A scraper & information retrieval system utilizing an inverted index.

- Abstract
- Project Overview
- Design
- Architecture
- Operation
- Conclusion
- Data Sources
- Test Cases
- Source Code
- Bibliography
This project contains a processor and two utilities (crawler and indexer) for building and hosting an information retrieval system. The goal is to crawl specified wikipedia pages and build an inverted index that can then be served to the end user as a search engine. The processor is powered by Flask and hosts a static webpage that the end user can interact with to make search queries. A REST API is also exposed for returning the search results in JSON format.
The utilities for building the inverted index should be able to be called through the CLI and require no other tools or programs to use. As such, all utilities were designed to use the argparse library to simplify the process for handling arguments. Each of the components should logically integrate with each other to build the inverted index.
- Crawler: Specify web sources (wikipedia pages) to scrape. The crawler should build a file that the indexer can parse.
- Indexer: Open crawler build file and create an inverted index and output it to the local directory.
- Processor: Open indexed file and host a webpage for searching through the index.
At the end of the workflow, only the processor should need to be running to handle incoming requests. The index should have already been built with the crawler and indexer.
The following guidelines were created for the project:
- The crawler must be able to handle multiple URLs at once.
- The crawler must be able to have the depth and max pages variables assigned from the CLI.
- All files between components must use a common format (json, xml) in place of a more efficient binary format. This is for readability / expandability of the system.
- The indexer should display the current status of building large indexes. (logs, progress bar, etc.)
- A web interface must be exposed for the end user to interact with the search engine.
- A REST API must be exposed for returning the direct search results.
- The processor must have an argument for defining the target index file.
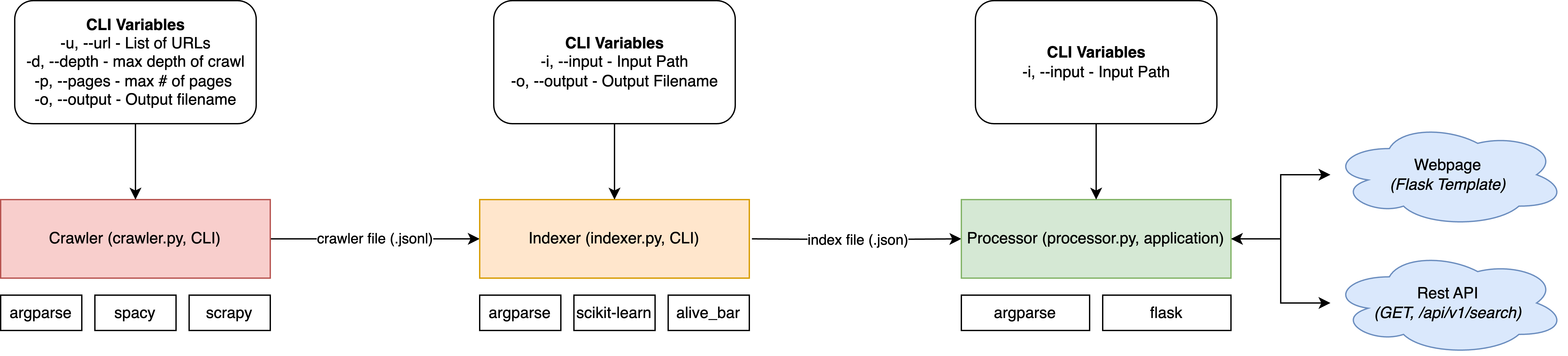
The architecture is composed of three major components:
- Crawler
2. Based on
scrapylibrary 3. Implementsspacyto remove stop words from compiled results - Indexer
4. Based on
scikit-learnlibrary - Processor
6. Based on
flasklibrary 7. Implements user interface & REST API
The web interface is exposed on the root (/) of the web server. By default, the port of the processor is 8080. It has been adjusted from the default due to conflicts with a service on newer releases of MacOS.

A REST API is exposed at /api/v1/search to get the raw search results. In order to use the API, a query parameter must be appended to specify the search term.
Example: GET http://127.0.0.1:8080/api/v1/search?query=test
Response:
{
"path": "/api/v1/search",
"result": [
[
"https://en.wikipedia.org/wiki/Wind_tunnel",
0.09704187380027539
],
[
"https://en.wikipedia.org/wiki/Postgraduate_education",
0.030624801076030946
],
[
"https://en.wikipedia.org/wiki/Baja_SAE",
0.027980221968710767
],
[
"https://en.wikipedia.org/wiki/Mini_Baja",
0.027884019899316846
],
[
"https://en.wikipedia.org/wiki/SAE_J300",
0.025263906320942754
],
[
"https://en.wikipedia.org/wiki/SAE_304_stainless_steel",
0.024212789038846882
],
[
"https://en.wikipedia.org/wiki/SAE_J306",
0.022958469350262595
],
[
"https://en.wikipedia.org/wiki/SAE_J2452",
0.018041012695770336
],
[
"https://en.wikipedia.org/wiki/Limited_liability_company",
0.017562143073061882
],
[
"https://en.wikipedia.org/wiki/Sardar_Vallabhbhai_National_Institute_of_Technology",
0.016896694891923778
]
],
"status": "success",
"statusCode": "200",
"timestamp": "Tue, 23 Apr 2024 00:07:14 GMT"
}- Run
pip install -r requirements.txtto install the required packages. - Run
python -m spacy download en_core_web_smto manually install the stop word package.
pip and python with pip3 and python3 in certain installations.
This example will create a new crawler file for the topic of Formula SAE race cars. The source will come from two wikipedia pages. Note: This file has been pre-generated and is available at data/crawler/formula.jsonl.
python crawler.py -u https://en.wikipedia.org/wiki/Formula_Hybrid,https://en.wikipedia.org/wiki/Formula_SAE -o formula.jsonl This example will run the indexer using the file generated from the crawler example above.
python indexer.py -i data/crawler/formula.jsonl -o formula.jsonThis example will start the processor using the file built with the indexer.
python processor.py -i data/indexer/formula.json The system does work cohesively to create an inverse index and a web interface for querying the index. A few issues are apparent from testing that can be improved upon:
- Querying with two terms (bigrams) doesn't work as a pair. This isn't a bug but was not taken into consideration for the original design.
- The crawler was designed to primarily crawl wikipedia pages. As such, it wasn't tested as much against other types of pages. While it should work fine, results may be unexpected.
- There are a lot of improvements that can be made at the indexer side to build a stronger / more cohesive index. This goes along with issue #1 with optimizing for bigrams.
The web interface works well and the REST API returns the proper data. In a future iteration, more metadata including scrape timestamp and page name should be included with the index for more detailed results.
In the examples above, the wikipedia pages for Formula SAE and Formula Hybrid were used to build a index.
The compiled data has been uploaded to the repo:
- Crawler Compiled Result: formula.jsonl
- Indexer Compiled Result: formula.json
Test cases were written for the crawler and indexer components using the unittest library from Python. The test cases are documented in the source code, but involve testing and mocking various aspects of the functions to ensure the proper data and calls are being made. To run test cases:
- Run
python -m unittest crawler.py - Run
python -m unittest indexer.py
“Argparse - Parser for Command-Line Options, Arguments and Sub-Commands.” Python documentation. Accessed April 23, 2024. https://docs.python.org/3/library/argparse.html.
C., James “Mocking a Method Outside of a Class.” Stack Overflow, December 1, 1960. https://stackoverflow.com/questions/29018025/mocking-a-method-outside-of-a-class.
“Check If a Key/Value Exists in a Dictionary in Python.” nkmk note. Accessed April 23, 2024. https://note.nkmk.me/en/python-dict-in-values-items/.
Dyouri, Abdelhadi. “How to Use Templates in a Flask Application.” DigitalOcean, September 13, 2021. https://www.digitalocean.com/community/tutorials/how-to-use-templates-in-a-flask-application.
Francois T. “How to Use Mock.ANY with Assert_called_with.” Stack Overflow, July 1, 1961. https://stackoverflow.com/questions/33214247/how-to-use-mock-any-with-assert-called-with.
MBTMBT “Loading JSONL File as JSON Objects.” Stack Overflow, February 1, 1964. https://stackoverflow.com/questions/50475635/loading-jsonl-file-as-json-objects.
Reza Mousavi “How to Remove Stop Words and Lemmatize at the Same Time When Using Spacy?” Stack Overflow, March 1, 1967. https://stackoverflow.com/questions/68010465/how-to-remove-stop-words-and-lemmatize-at-the-same-time-when-using-spacy.
Toleo “How to Prevent Duplicates on Scrapy Fetching Depending on an Existing JSON List.” Stack Overflow, April 1, 1964. https://stackoverflow.com/questions/51225781/how-to-prevent-duplicates-on-scrapy-fetching-depending-on-an-existing-json-list.
“Unittest - Unit Testing Framework.” Python documentation. Accessed April 23, 2024. https://docs.python.org/3/library/unittest.html.
“Unittest.Mock - Mock Object Library.” Python documentation. Accessed April 23, 2024. https://docs.python.org/3/library/unittest.mock.html.