This project aimed to be a fall detection and alert system based on machine-learning capabilities. Its concept aimed to be a simple alternative to the attachment of physical devices and sensors on elderly patients with high tendancy of falling and causing harm to themselves.
While exisiting hardware has remained as a reliable solution in the market, not all medical centres or households are able to afford it for all their patients who need it, and not all patients are medically fit to have such devices around them or attached to them, such as those suffering from dementia with inabilities of voicing out any form of discomfort or pain.
-
Mediapipe Pose library is first used to get the coordinates of different points on a body captured within a video input. The following image shows the Pose Landmark Model taken from Mediapipe docs.
Pose Landmark Model used to identify the coordinates throughout a subject's body.
-
All 33 coordinates are then fed into my prediction model to determine whether our subject is in a fallen state or not.
- Although 33 coordinates are taken in as our input data, our tensor shape takes in 99 input values since each coordinate has x, y and z values.
What is displayed when a subject falls:
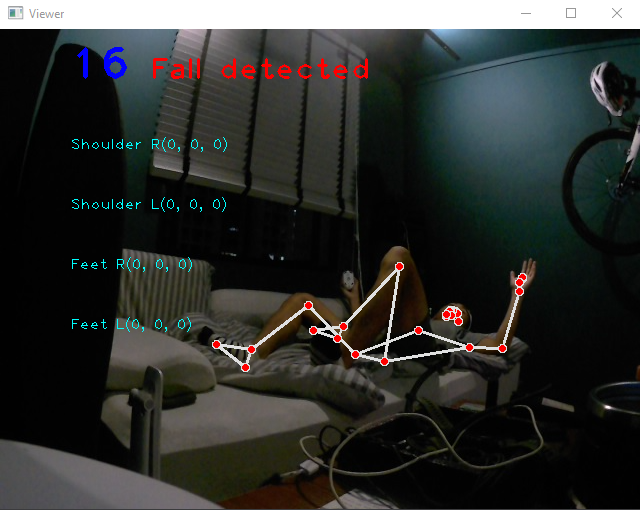
What is displayed when a subject has not fallen:
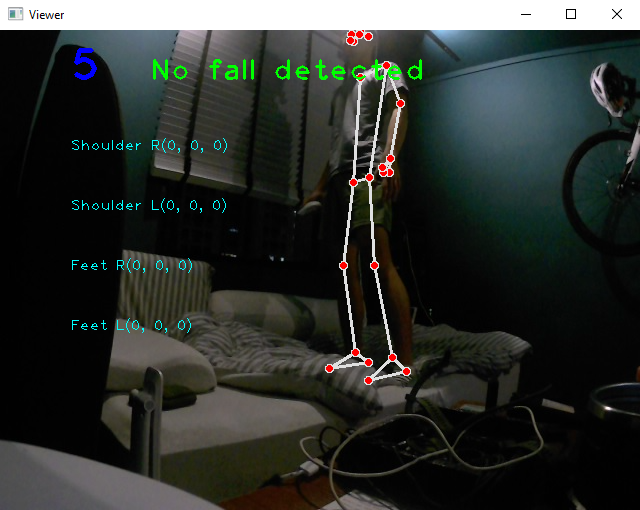
-
The third component is in development where our recepients would be notified should a fall be detected in a live video feed.


When we retrieve a summary of our fall prediction model, we get the following information:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 99) 9900
dense_1 (Dense) (None, 128) 12800
dense_2 (Dense) (None, 2) 258
=================================================================
Total params: 22,958
Trainable params: 22,958
Non-trainable params: 0
_________________________________________________________________
As mentioned above, the 99 input features are the xyz coordinates of each of our 33 identified points on our Pose Landmark model. Thus, that determines our input layer with its given shape.
As we proceed to the second layer, Sigmoid will be used as our activation function as we require our output for our final layer to be between 0 and 1, as a form of probability for each of our possible outputs (fall or no fall).

Activation functions in neural networks explained here
For our final layer, we give it a size of 2, for each of the possible outcomes, whether our subject has fallen or not. Using Numpy, we get the feature with the highest score, which also tells us the output we are looking for.
The dataset was trained with two videos, one with myself maneuvering between possible postures after a patient would have fallen on the ground, as well as another one casually walking or bending over, where no fall would have been detected.
A maximum of 5000 frames were extracted from each video and fed into our Mediapipe Pose detection to retrieve its Pose Landmark values, before being compiled into a bytes file (dataset.bytes). This dataset was then used to build and train our neural network.
- Add code that allows users to be notified of a detected fall, as well as a snapshot of the frame with the predicted fall. This can be acheived through existing open-source APIs such as Discord.