- Problem Description
- Technologies
- Data Pipeline Architecture and Workflow
- Reproducability
- Further Improvements
This project showcases the best practices from Data Engineering Zoomcamp course. I aim to build an end-to-end batch data pipeline and analyze Github user activities from the beginning of this year.
You must have known about Github. GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 330 million projects.
It is very interesting that Github user activities are publicly available here. The dataset are grouped on hourly basis and stored in a JSON format. Each user activity is labeled with event type, such as: push, pull-request, issues, commit, etc. There are >150K rows of activities recorded in each dataset. In average, the size of the daily data is around 1,4GB and this dataset is updated daily.
In this project, I am going to implement some data engineering best practices and gain interesting metrics, such as:
- daily most active users (count by number of push)
- daily most active repos (count by number of PR)
- daily most active organizations (count by number of PR)
- daily number of event based on its type
This project utilizes such following tools that I learned from Data Engineering zoomcamp.
- Google Cloud Storage as the datalake to store our raw dataset.
- Google BigQuery as the data warehouse.
- dbt core as the transformation tool to implement data modeling.
- Self-hosted Prefect core to manage and monitor our workflow.
- Terraform to easily manage the infrastructure setup and changes.
- Google Compute Engine as the virtual host to host our data pipeline.
- Looker as the dashboard for end-user to create report and visualize some insights,
with some improvements to support easy reproducability, such as:
- Makefile
- Containerized environment with docker

The workflow is as follows:
The system ingests data from gharchive. Historical data covers the data that are created before the ingestion date. Moving-forward data is data that are updated daily.
Prefect is used to run both types of data and to schedule daily ingestion for moving-forward data.
Google Cloud Storage is our datalake. The data is stored in the datalase as Parquet files, partitioned by Year, Month and Day.

Google BigQuery serves as the data warehouse for the project. I implement several data modeling layers in BigQuery. The first layer of my data warehouse is the raw layer.
The raw layer is the layer where BigQuery uses external table to load our data from the datalake. Raw layer can contain any data duplications that may happens during the ingestion process (for example: through backfilling)
The external table configurations are defined in the terraform script.
BigQuery along with dbt is implemented to utilize data modeling layers.
As previously explained, the first layer of my data warehouse is raw layer; and the second layer is the staging layer. Staging layer ensures the data idempotency by removing data duplicate. The last layer is the core layer that do cleaning data (removal any events that are generated by bot) and the do metrics aggregation process.
Prefect is used to run ad-hoc dbt data transformation and to schedule daily data transformation for moving-forward data.

Pre-requisites: I use Makefile to make ease the reproducability process. Please install make tool in the Ubuntu terminal with this command sudo apt install make -y.
-
Clone this (repository)[https://github.com/oktavianidewi/github-data-pipeline.git] to your local workspace.
-
Open google cloud console and create a new GCP project by clicking
New Projectbutton.

You will be redirected to a new form, please provide the project information detail, copy the project_id and click Create button.

-
Let's create some resources (BigQuery, Cloud Engine and Cloud Storage and Service Account) on top of the newly created project using terraform. You should provide some information such as:
project_id,regionandzonein infra/gcp/terraform.tfvars as per your GCP setting. -
Once you've updated the file, run this command to spin-up the infrastructure resource up.
make infra-init-vmIf there is an error saying that the call to enable services (
compute,cloud_resource) is failing, please re-run the command again. -
Go to google console dashboard and make sure that all of the resources are built succesfully.
-
/sshfolder contains ssh-key to access newly created Compute Engine. Copy this file to yourhome/.sshdirectory
cp ssh/github-pipeline-project ~/.ssh/ -
Download the service-account keyfile (previously created via terraform) to a file named
sa-github-pipeline-project.jsonwith this commandmake generate-sa





-
Connect to GCE using SSH
ssh -i ~/.ssh/github-pipeline-project <your-email-address-for-gcp>@<external-vm-ip> -
Once you've got succesfully connected to the VM. Clone this repository, install
maketool and terraform inside the VM.git clone https://github.com/oktavianidewi/github-data-pipeline.git sudo apt install make -y make install-terraform -
Let's go back to the local terminal. Upload your service-account keyfile to VM directory with this command:
make copy-service-account-to-vm -
In VM terminal, run initial setup for VM with
makecommand, that will installdocker,docker-compose,pipandjqtools.make initial-setup-vm -
Change some variables in .env file and supply it with your GCP account information
# CHANGE-THIS GCP_PROJECT_ID="pacific-decoder-382709" # CHANGE-THIS GCS_BUCKET="datalake-github-pipeline" # CHANGE-THIS GCP_ZONE="asia-southeast1-b" # CHANGE-THIS GCS_BUCKET_ID="datalake-github-pipeline_pacific-decoder-382709" # CHANGE-THIS GCS_PATH="gs://datalake-github-pipeline_pacific-decoder-382709" # CHANGE-THIS GCP_EMAIL_WITHOUT_DOMAIN_NAME="learndewi"Change some variables in infra/gcp/terraform.tfvars and supply it with your GCP setting information
project_id = "pacific-decoder-382709" # CHANGE-THIS region = "asia-southeast1" # CHANGE-THIS zone = "asia-southeast1-b" # CHANGE-THIS -
Run prefect server and agent in VM with this command
export PREFECT_ORION_UI_API_URL=http://<external-vm-ip>:4200/api make docker-spin-up -
Go to your browser and paste
http://<external-vm-ip>:4200on URL bar to open prefect dashboard. Now your prefect core is up!
-
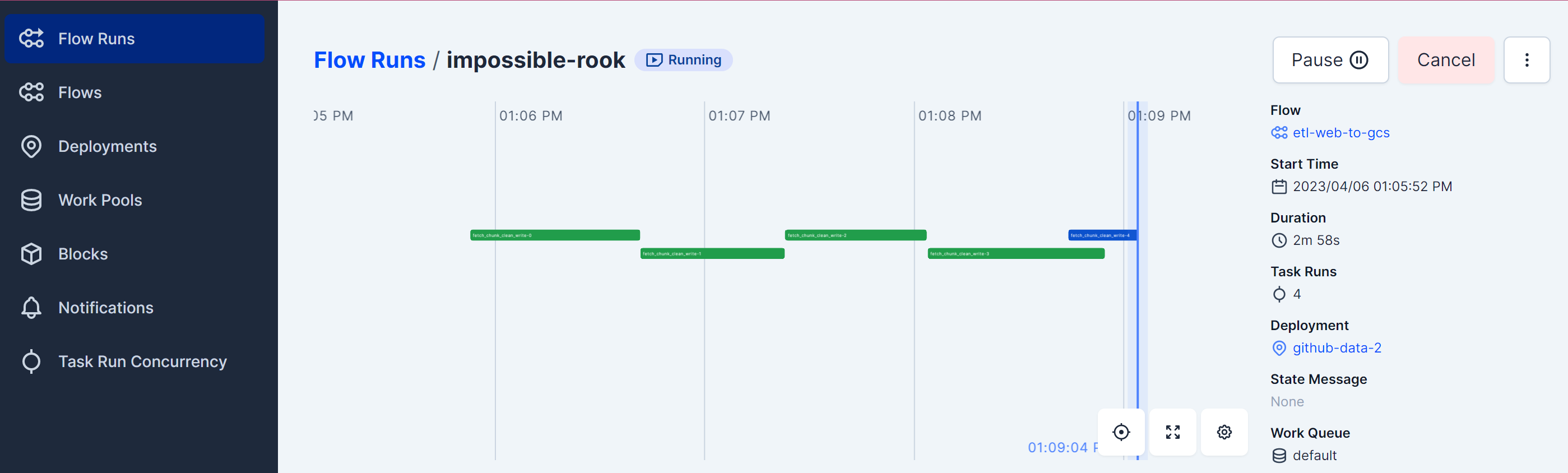
Start historical data ingestion to cloud storage with this command
make block-create make ingest-dataThis command will create a prefect flow deployment to:
- read data from github events
- chunk data into a certain rows
- type cast data as needed
- store data into cloud storage partitioned by its
year,monthandday.
-
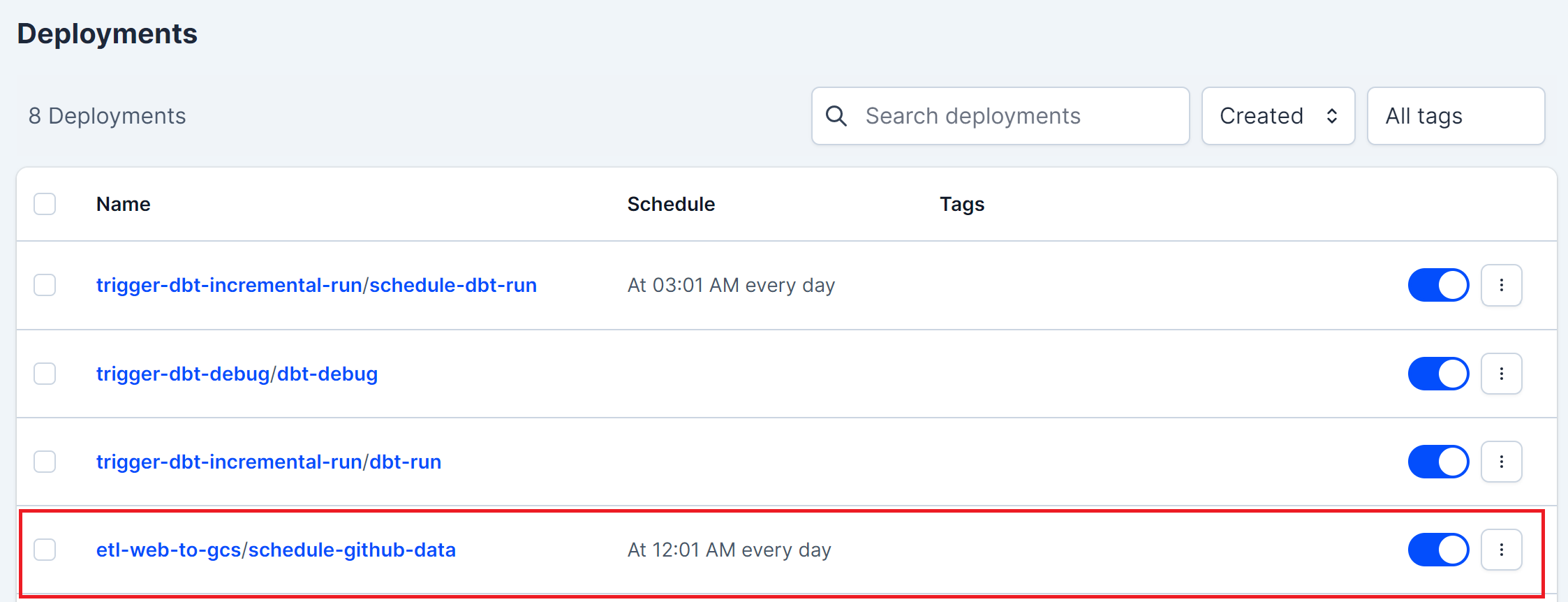
To ingest moving-forward data run this command:
make set-daily-ingest-dataThis command will schedule a deployment in prefect to run daily ingestion data at 00.01.
-
Once all the raw data are stored in the datalake, we can start transforming the raw data into our data warehouse with dbt. Run this command to transform data to
devenvironment.make transform-data-dev -
To transform data to a production environment, run this command
make transform-data-prod -
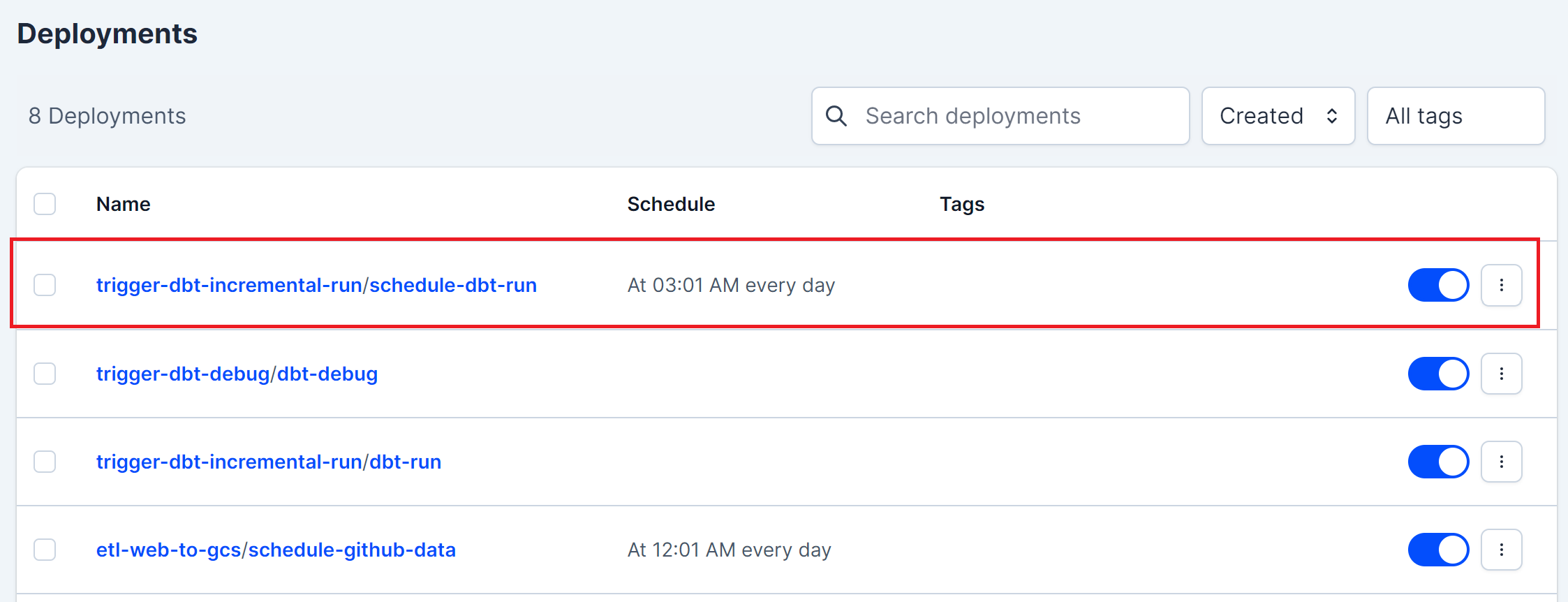
To set daily transformation data to the production environment, run this command:
make set-daily-transform-data-prodThis command will schedule a deployment in prefect to run daily dbt transformation data at 03.01.




There are many things can be improved from this project:
- Implement CI/CD
- Do a comprehensive testing