This is the PyTorch implementation of our ROLL model for VideoQA. ROLL has been recently published at ECCV 2020. Find the technical paper here.
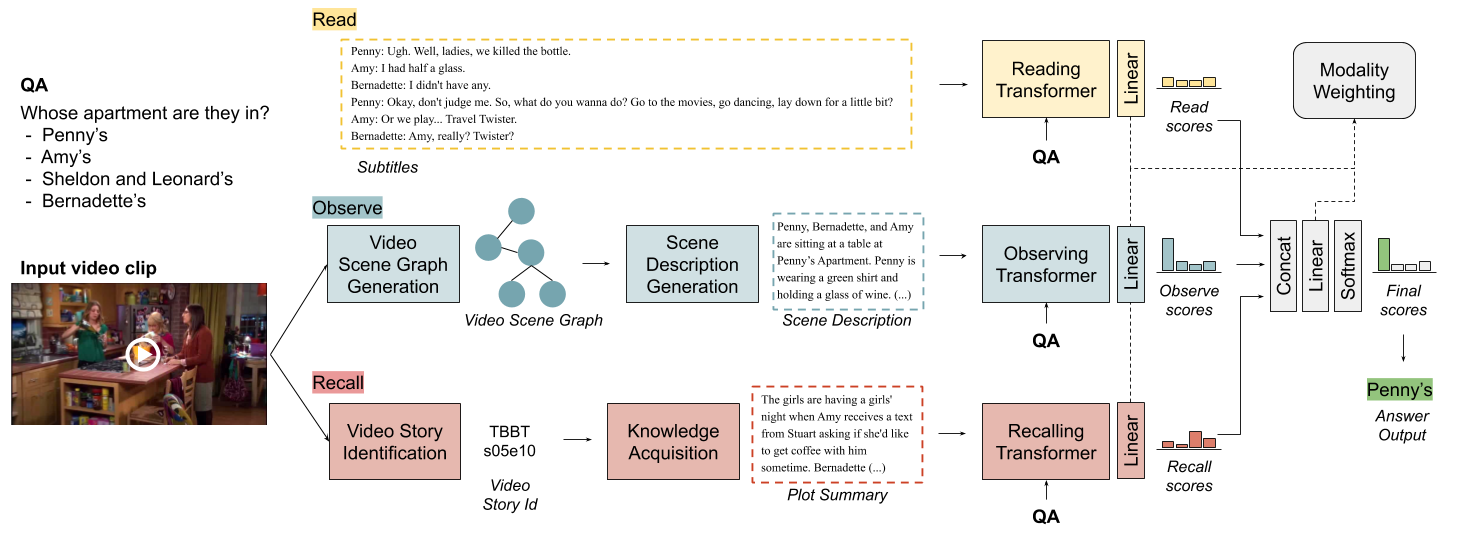
ROLL consists on three branches, each performing a different inspired-cognitive task:
- Read branch: Dialog comprehension.
- Observe branch: Visual scene reasoning.
- Recall branch: Storyline recalling.
The information generated by each branch is encoded via Transformers. A modality weighting mechanism balances the output from the different modalities to predict the final answer.
This code runs on Python 3.6 and PyTorch 1.0.1. We recommend using Anaconda to install the dependencies.
conda create --name roll-videoqa python=3.6
conda activate roll-videoqa
conda install -c anaconda numpy pandas scikit-learn
conda install -c conda-forge visdom tqdm
conda install pytorch==1.0.1 torchvision==0.2.2 -c pytorch
pip install pytorch-transformers
- Dependencies: NumPy, pandas, PyTorch 1.0.1, torchvision, PyTorch-Transformers, scikit-learn, tqdm, and Visdom.
- Optional: Beautiful Soup to download episode summaries (already provided).
For data preparation, follow instructions in DATA.md.
- Start Visdom Server. To visualize the training plots, first start the Visdom server:
python -m visdom.server. Plots can be found by visitinghttp://localhost:8097in a browser. - Pretrain branches. The three branches (read, observe, recall) are first pretrained independently:
# Read branch training using the subtitles python Source/branch_read.py --dataset knowit # Recall branch training using the video summaries python Source/branch_recall.py --dataset knowit # For the observe branch, the video descriptions need to be computed first. # The descriptions will be at Data/knowit_observe/scenes_descriptions.csv python Source/generate_scene_description.py knowit # Observe branch training using the generated descriptions python Source/branch_observe.py --dataset knowit - Multimodality fusion. The outputs from the branches are fused and the network is trained one last time using the modality weighting mechanism.
python Source/fuse_branches.py --dataset knowit
TODO.
If you find this code useful, please cite our work:
@InProceedings{garcia2020knowledge,
author = {Noa Garcia and Yuta Nakashima},
title = {Knowledge-Based Video Question Answering with Unsupervised Scene Descriptions},
booktitle = {Proceedings of the European Conference on Computer Vision},
year = {2020},
}
@InProceedings{garcia2020knowit,
author = {Noa Garcia and Mayu Otani and Chenhui Chu and Yuta Nakashima},
title = {KnowIT VQA: Answering Knowledge-Based Questions about Videos},
booktitle = {Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence},
year = {2020},
}
- TVQA+ code