Google search results scrapper and parser
Caterpillar fetches results from google and finds if any of the links have the same domain that one you are interested in. If any such links exits, it shows their ranking (where it appears in the search results).
node index.js keywords="keywords" url="domain-to-look-for"
Example:
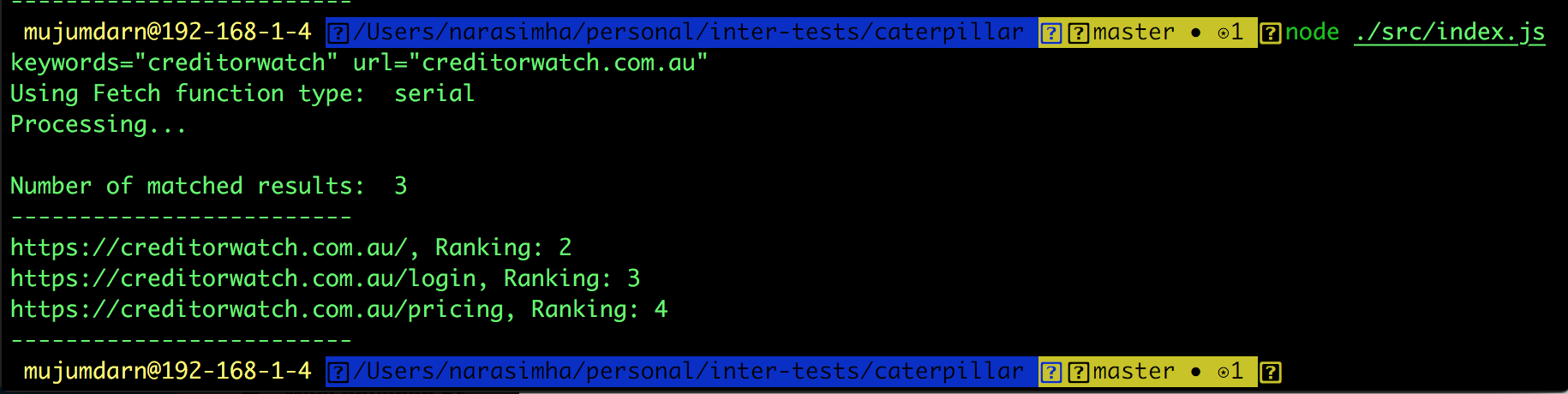
The program looks for links with the same `domain` as that of the url provided as input argument. It then outputs the links that did meet this criterion and the rankinf of the links in google search results.
Another example:
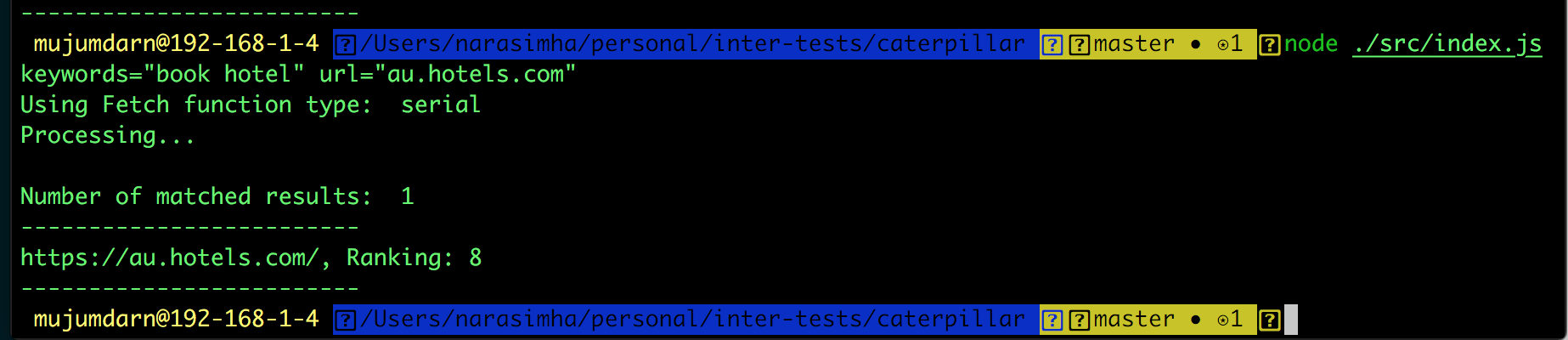
I have tried to follow a functional and event driven approach.
The program is flexible and granular so that it can be easily extended to do something else with the search results as well. (We just have to add more listeners (details below)).
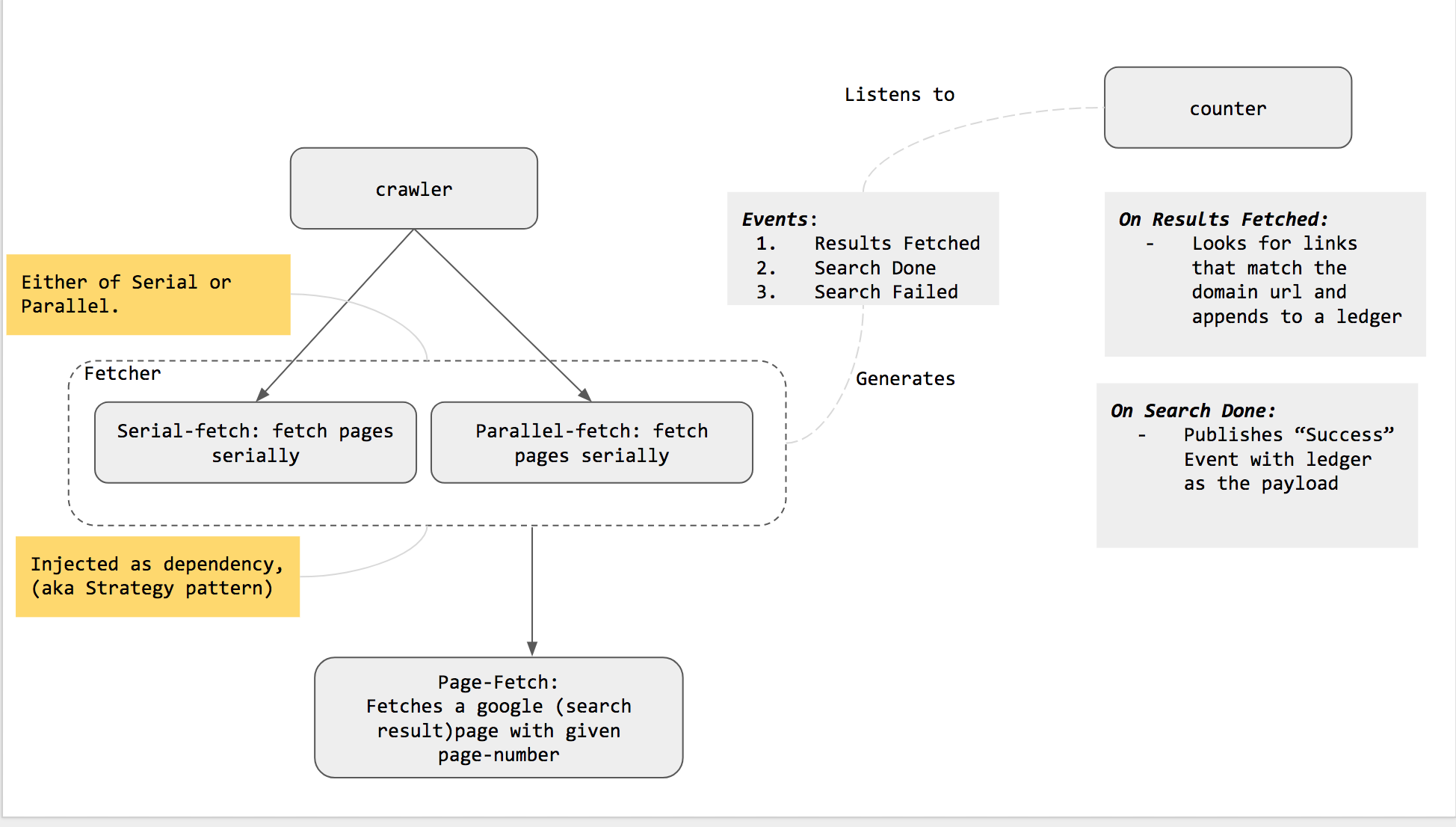
Crawler is responsible for crawling the pages. It sets up an event-emitter that can be used by potential listeners for events: ResultsFetched, SearchDone and SearchFailed.
It uses a dependency that is injected into it to fetch the pages. This depedency is implemented by two components: serial-fetch and parallel-fetch.
Serial-fetch fetches the search results pages one after the another (Probably the better as this might avoid getting the IP blocked).
Parallel-fetch fetches the search results parallely.
Both these fetches use a common component page-fetch to fetch a single search result page.
Whether the program uses serial or parallel fetch function is determined by the configuration (config.json): For Serial:
{
"fetch-function-type": "serial"
}
For Parallel:
{
"fetch-function-type": "parallel"
}
link-counter/counter is responsible for determining if any of the search results contain the domain you are interested in.
It compares the domain name part of the url you are interested in with the domain name part of the links in search results.
The link-counter/counter component listens to ResultsFetched, SearchDone and SearchFailed events from crawler and in turn publishes "Success" (or "Failed") event once it is done computing the results (or if it fails - in case of search error).
The program runs unit tests using chain, mocha, sinon.
The program uses "cheerio" to parse the html body of the search results. Cheerio loads the html and converts it a dom. It does not do any JS exection. It just loads the dom to make it easy to search the elements.
Ideally a regular expressions based search would be more performant. I faced some issues in parsing the body using regex and hence the use of cheerio. As one of the next steps it would be better to use regex to parse the body instead of using cheerio.
All though it takes a lot less to parse the body as compared to fetching the response, using regular expression to parse the body would possibly an improvement.
