, labels, validate_texts=texts, validate_labels=labels, batch_size=2, epoch=20)
predictor = SequenceLabelingPredictor(pretrained_model_dir, your_model_dir)
labels = predictor.predict(texts)更多代码样例参考:tests/test_bert4sequence_labeling.py
预训练
from easy_bert.bert4pretraining.mlm_trainer import MaskedLMTrainer
pretrained_model_dir, your_model_dir = './models/chinese-roberta-wwm-ext', './tests/test_model'
texts = [
'早上起床后,我发现今天天气还真是不错的。早上起床后,我发现今天天气还真是不错的。早上起床后,我发现今天天气还真是不错的。'
]
trainer = MaskedLMTrainer(pretrained_model_dir, your_model_dir)
trainer.train(texts, batch_size=1, epoch=20)更多代码样例参考:tests/test_mlm.py
3. 调参指南
Trainer提供了丰富的参数可供选择
预训练模型
你可以快速替换预训练模型,即更改pretrained_model_dir参数,目前测试过的中文预训练模型包括:
- albert_chinese_base
- chinese-bert-wwm
- chinese-macbert-base
- bert-base-chinese
- chinese-electra-180g-base-discriminator
- chinese-roberta-wwm-ext
- nezha-base-wwm
- uer_large
- TinyBERT_4L_zh
- bert-distil-chinese
- longformer-chinese-base-4096
- 以上大部分模型的large版本
可以优先使用chinese-roberta-wwm-ext或者nezha-base-wwm
学习率
bert微调一般使用较小的学习率learning_rate,如:5e-5, 3e-5, 2e-5
并行训练
可以为Trainer或Predictor设置enable_parallel=True,加速训练或推理。启用后,默认使用单机上的所有GPU。
对抗训练
对抗训练是一种正则化方法,主要是在embedding上加噪,缓解模型过拟合,默认adversarial=None,表示不对抗。
你可以设置:
adversarial='fgm':表示使用FGM对抗方法;adversarial='pgd':表示使用PGD对抗方法;
dropout_rate
dropout_rate随机丢弃一部分神经元来避免过拟合,隐含了集成学习的**,默认dropout_rate=0.5
loss选择
这里支持以下loss,通过loss_type参数来设置:
cross_entropy_loss:标准的交叉熵loss,ClassificationTrainer默认;label_smoothing_loss:标签平滑loss,在label层面增加噪声,使用soft label替代hard label,缓解过拟合;focal_loss:focal loss在类别不均衡时比较有用,它允许为不同的label设置代价权重,并对简单的样本进行打压;- 你可以进一步设置
focal_loss_gamma和focal_loss_alpha,默认focal_loss_gamma=2focal_loss_alpha=None - 设置
focal_loss_alpha时,请确保它是一个标签权重分布,如:三分类设置focal_loss_alpha=[1, 1, 1.5],表示我们更关注label_id为2的标签,因为它的样本数更少;
- 你可以进一步设置
crf_loss:crf层学习标签与标签之间的转移,仅支持序列标注任务,SequenceLabelingTrainer默认;- 你可以进一步设置
crf_learning_rate,一般crf层会使用大一点的学习率,确保转移矩阵学好,默认crf_learning_rate=1e-3;
- 你可以进一步设置
更多代码样例参考:tests/test_bert4classification.py tests/test_bert4sequence_labeling.py
长文本
Bert的输入最多为512字,如果待处理的文本超过512字,你可以截断或者分段
输入模型,也可以尝试Longformer模型:longformer-chinese-base-4096,它使用稀疏自注意力,降低了自注意力的时空复杂度,将模型处理长度扩张到了4096
知识蒸馏
bert模型本身较重,资源受限下,想提高推理速度,知识蒸馏是一个不错的选择。
这里可以选择:
DistilBert:是一个6层的Bert,预训练模型bert-distil-chinese在预训练阶段已经进行MLM任务的蒸馏,你可以直接基于它进行下游任务的微调;- 理论上,推理速度可以获得40%的提升,获得97%的bert-base效果
TinyBert:TinyBERT_4L_zh拥有4层、312的hidden_size,一般使用两阶段蒸馏,即下游任务也要蒸馏,可以使用TinyBertDistiller实现;- TinyBert微调蒸馏时,向老师的soft label学习、向老师的hidden学习、向老师的embedding学习、向真实的label学习
- 理论上,4层的TinyBert,能够达到老师(Bert-base)效果的96.8%、参数量缩减为原来的13.3%、仅需要原来10.6%的推理时间
TinyBert蒸馏:分类
from easy_bert.bert4classification.classification_predictor import ClassificationPredictor
from easy_bert.bert4classification.classification_trainer import ClassificationTrainer
from easy_bert.tinybert_distiller import TinyBertDistiller
texts = ['天气真好', '今天运气很差']
labels = ['正面', '负面']
teacher_pretrained, teacher_model_dir = './models/chinese-roberta-wwm-ext', './tests/test_model'
student_pretrained, student_model_dir = './models/TinyBERT_4L_zh', './tests/test_model2'
# 训练老师模型
trainer = ClassificationTrainer(teacher_pretrained, teacher_model_dir)
trainer.train(texts, labels, validate_texts=texts, validate_labels=labels, batch_size=2, epoch=20)
# 蒸馏学生
distiller = TinyBertDistiller(
teacher_pretrained, teacher_model_dir, student_pretrained, student_model_dir,
task='classification'
)
distiller.distill_train(texts, labels, max_len=20, epoch=20, batch_size=2)
# 加载fine-tune蒸馏过的模型
predictor = ClassificationPredictor(student_pretrained, student_model_dir)
print(predictor.predict(texts))TinyBert蒸馏:序列标注
from easy_bert.bert4sequence_labeling.sequence_labeling_predictor import SequenceLabelingPredictor
from easy_bert.bert4sequence_labeling.sequence_labeling_trainer import SequenceLabelingTrainer
from easy_bert.tinybert_distiller import TinyBertDistiller
texts = [['你', '好', '呀'], ['一', '马', '当', '先', '就', '是', '好']]
labels = [['B', 'E', 'S'], ['B', 'M', 'M', 'E', 'S', 'S', 'S']]
teacher_pretrained, teacher_model_dir = './models/chinese-roberta-wwm-ext', './tests/test_model'
student_pretrained, student_model_dir = './models/TinyBERT_4L_zh', './tests/test_model2'
# 训练老师模型
trainer = SequenceLabelingTrainer(teacher_pretrained, teacher_model_dir, loss_type='crf_loss')
trainer.train(texts, labels, validate_texts=texts, validate_labels=labels, batch_size=2, epoch=20)
# 蒸馏学生
distiller = TinyBertDistiller(
teacher_pretrained, teacher_model_dir, student_pretrained, student_model_dir,
task='sequence_labeling', hard_label_loss='crf_loss'
)
distiller.distill_train(texts, labels, max_len=20, epoch=20, batch_size=2)
# 加载fine-tune蒸馏过的模型
predictor = SequenceLabelingPredictor(student_pretrained, student_model_dir)
print(predictor.predict(texts))更多代码样例参考:tests/test_tinybert_distiller.py
关于TinyBertDistiller蒸馏参数:
task:可选classificationorsequence_labeling;enable_parallel:是否并行,默认False。注意,启用并行可能会导致蒸馏速度变慢;hard_label_loss:即针对label的loss计算,设置同Trainer的loss_type参数。默认cross_entropy_loss,序列标注推荐crf_loss;temperature:蒸馏温度系数,一般大于1较好,默认为4,可在1~10之间调试;hard_label_weight:hard label的loss权重,默认为1;kd_loss_type:soft label的loss类型,即向老师的输出概率学习,默认为ce,即交叉熵;kd_loss_weight:kd_loss的权重,可以稍微放大其权重,即加强向老师的soft label学习,默认为1.2;lr:蒸馏学习率,一般设置较大,这里默认1e-4;ckpt_frequency:一个epoch存ckpt_frequency次模型,默认为1;epoch:迭代轮数,一般蒸馏时设置较大的epoch,如20~50,默认为20;
随机种子
你可以设置random_seed,来控制随机种子,默认random_seed=0。
ONNX硬件加速
可以将torch模型转为ONNX格式,通过微软的onnxruntime实现推理阶段的硬件加速,调用Predictor的transform2onnx()可以实现转换,代码样例参考 tests/test_onnx.py。
这里注意:
- cpu下请使用onnxruntime库,而不是onnxruntime-gpu库,参见 setup.py 里
setup函数的install_requires参数; - onnxruntime-gpu==1.4.0仅适合cuda10.1 cuDNN7.6.5,更多版本兼容参考: https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements
warmup
warmup使用动态的学习率(一般lr先增大 后减小),
- lr一开始别太大,有助于缓解模型在初始阶段,对前几个batch数据过拟合;
- lr后面小一点,有助于模型后期的稳定;
可以通过Trainer的参数来控制warmup:
warmup_type:声明warmup的种类,默认为None,表示不启用warmup,即学习率恒定;- 可以设置为
constant,表示使用恒定学习率,lr曲线为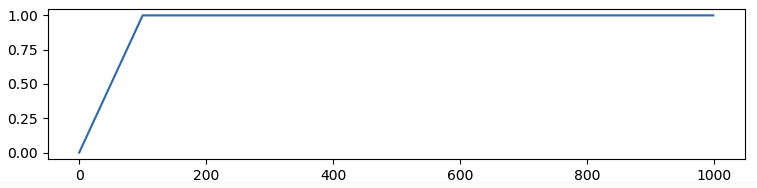
- 可以设置为
cosine,表示余弦曲线学习率,lr曲线为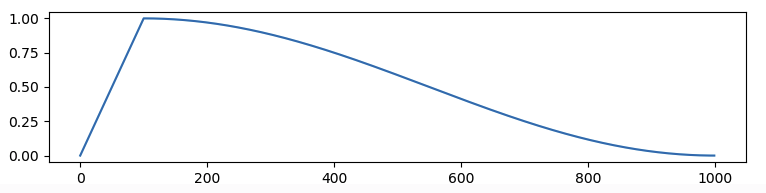
- 可以设置为
linear,表示线性学习率,lr曲线为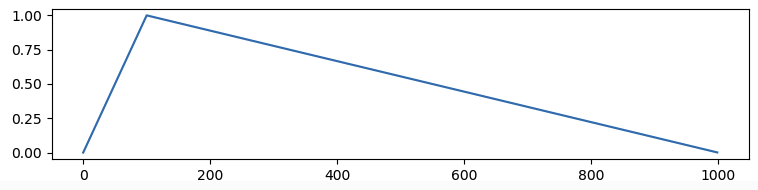
- 可以设置为
warmup_step_num:增加阶段,需要多少步到达设置的lr(上图中峰值);- 可以为
int类型,表示步数; - 也可以为
float类型,表示总步数的比例,总步数 = batch_num * epoch。如:总共训练1000步,设置warmup_step_num=0.1,表示warmup_step_num实际为100;
- 可以为



更多代码样例参考 tests/test_warmup.py。
混合精度(fp16)
torch里面默认的浮点数是单精度的,即float32。我们可以将部分模型参数用float16,即fp16半精度来表示,一来可以降低显存的占用,二来可以提升训练和推理的速度。
Trainer和Predictor都提供了enable_fp16参数来控制是否启用fp16,默认为False。
更多代码样例参考 tests/test_fp16.py
领域预训练
bert已经提供了通用领域的预训练。为了提升下游任务的效果,你可能需要在特定领域(如金融、医疗等)上进行预训练,当前主要支持了MLM的预训练(NSP任务的预训练已被证明没什么作用)
MaskedLMTrainer 提供了非常好用的接口,可以直接来进行训练
详情请参考 tests/test_mlm.py
注意:
- mlm的实现为wwm,即全词mask。分词主要基于词库,需要传入
word_dict参数,可以使用jieba词库 https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt ,建议把低频词滤掉; - 因为是动态mask,即多个epoch里的同一个batch的mask的地方不一样,所以需要更多的epoch去迭代;
后接RNN
可以在Bert后面接一层RNN
可以通过Trainer的参数来控制:
add_on:声明后接层种类,可以是Nonebilstmbigru,默认为None;rnn_hidden:后接层rnn的hidden_size,默认为256;rnn_lr:后接层rnn的learning_rate,默认为1e-3,后接层的参数没有参与过预训练,学习率一般设置得较大;
更多代码样例参考 tests/test_add_on.py
继续训练
有时候训练会因为一些意外突然中断,为了能接着上次继续训练,你可以激活Trainer提供的load_last_ckpt参数,默认为False。
更多代码样例参考 tests/test_load_last_ckpt.py
layer级学习率衰减(LLRD)
bert层数很多(base 12层、large 24层),可以为不同的transformer层设置不同的学习率。一般层数越低,越通用,越任务无关,学习率越小。
可以通过Trainer的参数来控制:
layer_wise_lr_decay:是否启用layer级别学习率衰减,默认为False;lr_decay_rate: 学习率衰减的比例,默认为0.95;
更多代码样例参考 tests/test_layerwise_lr_decay.py
4. 理论教程 && 源码解读
- docs/Attention、Transformer和Bert.md
- docs/Bert的常见变体.md
- docs/Dropout.md
- docs/ONNX推理加速.md
- docs/Warmup.md
- docs/对抗训练.md
- docs/常用的loss.md
- docs/并行训练.md
- docs/混合精度.md
- docs/知识蒸馏.md
- docs/长文本.md
项目被【二范数智能】支持,添加wx【smile-4082】拉你到“AI交流群”,备注“交流”。
