- Roba da portare / Todo prima dell'esame
- Da controllare alla fine
- Prima Parte
- Seconda Parte
- Extra stuff
- Pubblica su GitHub tutti i progetti che vuoi controllare durante l'esame e pinnali nella homepage
- ❗ USB con:
- Materiale TDP e appunti (progetti, laboratori, slides, appunti! (time handling!!!) e tutto quello che vuoi)
- File TXT con password Polito, password GitHub, e chiave SSH GitHub (seleziona repo!!!)
- ❗ Cellulare con password Polito e password GitHub + Autenticatore a 2 fattori etc.
- ❗ Carta e penna
- Fai un backup dell'USB su WhatsAppWeb per recuperare i dati in caso di necessità
- Prima dell'esame, apri una pagina di Google Chrome in modalità incognito e apri
- WhatsApp Web
- Phind
- Pagina Web Ufficiale di TdP
- GitHub
- GitHub Classroom
- Assicurati di aver definito
hashCodeeequalsin ogni java bean - Pulisci il grafo ogni volta che fai clic sul pulsante "Crea grafo"
- Pulisci i dati relativi a Simulatore e Ricorsione ogni volta che premi il pulsante "Simula" o "Avvia ricorsione"
- Pulisci dati dentro il
Modele iText Field / Inputnel Controller se devono essere puliti durante l'esecuzione - Controlla possibili errori di input nel Controller e trova modi per rompere il tuo codice (:exclamation:vedi a fine punto 1)
- Controlla attentamente che le informazioni estratte dal DB siano quelle corrette
- Controlla attentamente di utilizzare il tipo di dato giusto durante il recupero dei dati dal dao (double, int, String, LocalDateTime, ...)
- Usa
try (Connection conn = ...)o ❗chiudiconnalla fine di ogni bloccotry - Dopo ogni esame/simulazione elimina le chiavi github che potrebbero essere memorizzate in eclipse o altrove!
Note
⚡ Non preoccuparti se la complessità degli algoritmi per generare una soluzione richiesta all'esame è alta, ai professori basta che funzioni. La seconda parte dell'esame non sarà valutata (solo) sulla base dei semplici output che il tuo algoritmo fa ma anche sulla logica che hai implementato, se per esempio il tuo algoritmo ricorsivo "esplode" facilmente non farti prendere dal panico, sarà lecito lo stesso e verrà valutato solo se ci sono delle vere e proprie fallacie logiche!
| ❗ Ogni volta che aggiorni il modello implementa subito i nuovi metodi nel Controller e testali! Pensa immediatamente a gestire gli errori di input ❗ |
|---|
Here is a simple list of usual things that could break your code:
- Inserting wrong type of data as input (int instead of a char or double instead of an int)
- Inserting data with spaces before, after or in between itself (" 69", "420 ", ...) as input
- Inserting nothing ("") as input
- Inserting data below a lower bound (e.g. negative numbers, lookout for limits in data range in the DB!)
- Inserting data above an upper bound (e.g. really large numbers, lookout for limits in data range in the DB!)
- Clicking buttons two or more times when each time data is not reseted (e.g. click two times "Make Graph" will load double vertex, edges, ...)
- Clicking some buttons when other have not already been clicked (e.g. click "Find shortest path" when the user didnt already click "Make graph") - Hint: Use
javafx.obj.setDisable(false | true)
private Graph<?,?> graph;
private List<Node> allNodes;
private Dao dao;
private Map<Integer, Node> idMap; // Only if necessary!
public Model() {
graph = new Graph<>(Edge.class);
allNodes = new ArrayList<>();
dao = new Dao();
idMap = new HashMap<>();
//...; // lazy
}
private void loadNodes() {
// Se o la mappa, o la lista, sono vuote (anche solo una delle due) allora
// significa che si è verificato un errore nel caricamento di tali dati dal DB
// dunque è meglio ricaricare tutto da capo
if (this.allNodes.isEmpty() || this.idMap.isEmpty()){
this.allNodes = this.dao.getAllNodes;
for (Node n : this.allNodes) this.idMap.put(n.getId(), n);
System.out.println("> Caricati tutti i NODI sulla LISTA" + allNodes.size() + " e MAPPA " + nodeIdMap.keySet().size());
dao.updateNodes(idMap)
System.out.println("> Aggiornati i nodi");
}
}
public void buildGraph() {
// Clean the graph if necessary
if (graph.vertexSet().size() > 0) graph = new SimpleGraph<>(DefaultEdge.class);
loadNodes();
Graphs.addAllVertices(graph, allNodes);
System.out.println("> Caricati i NODI nei vertici del grafo: " + graph.vertexSet().size());
//TODO load Edges
}| ❗ Considera che se il grafo che dovrai creare sarà molto "denso" di archi (ovvero il grafo è quasi completamente connesso) allora cercare tutti gli archi con SQL potrebbe richiedere tanto tempo e risorse quanto costruirsi ogni arco direttamente in java con una serie di inner-for, in casi del genere quindi meglio usare questa seconda opzione! |
|---|
- Watch out for Double Couples and Self Couples! --> If the graph is oriented, weighted or do not alow self-loop this could broke your code!
- Do not make super-hard queries, in case it happens ask teachers!
- Make sure to work on the right tables and data
- Check that both on java and on sql you get the right cardinality of the collection (Collection.size() and the number of rows in HeidiSQL must coincide)
Watch out for self-loops and double-pairs!
SELECT s1.Retailer_code AS s1, s2.Retailer_code AS s2, COUNT(DISTINCT s1.Product_number) AS m
FROM go_daily_sales s1, go_daily_sales s2
WHERE s1.Retailer_code IN (SELECT Retailer_code FROM go_retailers WHERE Country = "Germany")
AND s2.Retailer_code IN (SELECT Retailer_code FROM go_retailers WHERE Country = "Germany")
AND YEAR(s1.Date) = 2016
AND YEAR(s2.Date) = 2016
AND s1.Retailer_code < s2.Retailer_code -- Double pair (and thus, self-loops) avoided :)
AND s1.Product_number = s2.Product_number
GROUP BY s1.Retailer_code, s2.Retailer_code
HAVING m >= 10SELECT s1.playerID, s2.playerID, s1.teamID, s1.teamCode
FROM salaries s1, salaries s2
WHERE s1.teamID = s2.teamID
AND s1.playerID <> s2.playerID -- Self-loop avoided :)Note
⚡ Double pair are automaticaly avoided if you use an undirected graph, but if possible avoid them directly in your query/dao to make a cleaner code!
💡 Consider that the jGraphT library provieds a pre-made Edge auxiliary class called Pair, NOTA BENE:exclamation: Pair distingue tra (a, b) e (b, a)
/*
* try(...){} si chiama "try-with-resources",
* è un tipo di comando try aggiunto in java 7 che chiude
* automaticamente l'oggetto dichiarato al suo interno una volta che il
* blocco try è terminato (utilizzando il suo relativo metodo .close()),
* è una soluzione più solida e sicura di chiamare il comando .close() manualmente
* in quanto, anche se viene lanciato un errore o eccezione, tale oggetto verrà chiuso lo stesso
*
* Nota: try-w-resources funziona solo se la classe dell'ogetto che viene richiamato dentro le parentesi
* implementa l'interfaccia AutoCloasble: Connection infatti la implementa come è visibile nella documentazione ufficiale di java disponibile qui sotto
*
* try-w-resources: https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html
* Connection implementa AutoClosable: https://docs.oracle.com/javase/8/docs/api/java/sql/Connection.html
* Utente StackOverflow che spiega il funzionamento di try-w-resources: https://stackoverflow.com/questions/10115282/new-strange-java-try-syntax#answers
*
* try-with-resources NON equivale a
try {
// Stuff...
} finally {
conn.close();
}
* try-with-resources è più sicuro!
* come specificato nella stessa documentazione di java
* disponibile qui: https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html#:~:text=However%2C%20this%20example,your%20program%27s%20resources.
*/public void Collection<Stuff> loadStuff(Map<Integer, Node> idMap, ...) {
String sql = "SELECT s.playerID "
+ "FROM salaries s "
+ "WHERE s.`year` = ? "
+ "AND s.salary > ?";
// N.B. conn viene chiuso automaticamente in un try-with-resources in quanto implementa l'interfaccia AutoClosable,
// si veda il commento multi-linea sopra per una spiegazione più dettagliata di try-with-resources
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html
try (Connection conn = DBConnect.getConnection();) {
PreparedStatement st = conn.prepareStatement(sql);
st.setInt(1, ...);
ResultSet rs = st.executeQuery();
List<People> result = new ArrayList<People>();
while (rs.next()) {
Node n = idMap.get(rs.getString("playerID"));
result.add(n);
}
return result;
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("*** ERROR Connection Database ***");
}
}public void Collection<NodePair> loadEdges(Map<Integer, Node> idMap, ...) {
String sql = "SELECT g1.playerID g1, g2.playerID g2 "
+ "FROM appearances g1, appearances g2 "
+ "WHERE g1.teamID = g2.teamID "
+ "AND g1.`year` = g2.`year` "
+ "AND g1.`year` = ? "
+ "AND g1.playerID <> g2.playerID"; // Watch out for Self-Loops and Double-Pairs!
// N.B. conn viene chiuso automaticamente in un try-with-resources in quanto implementa l'interfaccia AutoClosable,
// si veda il commento multi-linea sopra per una spiegazione più dettagliata di try-with-resources
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html
try (Connection conn = DBConnect.getConnection();) {
PreparedStatement st = conn.prepareStatement(sql);
st.setInt(1, ...);
ResultSet rs = st.executeQuery();
List<NodePair> result = new ArrayList<>();
while(rs.next()) {
Node n1 = idMap.get(rs.getInt("g1"));
Node n2 = idMap.get(rs.getInt("g2"));;
NodePair np = new NodePair(n1, n2);
result.add(np);
}
return result;
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("*** ERROR Connection Database ***");
}
}❗ Remember to define hashCode and equals (and eventually compareTo) in each new Java Bean you define, just in case |
|---|
If you want to make two pairs containing one (a, b) and the second (b, a) to look the same from equals() and hashCode() perspective consider the following options:
-
Before saving the pair into the object, sort them in the constructor
public NodePair(Node a, Node b) { super(); if (a.compareTo(B) > 0) { //or Integer.compareTo(a.getID(), b.getID()) this.a = a; this.b = b; } else { this.a = b; this.b = a; } }
-
Use specifc
equals()andhashCode()methods@Override public int hashCode() { // https://stackoverflow.com/questions/1536393/good-hash-function-for-permutations // XOR [ a.hashCode() ^ b.hashCode() ] , // or SUM [ a.hashCode() + b.hashCode() ] , // or MULTIPLY [ a.hashCode() * b.hashCode() ] // or use abc's propose: hashNumbe = SUM[ R + 2*i ] / 2 // where R is a arbitrary odd number > 1 and i is a generic element of the set return (abc(a.hashCode()) + abc(b.hashCode()) / 2); } private double abc(int a) { int R = 1779033703; return R + 2*a; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; NodePair other = (NodePair) obj; return ( Objects.equals(a, other.a) && Objects.equals(b, other.b) ) || ( Objects.equals(a, other.b) && Objects.equals(b, other.a) ); }
If instead you just need a simple NodePair class use the following standard Java Bean (or the jGraphT Pair class)
public class NodePair { Node a; Node b; public NodePair(People a, People b) { super(); this.a = a; this.b = b; } public NodePair getA() { return a; } public NodePair getB() { return b; } @Override public int hashCode() { return Objects.hash(a, b); } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; NodePair other = (NodePair) obj; return Objects.equals(a, other.a) && Objects.equals(b, other.b); } @Override public String toString() { return "NodePair [a=" + a + ", b=" + b + "]"; } }
void buildGraph() {
// Clean the graph if necessary
if (graph.vertexSet().size() > 0) graph = new SimpleGraph<>(DefaultEdge.class);
loadNodes();
Graphs.addAllVertices(Graph, allNodes);
System.out.println("> Caricati i NODI nei VERTICI del grafo: " + graph.vertexSet().size());
// Load Edges
for (NodePair p : dao.getNodePairs(..., idMap)) {
Node n1 = p.getNode1();
Node n2 = p.getNode2();
//if (!graph.containsVertex(n1)) graph.addVertex(n1);
//if (!graph.containsVertex(n2)) graph.addVertex(n2);
graph.addEdge(n1, n2);
}
System.out.println("> Caricati gli ARCHI del grafo: " + graph.edgeSet().size()); //
}5. Implement logical operation on graphs (DepthFirstIterator, BreadthFirst, ConnectivityInspector, ...)
// Sample DepthFirstIterator | BreadthFirst manual implementation
DepthFirstIterator<Node, DefaultEdge> iterator =
new DepthFirstIterator<>(graph, rootNode);
List<Node> result = new ArrayList<>();
while (iterator.hasNext()) result.add(iterator.next());
return result;// Sample findPath algorithm using a BreadthFirstIterator
public findPath(Node source, Node sink) {
BreadthFirstIterator<Node, DefaultEdge> iterator =
new BreadthFirstIterator<>(graph, source);
List<Node> reachableNodes = new ArrayList<>();
while (iterator.hasNext()) {
Node n = iterator.next();
reachableNodes.add(n);
}
List<Node> path = new ArrayList<>();
Node currentNode = sink;
percorso.add(sink);
DefaultEdge e = iterator.getSpanningTreeEdge(currentNode);
while (e != null) {
Node befNode = Graphs.getOppositeVertex(graph, e, currentNode);
// Add at index 0 in order to don't have a list backwards
path.add(0, befNode);
currentNode = befNode;
e = iterator.getSpanningTreeEdge(currentNode);
}
}// Sample ConnectivityInspector implementation
ConnectivityInspector<Node, DefaultEdge> inspector = new ConnectivityInspector<>(graph);
return new ArrayList<>(inspector.connectedSetOf(rootNode));Model -> getAllPeople, getIdMap, getGraph, ...
Make model unmutable and do not make getter for stuff you dont want to show, use private keywords for certain methods as well
// Schema from teachers
/*
*** NOTA BENE!! ***
Ciclare su un SET non è come ciclare su una LIST,
attento che se cicli su un set potrebbero crearsi, a ogni livello ricorsivo,
dei cicli che non rispettano l'ordine corretto!
Consider using HashSet and their sets' operations in your code to improve computational speed. The use of `HashSet` in your code depends on the requirements of your algorithm and the characteristics of the data you're working with. Here are a few points to consider:
1. **Duplicate checking:** If you need to check for duplicates frequently, a `HashSet` could provide a performance improvement because it offers O(1) complexity for the `contains` operation, while an `ArrayList` offers O(n) complexity. However, in your current pseudocode, I don't see a need for such operation.
2. **Order of elements:** If the order of the elements is important for your algorithm (for instance, in the `best` list), then you should stick with `ArrayList` or other types of `List`, as `HashSet` doesn't maintain the order of elements. If order is not important and you need to eliminate duplicates, a `HashSet` can be a good choice.
3. **Filtering operation:** The `filter` function could potentially benefit from a `HashSet`. If you're checking whether an element exists in the `partial` list, a `HashSet` would offer better performance.
4. **Memory usage:** `HashSet` takes more memory than `ArrayList` because it needs to maintain a separate data structure (a hash table) to provide constant-time performance.
5. **No .get() method:** `Set` do not provide a .get() method to find a certain object in the set.
In conclusion, you need to consider these factors based on the specific characteristics of your problem and data. The use of `HashSet` can be an improvement in some cases, but it could also be a disadvantage depending on your needs. Always consider the trade-offs before deciding.
*/
/*
Rispondere alle seguenti domande:
- Cosa rappresenta il "livello" nel mio algoritmo ricorsivo?
- Com'è fatta una soluzione parziale?
- Come faccio a riconoscere se una soluzione parziale è anche completa?
- Data una soluzione parziale, come faccio a sapere se è valida o se non è valida? (nb. magari non posso)
- Data una soluzione completa, come faccio a sapere se è valida o se non è valida?
- Qual è la regola per generare tutte le soluzioni del livello+1 a partire da una soluzione parziale del livello corrente?
- Qual è la struttura dati per memorizzare una soluzione (parziale o completa)?
- Qual è la struttura dati per memorizzare lo stato della ricerca (della ricorsione)?
*/
// New Attributes, add these in the top section of the model class
private List<Node> best; // The current best solution
private double bestNumber; // A number that represents the goodness of the solution, faster that using data structures with methods
private int limit; // Level limit
// Setup
public List<Node> start(int limit) {
this.best = new ArrayList<>();
this.bestNumber = 0;
this.limit = limit;
List<Node> partial = new ArrayList<>();
// Se possibile prova anche a non effettuare una ricorsione
// su tutta la collezione che devi analizzare, potrebbe
// risultare più vantaggioso spezzetare tale collezione
// nelle sue componenti e unire i risultati della ricorsione
// su queste
recursive(partial);
return this.best;
}
// Recursive algorithm
public void recursive(List<Node> partial, Set<Node> candidates) {
// Ultimo nodo inserito, utile se devi fare dei controlli
// Node cursor = partial.get(partial.size()-1);
// Comandi da fare sempre, molto raro
// doAlways();
// Condizione di terminazione
// if (something > limit) return;
// Controllo della migliore soluzione
double currentNumber = calcNumber(partial);
if (isComplete(current) && currentNumber > bestNumber) {
best = new ArrayList<>(partial);
bestNumber = currentNumber;
}
// *** NOTA BENE!! *** Ciclare su un SET non è come ciclare su una LIST, attento che se cicli su un set potrebbero crearsi, a ogni livello ricorsivo, dei cicli che non rispettano l'ordine corretto!
List<Node> actualCandidates = clean(candidates); // Pulisci i nodi su cui ciclare prima di iniziare il for, se possibile, considera di usare i set
// Ricorsione
for (Node n : actualCandidates) {
// Filtro in entrata
if (filter(partial, n)) {
partial.add(n);
// Maybe instantiating a new ArrayList<>(partial) could be a good option?
// Note: Instantiating a new list at each step can be memory intensive if your recursion depth is large.
// If partial doesn't need to be immutable across recursive calls, it would be more efficient to
// avoid new instantiations and reuse the list as you're currently doing.
recursive(partial);
// Backtracking
partial.remove(partial.size()-1); // Keep in mind that this will only work if partial has not been shuffled before!
}
}
}
// Filters and controls
public void doAlways() {
//TODO
}
public boolean isComplete(List<Node> partial) {
//TODO
return true;
}
public List<Node> clean(List<Node> nodes) {
//TODO
return null;
}
public double calcNumber(List<Node> partial) {
//TODO
return 0.0; //placeholder return
}
public boolean filter(List<Node> partial, Node n) {
//TODO
return true; //placeholder return
}// Personal Schema
public class Simulator {
// Input data
InputData in;
// WIP data
WIPData wip
// Costraints (usually default data)
Costraint c; //DEFINE THE DEFAULT IN THE CONSTRUCTOR!
// LocalDateTime-linke costraints (usually default data)
LocalDate simStart; //DEFINE THE DEFAULT IN THE CONSTRUCTOR!
LocalDate simStop; //DEFINE THE DEFAULT IN THE CONSTRUCTOR!
// Output data
OutputData out;
// Queue of Events
Queue<Event> queue;
public Simulator(InputData inputData, ...) {
super();
// Set inputs
this.inputData = inputData;
// Set default data (WIP, costraints, outputs, ...)
this.defaultData // = ...;
// Build the queue
this.queue = new PriorityQueue<>();
}
// Setters for default data
public void setDefaultData() {
// TODO
}
// Getters for output data
public OutputData getOutputData() {
// TODO
}
public void init() {
for (int time = 0; time < maxTime; time++) { // or use LocalDateTime with SimStart, SimStop
//Define event type
EventType type = DEFAULT_TYPE;
if (Math.random() <= probabilty) {
type = ALT_TYPE;
}
// Define event data
Data eData; // = ...
// Define event
Event e = new Event(time, type, eData);
queue.add(e);
}
}
public void run() {
while (!queue.isEmpty()) {
// Poll an event
Event e = queue.poll();
// Extracts Time, Type and EventData
LocalDate time = e.getTime();
EventType type = e.getType();
int eData = e.geteData;
// Debug Event
System.out.println(e);
// Handle event
switch (type) {
case DEFAULT_TYPE:
processDefaultEvent(e); // Update Outputdata!
break;
case ALT_TYPE:
processAltEvent(e); // Update Outputdata!
break;
default:
throw new RuntimeException("**ERRORE** -- Evento " + type + " non riconosciuto");
}
}
}
public void processEvent(Event e) {
//TODO ...
}
}public class Event implements Comparable<Event>{
LocalDate time;
EventType type;
EventData eData;
public Event(LocalDate time, EventType type, EventData eData) {
super();
this.time = time;
this.type = type;
this.eData = eData;
}
public LocalDate getTime() {
return time;
}
public EventType getType() {
return type;
}
public int geteData() {
return eData;
}
@Override
public int compareTo(Event o) {
return this.getTime().compareTo(o.getTime());
}
@Override
public String toString() {
return "Event [time=" + time + ", type=" + type + ", eData=" + eData + "]";
}
}public enum EventType {
DEFAULT_TYPE,
ALT_TYPE
// ...
}// Retrive number from txtField
int x;
try {
x = Integer.parseInt(txtX.getText().strip());
} catch (NumberFormatException e) {
txtResult.setText("Imposta x!");
return;
}
if (x <= 0) {
txtResult.setText("Inserisci un numero positivo!");
return;
}// Retrive object from combo box
Node n = cmbN.getValue();
if (n == null) {
txtResult.setText("Scegli un nodo!");
return;
}// Basic build graph command
model.buildGraph(n);
this.txtResult.appendText("Vertici: " + model.getVertexSetSize() + "\nArchi: " + model.getEdgeSetSize() + "\n");| SQL | JDBC: java.sql | Model: java.time |
|---|---|---|
DATE |
Date (sub of java.util.Date) |
LocalDate |
DATETIME |
Timestamp (sub of java.util.Date) |
LocalDateTime |
TIMESTAMP (mySQL only) |
❌ | ❌ |
Note You can convert from java.sql to java.time with
.toLocalDate()method
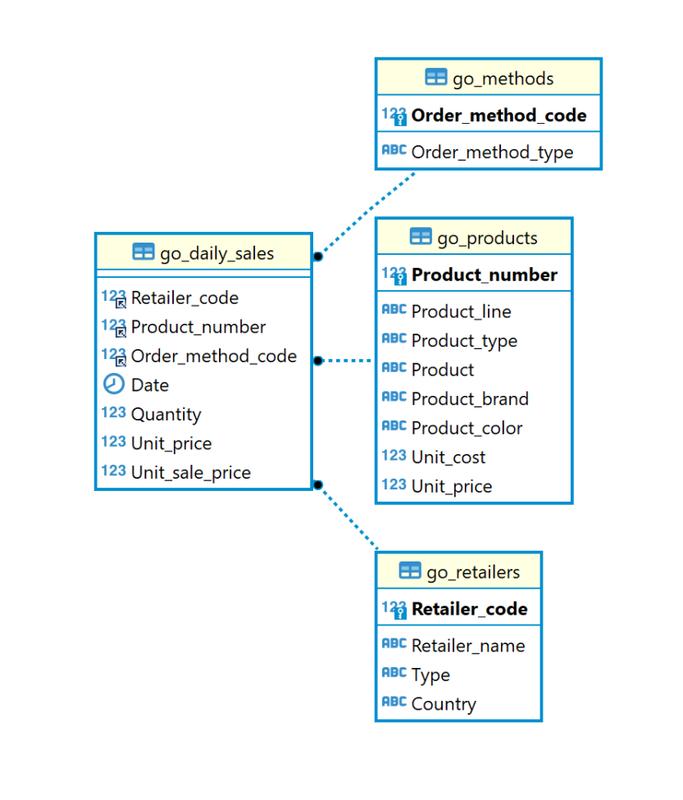

- In uno stesso anno, un giocatore potrebbe essere stato stipendiato da due squadre diverse
- In uno stesso anno, un giocatore potrebbe aver giocato in due squadre diverse (conseguenza diretta della precedente)
- appearances sono le partite giocate da un giocatore, per una certa squadra, in un anno; salaries sono le paghe annuali di ogni giocatore
- Possono esistere giocatori panchinari: sono stipendiati (in salaries) ma non hanno giocato (no in appearances)
- appearances ha solo giocatori con almeno un gioco effettuato (colonna
games), non esistono giocatori in appearances congames=0 - ❓ [DA VERIFICARE] qual'è la differenza tra la colonna
divIDediv_IDnella tabella teams? - ❓ [DA VERIFICARE] Esistono prestiti di giocatori da una squadra ad un altra? (In tal caso se si presta un panchinaro ad una squadra che lo fa giocare questo sarà stipendiato solo dalla squadra originale ma avrà appearances solo nella seconda squadra...?)
- ❓ [DA VERIFICARE] i manager gestiscono solo player, solo squadre, o possono entrambi in contemporanea? Possono gestire un giocatore e una squadra la quale non comprende il giocatore? Le vincite e le perdite dei manager sono riferite alla squadra o al giocatore?
-
COUNT(DISTINCT ...)è diverso daCOUNT(...) -
Usa
>o<per avere coppie uniche -
Per calcolare delle medie puoi anche usare
SUMeCOUNTinvece diAVG -
Per non sporcare il codice con troppi join puoi usare anche
IN (SELECT ... FROM ...) -
Se vuoi avere la lunghezza di un
ResultSetprova conResultSet.last(); return ResultSet.getRow();
-
Esistono varie utilità per gestire le date in MariaDB
-
NOW(): Returns the current date and time. -
CURDATE(),CURRENT_DATE(): Returns the current date. -
CURTIME(),CURRENT_TIME(): Returns the current time. -
DATE(): Extracts the date part of a date or datetime expression. -
TIME(): Extracts the time part of a date or datetime expression. -
YEAR(),MONTH(),DAY(): Extracts the year, month, or day from a date or datetime expression. -
HOUR(),MINUTE(),SECOND(): Extracts the hour, minute, or second from a time or datetime expression. -
DATEDIFF(): Returns the number of days between two dates. -
TIMEDIFF(): Returns the time difference between two times. -
DATE_ADD(),DATE_SUB(): Adds or subtracts a specified time interval from a date. -
STR_TO_DATE(): Converts a string to a date. -
DATE_FORMAT(): Formats a date as a string. -
UNIX_TIMESTAMP(): Converts a date or datetime expression to Unix timestamp. -
FROM_UNIXTIME(): Converts Unix timestamp to a date or datetime. -
DAYOFWEEK(): Returns the weekday index for a date (1 = Sunday, 2 = Monday, …, 7 = Saturday). -
DAYOFYEAR(): Returns the day of the year for a date. -
WEEK(): Returns the week number for a date. -
QUARTER(): Returns the quarter of the year for a date. -
EXTRACT(): Extracts a part of a date. -
PERIOD_ADD(),PERIOD_DIFF(): Adds or subtracts a specified number of months to a period format (YYMM or YYYYMM). -
SYSDATE(): Returns the time at which the function executes.
-
-
Se vuoi usare le regex in SQL prova con
LIKEUse the
LIKEoperator in aWHEREclause, usually with the%wildcard. The%symbol in theLIKEstatement is used to represent any number of characters (including zero characters). For example:SELECT column1, column2, ... FROM table_name WHERE columnN LIKE pattern;
Here are a few examples of how you can use
LIKE:-
Find any values that start with "A":
SELECT * FROM table_name WHERE column_name LIKE 'A%';
-
Find any values that end with "A":
SELECT * FROM table_name WHERE column_name LIKE '%A';
-
Find any values that have "or" in any position:
SELECT * FROM table_name WHERE column_name LIKE '%or%';
-
Find any values that start with "A" and are at least 2 characters in length:
SELECT * FROM table_name WHERE column_name LIKE 'A_%';
-
Find any values that start with "A" and ends with "o":
SELECT * FROM table_name WHERE column_name LIKE 'A%o';
Note that SQL is case-insensitive, meaning
LIKE 'a%'andLIKE 'A%'would return the same results. However, some SQL databases like PostgreSQL are case-sensitive. If you are using a case-sensitive database, you can use theILIKEoperator instead ofLIKEto do a case-insensitive search.There is also the
_wildcard which represents a single character.Remember, if you want to include literal percentage (%) or underscore (_) characters in the search pattern, you must escape them with the escape character. The default escape character is the backslash (). If you want to define a different escape character, you can do so with the
ESCAPEclause. Here is an example:SELECT column1, column2, ... FROM table_name WHERE columnN LIKE '%\_a\_%' ESCAPE '\';
In this example, SQL will match any string that contains
_a_.
-
Here are some notable classes and methods that you might find useful:
-
asSomething: This is a collections of classes that provides some useful "conversions" of a graph in something elese:
Certainly, I'll give a brief description of each method and provide code examples. Note that these examples are assuming that you've already defined your
Graphobject.-
asGraphUnion: Creates a new graph that is the union of multiple graphs. In the resulting graph, the vertex set is the disjoint union of the vertex sets of all graphs, and the edge set is the disjoint union of all edges sets of all graphs.
Graph<String, DefaultEdge> graph1 = new DefaultDirectedGraph<>(DefaultEdge.class); Graph<String, DefaultEdge> graph2 = new DefaultDirectedGraph<>(DefaultEdge.class); Graph<String, DefaultEdge> union = new AsGraphUnion<>(graph1, graph2);
-
asMaskSubgraph: This returns a live view of the subgraph of
ginduced by the vertices and edges that are unmasked by the vertexMask and edgeMask. If a vertex/edge is masked, it means that it is effectively removed from the subgraph.Graph<String, DefaultEdge> graph = new DefaultDirectedGraph<>(DefaultEdge.class); Graph<String, DefaultEdge> maskedSubgraph = new AsMaskSubgraph<>(graph, v -> v.equals("something"), e -> e.equals("something"));
-
asUndirectedGraph: This returns an undirected view of the specified graph.
DirectedGraph<String, DefaultEdge> directedGraph = new DefaultDirectedGraph<>(DefaultEdge.class); Graph<String, DefaultEdge> undirectedGraph = new AsUndirectedGraph<>(directedGraph);
-
asDirectedGraph: This returns a directed view of the specified undirected graph.
Graph<String, DefaultEdge> undirectedGraph = new DefaultUndirectedGraph<>(DefaultEdge.class); DirectedGraph<String, DefaultEdge> directedGraph = new AsDirectedGraph<>(undirectedGraph);
-
asUnmodifiableGraph: This returns an unmodifiable view of the specified graph.
Graph<String, DefaultEdge> graph = new DefaultDirectedGraph<>(DefaultEdge.class); Graph<String, DefaultEdge> unmodifiableGraph = new AsUnmodifiableGraph<>(graph);
-
asWeightedGraph: This returns a weighted view of the specified graph.
Graph<String, DefaultEdge> graph = new DefaultDirectedGraph<>(DefaultEdge.class); WeightedGraph<String, DefaultEdge> weightedGraph = new AsWeightedGraph<>(graph, new HashMap<>());
-
asSubgraph: This returns a view on the graph as a subgraph specified by a subset of vertices and/or edges.
Graph<String, DefaultEdge> graph = new DefaultDirectedGraph<>(DefaultEdge.class); Set<String> vertexSubset = new HashSet<>(Arrays.asList("vertex1", "vertex2")); Graph<String, DefaultEdge> subgraph = new AsSubgraph<>(graph, vertexSubset);
-
asSpannerGraph: This returns a spanner graph view of the specified graph, using a specific spanner algorithm.
Graph<String, DefaultEdge> graph = new DefaultDirectedGraph<>(DefaultEdge.class); SpannerAlgorithm<DefaultEdge> algo = new GreedyMultiplicativeSpanner<>(graph); SpannerGraph<String, DefaultEdge> spannerGraph = new AsSpannerGraph<>(graph, algo.getSpanner());
Please remember to add the necessary import statements depending on which classes you use, and make sure to create and populate your graphs before using these methods. This is just an illustrative example and may not run correctly without additional context.
-
-
GraphPath: This represents a path in a graph. It doesn't have methods for modifying the graph, but it does have methods for querying the path such as
getEdgeList(),getVertexList(),getWeight(), etc. -
ConnectivityInspector: This class helps in checking the connectivity of a graph.
isGraphConnected(): Checks if the entire graph is connected.
-
DepthFirstIterator: This is an iterator for traversing the graph in depth-first order. You initialize it with a graph and a starting vertex, then call
next()to get the next vertex in the depth-first sequence. -
BreadthFirstIterator: Similar to
DepthFirstIterator, but for breadth-first traversal. -
FloydWarshallShortestPaths: This class implements the Floyd-Warshall algorithm for finding all pairs shortest paths.
shortestDistance(sourceVertex, targetVertex): This method returns the shortest path from sourceVertex to targetVertex.
-
DijkstraShortestPath: This class implements Dijkstra's shortest path algorithm.
findPathBetween(graph, startVertex, endVertex): Finds the shortest path between startVertex and endVertex using Dijkstra's algorithm.
-
BellmanFordShortestPath: is an implementation of the Bellman-Ford algorithm, which computes the shortest paths from a source vertex to all other vertices in a weighted graph, even when some of the edge weights are negative. It can also detect negative cycles.
-
getPath: ThegetPath(V sink)method returns the shortest path from the source vertex to the sink vertex. -
getPathEdgeList: ThegetPathEdgeList(V sink)method returns the edges making up the shortest path from the source vertex to the sink vertex. -
getCost: ThegetCost(V sink)method returns the cost of the shortest path from the source vertex to the sink vertex. -
getPaths: ThegetPaths(V sink)method returns a list of all shortest paths from the source vertex to the sink vertex.
-
-
BellmanFordInspector: If you suspect that your graph might contain negative cycles and you want to check for their presence, you can use the
BellmanFordInspectorclass provided by the jGraphT library. This class allows you to detect negative cycles in a graph. Here's an example of how you might use it:Graph<Integer, DefaultWeightedEdge> graph = new SimpleDirectedWeightedGraph<>(DefaultWeightedEdge.class); // populate your graph here... BellmanFordInspector<Integer, DefaultWeightedEdge> inspector = new BellmanFordInspector<>(graph); boolean hasNegativeCycle = inspector.hasNegativeCycle(); if (hasNegativeCycle) { System.out.println("Graph contains a negative weight cycle"); Set<DefaultWeightedEdge> negativeCycle = inspector.getNegativeCycle(); // handle the negative cycle... } else { System.out.println("Graph does not contain a negative weight cycle"); }
In this example,
hasNegativeCycle()checks if there's a negative cycle in the graph, andgetNegativeCycle()returns one such cycle if it exists. The returned cycle is represented as a set ofDefaultWeightedEdgeobjects, and you can further examine these edges if needed. Note thatgetNegativeCycle()returns null if there's no negative cycle in the graph.Remember that the
BellmanFordInspectorclass assumes that the graph is a simple directed graph and the edge weights are numbers. If these assumptions don't hold for your graph, you might need to use a different algorithm or modify the graph accordingly. -
KruskalMinimumSpanningTree: This class represents a minimum spanning tree/forest of a graph. It uses Kruskal's algorithm.
getEdgeSet(): This method returns a set of edges included in a minimum spanning tree.
-
GraphMetrics: GraphMetrics is a utility class that provides various methods to compute different metrics of a graph. Here are its key methods:
-
getDiameter(Graph<V, E> graph): Computes and returns the diameter of the graph. The diameter is the maximum eccentricity of any vertex. -
getRadius(Graph<V, E> graph): Computes and returns the radius of the graph. The radius is the minimum eccentricity of any vertex. -
getEccentricity(Graph<V, E> graph, V vertex): Computes and returns the eccentricity of a specified vertex. The eccentricity of a vertex is defined as the maximum shortest path length to any other vertex. -
getGirth(Graph<V, E> graph): Computes and returns the girth of the graph. The girth is the length of the shortest cycle contained in the graph.
-
-
CycleDetector: This class uses depth-first search to detect cycles in a graph. Here are its key methods:
-
CycleDetector(Graph<V, E> graph): Constructs a cycle detector for a specified graph. -
detectCycles(): Detects if the graph contains a cycle. Returns true if the graph contains at least one cycle, and false otherwise. -
findCycles(): Finds and returns a set of all vertices which participate in any cycle. -
findCyclesContainingVertex(V v): Finds and returns a set of all vertices that can be reached by starting from the specified vertex and following a cycle.
-
Remember, these are just a few of the methods and classes available in the jGraphT library. For a comprehensive overview of all functionalities, refer to the official jGraphT API documentation.
Java's Set interface doesn't directly provide methods for set operations such as union, intersection, or difference. However, we can perform these operations by using methods from the Set interface and java.util.Collections class, and also from Java 8's Stream API. Here are some examples:
-
Union - The union of two sets is a new set that contains all the elements from both sets.
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set<Integer> set2 = new HashSet<>(Arrays.asList(3, 4, 5)); // Union Set<Integer> union = new HashSet<>(set1); union.addAll(set2);
-
Intersection - The intersection of two sets is a new set that contains only the elements that are in both sets.
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set<Integer> set2 = new HashSet<>(Arrays.asList(3, 4, 5)); // Intersection Set<Integer> intersection = new HashSet<>(set1); intersection.retainAll(set2);
-
Difference (Subtraction) - The difference of two sets is a new set that contains elements in the first set but not in the second.
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set<Integer> set2 = new HashSet<>(Arrays.asList(3, 4, 5)); // Difference Set<Integer> difference = new HashSet<>(set1); difference.removeAll(set2);
-
Symmetric Difference - The symmetric difference of two sets is a new set that contains elements that are in one of the sets, but not in their intersection.
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set<Integer> set2 = new HashSet<>(Arrays.asList(3, 4, 5)); // Symmetric Difference Set<Integer> difference1 = new HashSet<>(set1); difference1.removeAll(set2); Set<Integer> difference2 = new HashSet<>(set2); difference2.removeAll(set1); Set<Integer> symmetricDifference = new HashSet<>(difference1); symmetricDifference.addAll(difference2);
-
Subset - To check if a set is a subset of another (i.e., all elements of the first set are in the second set), you can use the
containsAll()method.Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set<Integer> set2 = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5)); // Subset boolean isSubset = set2.containsAll(set1);
Remember, in set operations, the resulting sets do not contain duplicate elements, because the Set interface in Java doesn't allow duplicates.