This Repo is mainly for the design and implementation of experiments in AI+Security course in ZJUSE.

Samples of CIFAR10
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
You maybe need Anaconda to create a virtual environment for running python.
conda create -n name=3.6
source activate nameThen just install all python package required by our project by one cmd line:
pip install -r requirements.txtExplain how to run the automated tests for this system
Given a well-trained classify model, we first take the test set of CIFAR10 as the input of the model and obtain responsive predict labels via the following shell:
# feel free to change
python src/test.py --task_id 1 --epoch 20 --device cuda:3After that you will get a .txt which contains all test result(10,000 digit):
3 8 8 0 6 6 1 6 3 1 0 9 5 7 9 8 5 7 8 6 7 0 4 9 5 2 4 0 9 6 6 5 4 5 9 2 4 1 9 5 4 6 5 6 0 9 3 9 7 6 9 8 0 3 8 8 7
0~9 correspond to ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') respectively.
Run evaluate.py to evaluate test results:
python src/evaluate.py --task_id 1 --gt gt.txtTo find a better hyperparameter, we can run run_tests.sh to generate test result using different hyperparameter:
./run_tests.shAfter that you can use src/analysis.py to obtain some useful figures.
-
To show the test result intuitively, we draw a Confusion Matrix:
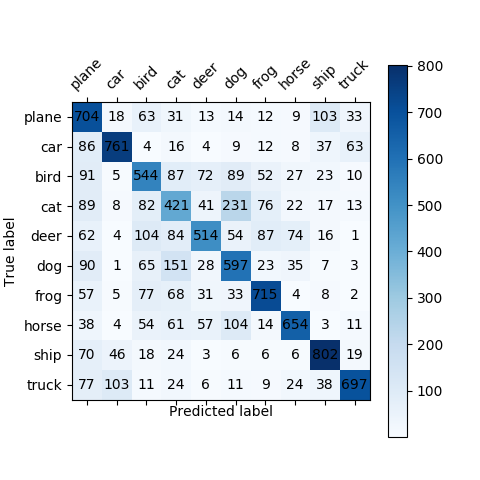
-
As the epoch of train increase, the loss on training set and Acc on test set as follows:
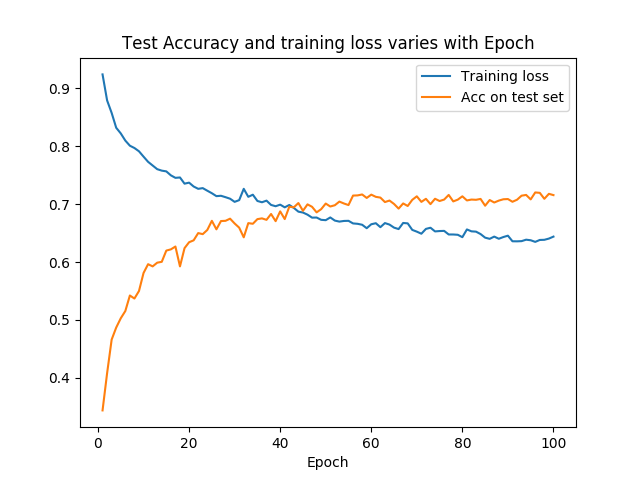
-
Changing learning rate in training process, the final test result(Acc) on test set as follows:
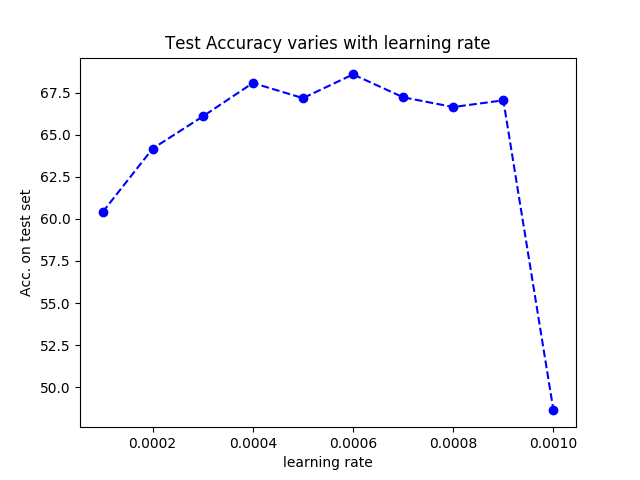
Of course, they are trained during same epochs. From the figure we suggest that the learning rate should be less than 0.008.
-
Finally, we change the method of model regularization: use both Batch Normalization and Dropout, only use Batch Normalization, only use Dropout, and use nothing. Here is the result:
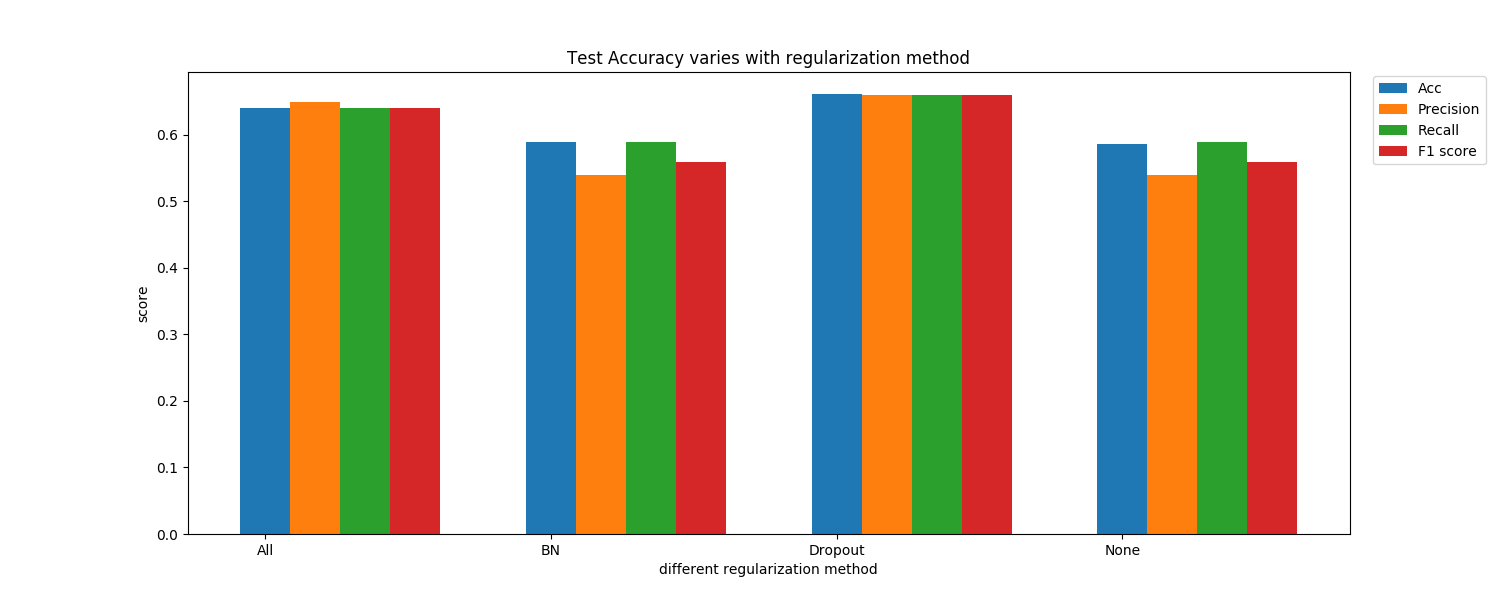
We can see that Dropout is more important for improving model performance than Batch Normalization in our project since there is almost no difference on Acc between whether to use Batch Normalization.




Modify src/model.py
python src/train.py --task_id 1 --epoch 30 --lr 0.0003 --device cuda:0 >>src/tasks/task-1/output.logThis project is licensed under the MIT License - see the LICENSE file for details
- PyTorch Tutorials
- Jie Song VIPA